Saving Snow Leopards with Deep Learning and Computer Vision on Spark
This post is authored by Mark Hamilton, Software Engineer at Microsoft, Rhetick Sengupta, President of Snow Leopard Trust, and Principal Program Manager at Microsoft, and Roope Astala, Senior Program Manager at Microsoft.
The Snow Leopard – A Highly Endangered Animal
Snow leopards are highly endangered animals that inhabit high-altitude steppes and mountainous terrain in Asia and Central Asia. There's only an estimated 3900-6500 individuals left in the wild. Due the cats' remote habitat, expansive range and extremely elusive nature, they have proven quite hard to study. Very little is therefore known about their ecology, range, survival rates and movement patterns. To truly understand the snow leopard and influence its survival rates more directly, lots more data is needed. Biologists have set up motion-sensitive camera traps in snow leopard territory in an attempt to gain a better understanding of these animals. In fact, over the years, these cameras have produced over 1 million images, and these images are used to understand the leopard population, range and other behaviors. This information, in turn, can be used to establish new protected areas as well as improve the many community-based conservation efforts administered by the Snow Leopard Trust.
However, the problem with camera trap data is that the biologists must sort through all the images to specially identify those with snow leopards or their prey as opposed to those images which have neither. Doing this sort of classification manually is very time-consuming and takes around 300 hours per camera survey. To solve this problem, the Snow Leopard Trust and Microsoft agreed to partner with each other. Working with the Azure Machine Learning team, the Snow Leopard Trust built an image classification model that uses deep neural networks at scale on Spark.
This blog post discusses the successes and learnings from our collaboration.

Image Analysis Using Microsoft Machine Learning for Apache Spark
Convolutional neural networks (CNNs) are today's state of the art statistical models for image analysis. They are used in everything from driverless cars, facial recognition systems, and image search engines. To build our model, we used Microsoft Machine Learning for Apache Spark (MMLSpark), which provides easy-to-use APIs for many different kinds of deep learning models, including CNNs from the Microsoft Cognitive Toolkit (CNTK). Furthermore, MMLSpark provided capabilities for scalable image loading and preprocessing to build end-to-end image analysis workflows as SparkML pipelines.
Our model uses two key machine learning techniques: Transfer Learning and Ensembling and Dataset Augmentation
Transfer Learning: Instead of training a CNN model from scratch, we used a technique called transfer learning. In this technique, we used a network, namely ResNet, that had been pre-trained against generic images, and that has learned to hierarchically recognize different levels of structures from the image. We used output from the final layers of the network as high-order features. These features were then used to train a "traditional" SparkML logistic regression classifier to specifically detect snow leopards. Note that the DNN featurization is an "embarrassingly" parallel task that scales up with the number of Spark executors, and can therefore be easily used for very large image datasets. You can find a generic example of transfer learning using MMLSpark at our GitHub repository.
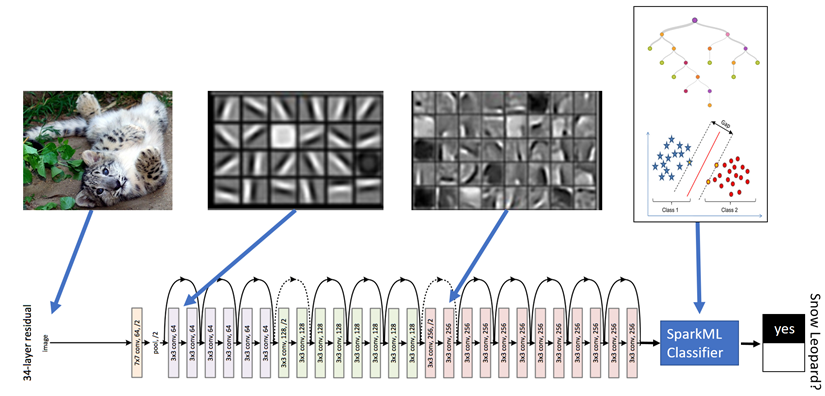
Ensembling and Dataset Augmentation: The second key part of our model involves "ensembling" or averaging the predictions of our model across multiple images. Often, when a snow leopard roams near a camera, she will trigger the camera to fire several times creating a sequence of images. This provides us with several different shots of the same leopard. If the network can classify most of these shots correctly, we can use the correct majority to override the incorrect predictions in the sequence, dramatically reducing the error on hard-to-classify shots. We also augmented the dataset by flipping each image horizontally to double our training data, which helped the network learn a more robust snow leopard identifier. We discovered that both additions significantly improved accuracy.
Results
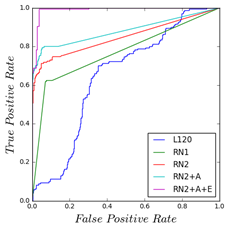
We compared several different models:
- L120: No DNN featurization, plain logistic regression against the image scaled down to 120x120 pixels.
- RN1: Using the next-to-last layer of the ResNet50 neural network as featurizer, and logistic regression as classifier.
- RN2: Using the second-to-last layer of the ResNet50 neural network as featurizer, and logistic regression as classifier.
- RN2+A: Using the RN2 setup with a dataset augmented with horizontally flipped images.
- RN2+ A + E: Using RN2+A but grouping the images into sequences of camera shots and averaging the predictions over these groups.
The results for each model are shown below, from left to right.

The most basic model without transfer learning or ensembling gets 63.4% on the test dataset, only slightly better than random guessing. The first big improvement in performance comes from using transfer learning which brings the results up to 83% accuracy. Cutting more layers off the net and augmenting the dataset helps a bit bringing the model to 89.5% accuracy. Finally averaging over the sequence of images brings us to 90% and dramatically improves our ROC curve, almost eliminating false positives entirely as seen in image below.
To summarize, using the knowledge contained in a pre-trained deep learning model allowed us to effectively automate snow leopard classification. This will greatly help the Trust's conservation efforts by saving hundreds of hours of manual work and allowing the biologists to concentrate on more impactful scientific and conservation efforts. By using image processing tools and pre-trained DNN models from MMLSpark, we could easily build the image classification workflow, and process large volumes of images effectively. As the workflow consists of SparkML pipelines it is straightforward to deploy to production for use in future surveys. We have also laid the groundwork for future image analyses, as this workflow can easily be adapted to other image classification tasks.
Microsoft has been working for some time to bring the power of AI and the cloud to organizations and individuals who are working to improve, protect and preserve our planet and the species that live upon it. Projects like this one help advance our understanding of how these tools can be used across a wide range of ecological and environmental applications, and we're looking forward to sharing more information about this work in coming months.
You can read more about Snow Leopard Trust here, and about the Microsoft Machine Learning Library for Apache Spark here.
Mark, Rhetick & Roope
Apache®, Apache Spark, and Spark® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.