I Just Want To Get My Code Into Production…Operations Can Be Your Best Friend
Bugs? What bugs? My code doesn’t have any stinkin’ bugs!! Of course the testers may have a little different view than the developers. Hundred’s of developers furiously writing code and they all want to hit their release date. Operations also wants to make sure that the scheduled releases go off without a hitch, on time, on schedule and with no problems. To aid in this endeavour, MSCOM Ops tries to provide information and operational guidance very early in the SDLC process. We try to get information out in lots of formats; webcasts, TechNet Magazine articles, customer visits, conference calls and conference presentations…oh yeah and this blog!!
{kind=link}
We also have recently published three white papers in partnership with Microsoft IT: Showcase. They are:
Microsoft IT Showcase: Microsoft.com Moves to x64 Version of Windows
Technical White Paper
Microsoft IT Showcase: Microsoft.com Server Configurations
Note to IT
Microsoft IT Showcase: Monitoring and Troubleshooting Microsoft.com
Technical Case Study
It does seem that folks read these (that’s a good thing!) because we got the following feedback from a customer in the UK:
“I and my customer were really interested in the Monitoring and Troubleshooting Microsoft.com (https://www.microsoft.com/technet/itsolutions/msit/operations/mscomtroubleshoot.mspx) studies that have just been published. I have some additional questions that I need to follow up on and wondered if you could direct me to the appropriate person?
Specifically, the customer would like more information on how new or updated applications are tested in the ms.com environment prior to going live. When there are 600 devs submitting code and content what processes are in place to ensure that resource hogs are eliminated before they get to production, and how is that testing conducted?”
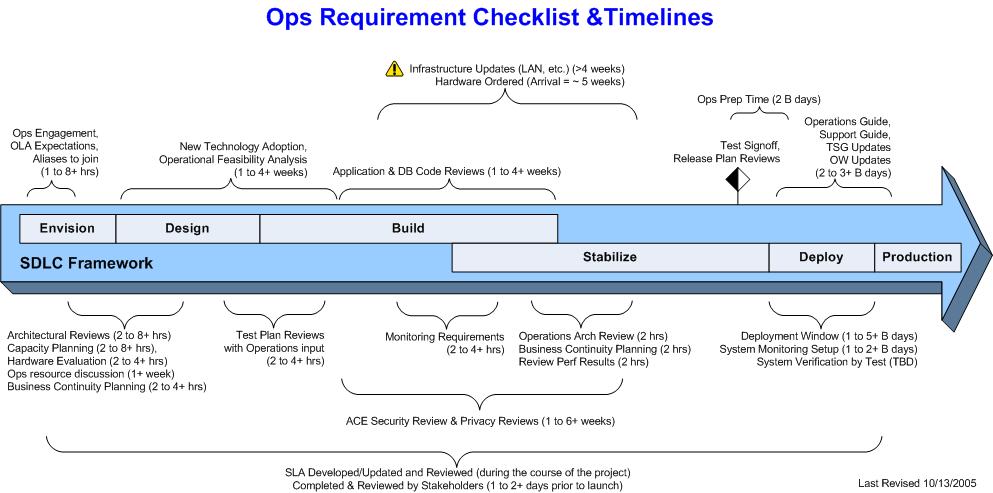
What a great question! Microsoft.com Operations in a lot of ways strongly resembles an ISP hosting model. We are primarily responsible for the server infrastructure that the wide variety of applications that we support run on. Each group that provides code for us to install typically goes through the classic Software Development Life Cycle (SDLC). The timing in which MSCOM OPS interacts with that process goes something like this:
- Envision: The Business Unit comes up with an idea which typically is a business problem/need that will be addressed by code. The Program Managers write the specs, the Dev and Test teams take those specs and cost the project out, which means they estimate how many resources it will take to write and test the code. There typically are discussions surrounding what stays in the project and what gets cut, and the final result of these negotiations is what constitutes the “project”. Very early in this process MSCOM Ops Application Hosting team members and Systems Engineers are available and get involved in answering any questions that the project group may. Typical questions would be where the new code should live, what the infrastructure looks like, is there existing capacity or will there need to be new hardware built out.
- Design: This phase is where the specs are signed off and the Dev team is then responsible for writing the code. Ops is available to continue consulting on capacity planning, hardware evaluations and other questions that Dev may have. This is where Ops starts the initial Architectural Review process. We want to start to get specific information to know where the code will live, what it is intended to do, what dependencies that is has (web services, SQL back end, specific web permissions etc.) and most importantly what will be actually going on the servers. Typical sorts of questions that we would ask:
· Are there assemblies that need to be put in the GAC?
· What will we need to touch the in machine.config file?
· Is the application managed code?
· Have they properly instrumented the code so that Ops can provide relevant monitoring?
· What does the application directory structure look like?
