AI for Education: Individualized Code Feedback for Thousands of Students
This post is authored by Matthew Calder, Senior Business Strategy Manager, and Ke Wang, Research Intern at Microsoft.
There are more than 9,000 students enrolled in the Microsoft Introduction to C# course on edX.org. Although course staff can’t offer the type of guidance available in an on-campus classroom setting, students can receive personalized help, thanks to a project from Microsoft Research. When a student’s assignment contains mistakes, that student—within seconds—receives a message specific to their code submission. Beyond just informing the student that their program doesn’t work, Microsoft has created a tool which automatically generates feedback that precisely identifies errors and even hints at how to correct them. Students are happy to get fast, focused guidance so they can concentrate on learning new skills rather than on just troubleshooting.
Learning from Thousands of Students
Ke Wang is the Microsoft Research Intern who has led this project since summer 2016. Paul Pardi, Principal Content Publishing Manager in Microsoft Learning, initiated the project because his team was looking to better teach the thousands of students who take their Massive Open Online Courses (MOOCs) through a partnership with edX.org. The idea was to see more students completing their courses with the help of practical guidance that addresses potential blocking issues with their assignments. With a focus on the beginner course Introduction to C# from Paul’s team, Ke conducted the project, along with his internship mentor Microsoft researcher Rishabh Singh and his PhD advisor Prof. Zhendong Su at University of California, Davis.
Previous academic techniques for providing feedback on programming assignments were rule-based and heavily relied on instructors to construct them manually. But it’s hard to port rules across different problems, and the feedback is often neither precise nor quick enough to be helpful when a student is mid-course. Also, many online coding platforms adopt a test-case based approach, using pre-defined inputs and checking whether the respective outputs are correct. Students are guided toward correcting their mistakes simply by presenting all the incorrect outputs.
Besides being fully automated, fast, and precise, this project was designed up front to be used by students in an actual course. Indeed, the fact that there are a significant number of student submissions is what makes Ke’s approach possible. Using a new search algorithm, the first step is to search all the previous student program submissions to identify a data set that can be used as a guide to repair an incorrect student program. Because thousands of students are solving the same assignment, that data can be used to learn different ways to create a working program. The resulting model is then used to generate appropriate feedback.
Focus on Semantics Not Syntax
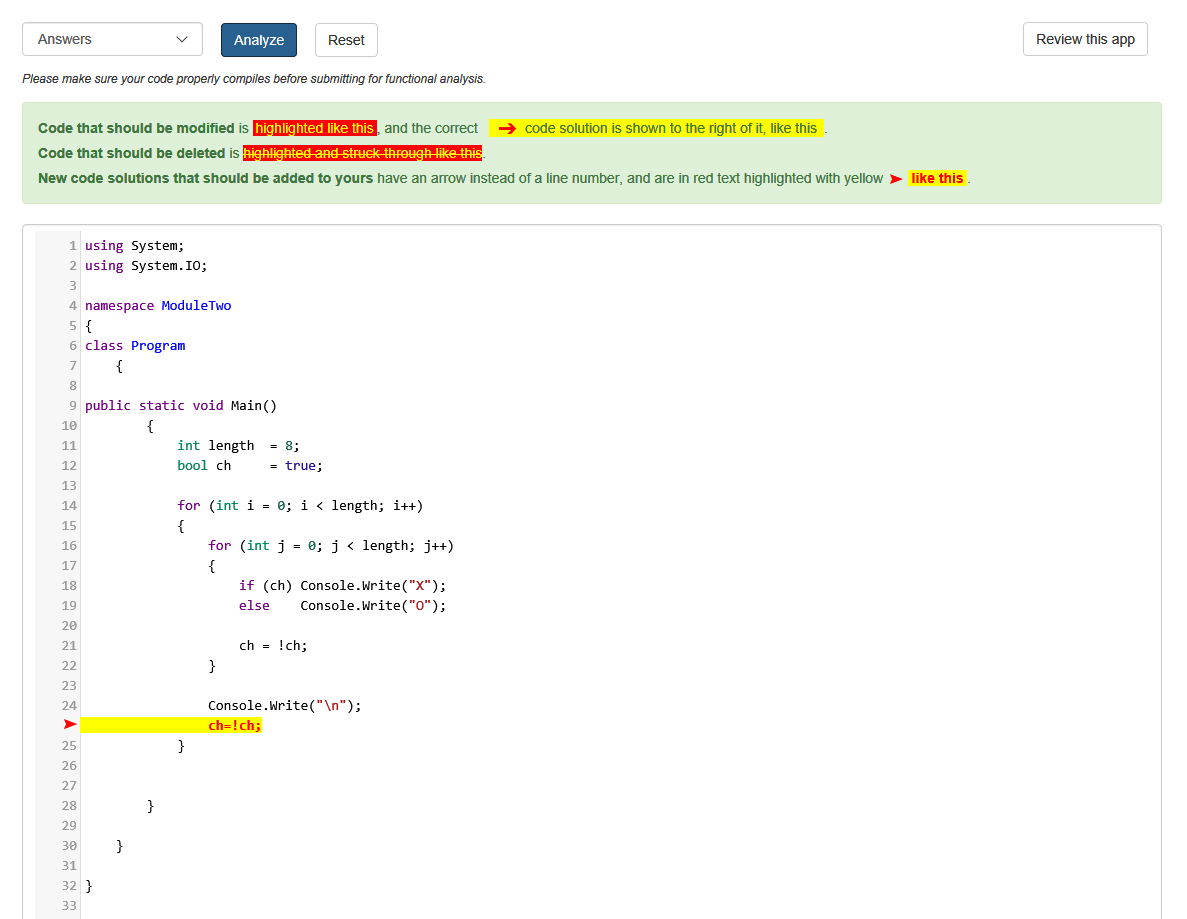
After a representative set of programs is identified, the goal is to pinpoint the minimum set of corrections that a student needs to make for the program to work. There is no need to touch everything in the code; the idea is to identify the parts of the program that need to be corrected without changing the rest of the program. Directly copying from similar correct programs and pasting into the incorrect program introduces redundancy or overwrites accurate parts that are totally unrelated to the error. Instead, the key to success lies in pinpointing the mistakes and providing only minimal and necessary corrections.
