Training Many Anomaly Detection Models using Azure Batch AI
This post is authored by Said Bleik, Senior Data Scientist at Microsoft.
In the IoT world, it's not uncommon that you'd want to monitor thousands of devices across different sites to ensure normal behavior. Devices can be as small as microcontrollers or as big as aircraft engines and might have sensors attached to them to collect various types of measurements that are of interest. These measurements often carry signals that indicate whether the devices are functioning as expected or not. Sensor data can be used to train predictive models that serve as alarm systems or device monitors that warn when a malfunction or failure is imminent.
In what follows, I will walk you through a simple scalable solution that can handle thousands or even millions of sensors in an IoT setting. I will show how you can train many anomaly detection models (one model for each sensor) in parallel using Azure's Batch AI. I've created a complete training pipeline that includes: a local data simulation app to generate data, an Azure Event Hubs data ingestion service, an Azure Stream Analytics service for real-time processing/aggregation of the readings, an Azure SQL Database to store the processed data, an Azure Batch AI service for training multiple models concurrently, and an Azure Blob container for storing inputs and outputs of the jobs. All these services were created through the Azure Portal, except for Batch AI, which was created using the Azure CLI. All source code is available on GitHub.
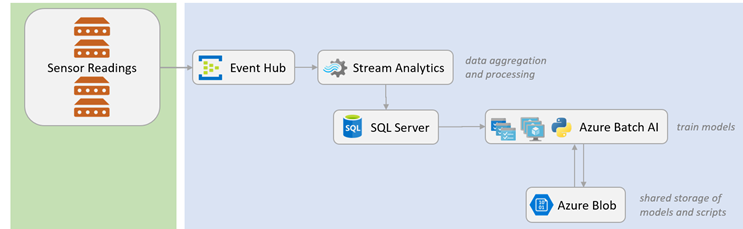
Solution architecture
Data Simulation and Ingestion
The data generator I use is a simple C# console app that sends random sensor readings from 3 imaginary devices, where each sensor is identified by a tag. There are 5 tags in total in this example. Each tag represents a measurement of interest, such as temperature, pressure, position, etc. The values are generated randomly within a specific range for each sensor. The app uses the Azure SDK to send JSON messages (see figure below) to Event Hubs, which is the first interface in the pipeline. The C# source file can be found here.
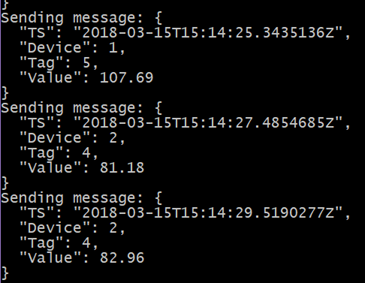
Messages sent to Event Hubs
Data Aggregation
Assuming the sensors send data at a very high frequency, one would want to apply filters or aggregation functions to the incoming streams. This preprocessing step is often necessary when working with time series data and allows extracting better views or features for training predictive models. In this example, I choose to read in the average measurement value of a sensor in tumbling window intervals of 5 seconds. For that, I've created an Azure Stream Analytics (ASA) job that takes in the Event Hub stream as input, applies the aggregation step, and saves the processed messages into a SQL Server database table. The aggregation step can be done in a SQL-like query within ASA as shown below.
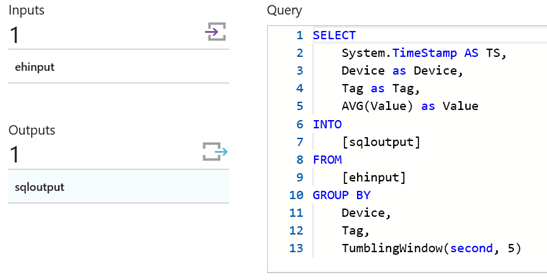
Query definition in ASA (Event Hubs input and SQL output ports are also shown to the left)
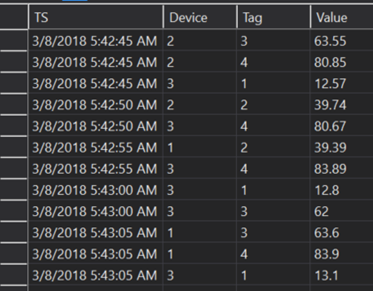
Processed data in SQL Server
Training
One assumption I make here is that we have access to sufficiently large amounts of data for each sensor and that training one model for each sensor independently makes more sense than having a universal model trained on data from multiple sensors. The model I use is an unsupervised univariate One-class SVM anomaly detection model, which learns a decision function around normal data and can identify anomalous values that are significantly different from past normal sensor measurements. Of course, one could use other models that better fit the task and data, including supervised methods, if explicit labels of anomalies are available. I'm also keeping the model simple, as I don't do any hyperparameter tuning or data processing, besides normalizing the data before training.
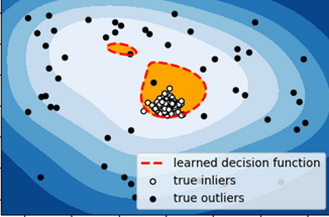
One-class SVM (from scikit-learn.org)
The main purpose of this exercise is to show how multiple models can be trained concurrently in a scalable way, but before running parallel training jobs, it's important to create a parametrized training script that can run for a specific sensor (I'm using Python here). In my setup, the parameters for such a script are the sensor identifiers and timestamp range (device, tag, ts_from, ts_to). These are used to query the SQL Server database and retrieve a relevant chunk of training data for a specific sensor. The other set of static parameters are read from a JSON config file. These are common across all sensors and include the SQL query, the SQL Server connection string, and the connection details of the Azure Blob container into which the trained models are saved.
As you have noticed, we ended up with an embarrassingly parallel task to solve. For that part, I've created an Azure Batch AI service that allows submitting parallel training jobs on a cluster of virtual machines on Azure. Batch AI also allows running distributed training jobs for popular toolkits like CNTK and TensorFlow, where one model can be trained across multiple machines. In our scenario, however, I use custom jobs, where each job executes a Python script for a specific sensor (the sensor details are passed as arguments to the script). Batch AI jobs can be created using the Azure CLI or from the Azure portal, but for our case, it's easier to create them through a Python program using the Azure Python SDK, where you can enumerate all sensors by looping through the devices and tags and run a corresponding job for each sensor. If you look at the CLI commands I used to create the cluster, you would notice that the cluster is made up of two Ubuntu Data Science Virtual Machines (DSVMs) and that I specified the Azure Blob storage container to be used as a shared storage location for all nodes in the cluster. I use that as a central location for both inputs (training script and config file) and outputs (serialized trained models) of the Batch AI jobs. The Blob container is mounted on each node in the cluster and can be accessed just like any storage device on those machines.
Finally, after running the program, you can look into the Blob storage container and make sure that the serialized models are there. The models can be loaded and consumed afterwards in batch, using similar parallel jobs, or perhaps individually through some client app, in case prediction latency is not an issue.
Saved models (shown in Azure Storage Explorer)
That was a simple, yet scalable solution for training many models in the cloud. In practice, you can easily create a cluster with many more virtual machines and with greater compute and memory resources to handle more demanding training tasks.
Said
Resources