· What app pool will it live in?
· What are the anticipated traffic patterns?
· We would also ensure that the Dev team knows exactly what our platform specifics are: O/S version, IIS version, and all the various components, MDAC versions, Framework version etc. Toward the end of the design phase, Test (again the Product Group that is providing the code) will begin to develop the test plans again with in put from Ops.
Test will begin to design test plans during the latter part of this phase, once there is the some sort of a code base to work with.
- Build: This is when Test starts to really get involved in testing the code to resolve any functional or performance issues (know as bugs). Since there is now a code base to work from, OPS will perform both an initial application as well as database code reviews. We are primarily looking to ensure that any coding standards that we have developed and provided are being followed. These have evolved over time and continue to evolve as we adopt new technologies. We also look to ensure that monitoring requirements have been addressed.
- Stabilize: As the code progresses and starts to get stable, i.e. the bug count begins to decrease, OPS does a final formal Architectural Review to identify any changes that may have resulted from the Dev/Test cycle. By this time we also will have any performance test results. If these perf results are not within our expected tolerances we will report that back to the Product team to get these resolved. Toward the end of the Stabilize phase we work with the Release Management team to review the release plan. The release plan typically is the step by step blueprint for getting the final bits into production. The release plan usually includes everything from which SE or DBA will be doing which step to where the “golden” bits (that will have received formal Test sign off) are located, to what the timing should be for release to Pre-production, Staging and finally Production. The end of Stabilize is marked by formal Test sign off and Ops Sign off of the release plan.
- Deploy: This is where the golden bits get propped to the servers. A typical release involves propping the code to a non-live Pre-production environment. This is a representation of the live Production environment with the exception that it is not internet facing, and it does not use the live SQL backend or production Passport, and it typically consists of a single server as opposed to a cluster. After the bits are rolled out to this environment, Test and PM from the Product Group have to sign off on a functional smoke test to make sure that the code functions as planned. This initial release into Pre-prod provides Ops its first chance to actually deploy the bits using the release plan. If changes need to be made we will work with the RM team to ensure that updates are made. After all involved are satisfied that the release to Pre-prod was successful, we then do essentially the same steps for the Staging Environment. Staging is a mirror of Production, but again not internet facing. After this is completed Ops has had the experience of going through the release plan twice and is usually very comfortable with the procedures. The goal of all of this prep work is to do everything possible to ensure that the actual release into production goes a smoothly as possible. Ops also has the responsibility during this phase to ensure that the Operations Guide, a doc that explains the application, what it does, where it lives, including a logical and physical architectural diagram, has been completed. We are also on the hook to ensure that a Trouble Shooting Guide (TSG) is generated. This is a living document that is used by Tier I and Tier II support folks to perform initial incident resolution or escalation should the need arise.
There are different SDLC methodologies followed by the various product development groups hosting their services, tools and applications within the MSCOM Ops managed environments. These include Waterfall and Scrum.
Waterfall is the classic serial development methodology where downstream deliverables and tasks such as development or testing are dependent on the completion of upstream deliverables and tasks such as a functional spec, code complete and a complete install and configuration guide for test and release management to utilize when deploying into the various environments.
Agile is basically multiple waterfall iterations in one development lifecycle and the iterations occur in the design, build and stabilize phases. They both contain the same standard SDLC milestones of Envision, Design, Build, Stabilize, Deploy, Production, Adoption etc…To learn more about these methodologies see https://msdn.microsoft.com/vstudio/teamsystem/msf/. Regardless of the methodology being followed, the requirements for hosting an application or service within the MSCOM Ops managed environments remain the same, as well as the SDLC mandatory controls which ensure Sarbanes Oxley (SOX) compliance. The various Release Management teams supporting the various product development groups that deploy to the MSCOM Ops managed environments have developed checklists a.k.a. Responsible, Accountable, Consult and Inform (RACI) matrix for both the Waterfall and Scrum methodologies to help drive early agreements in the production dev cycle and hold disciplines and individuals accountable for the delivery or task that they have been assigned during the envision phase of the project. (Get these checklists from the Download Center, these are two word docs in a winzip file.) This oversight governance by release management ensures project compliance with all Ops, Release Management and SDLC mandatory control compliance allowing the Program managers to accurately cost and schedule each deliverable and task into the overall project schedule, vastly reducing 11th hour surprises, churn on Operations and potential blocking issues to release.
Does every release that we do follow this process? No, not every one, there are and will continue to be exceptions. Does following this process ensure a smooth release and a stable and performant application every time? Again no, but since we started following this process, the amount of churn on Operations has decreased, and has become much more predictable. The amount of out of band releases; hotfixes (which are defined as a single bug fix) and what we call service packs (which are defined as multiple bug fixes bundled into a single deployment package) has decreased as well.