In the examples below, the student is asked to write a program that creates a chess board pattern of X’s and O’s
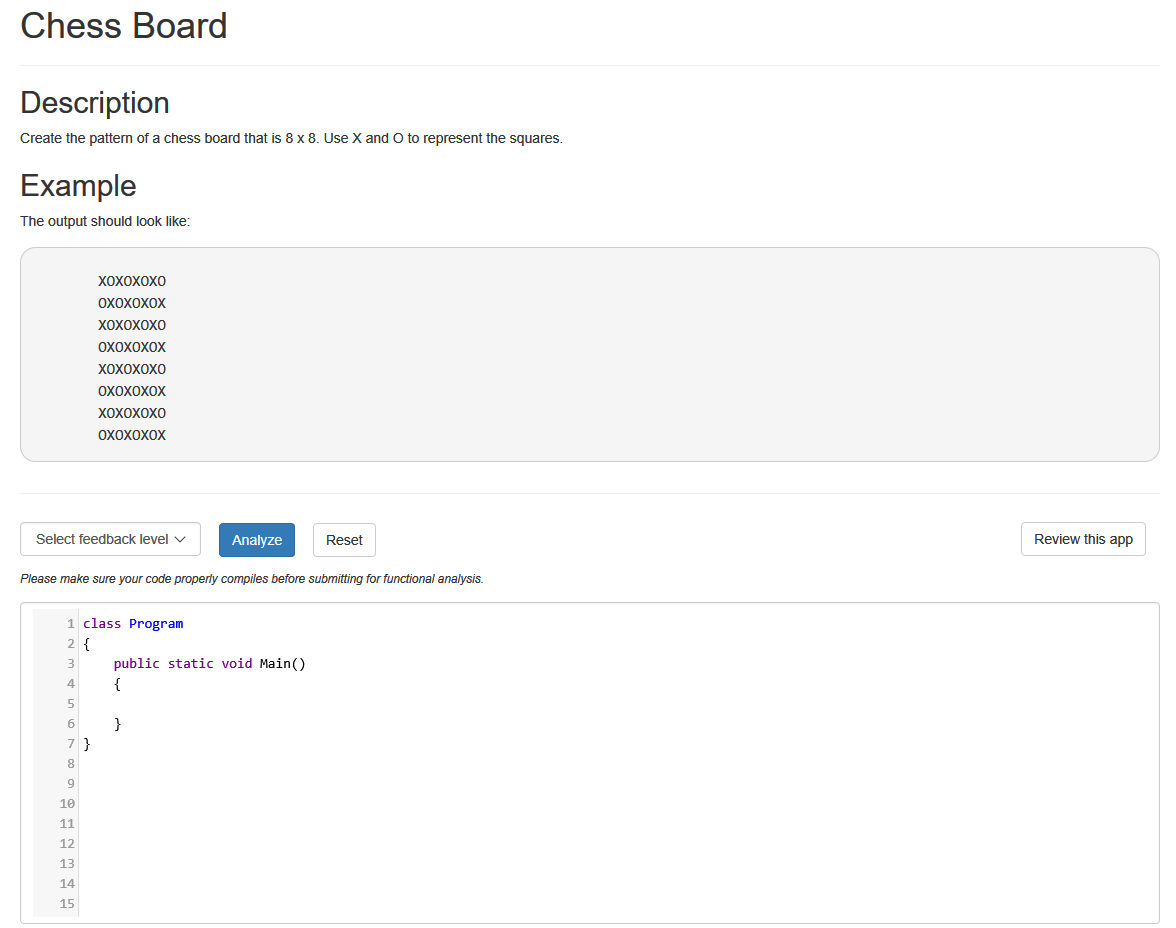
The tool has the flexibility to analyze at various levels: location only, statement level, sub-statement level, or the answer. Here the tool shows where a change needs to be made at the statement level.
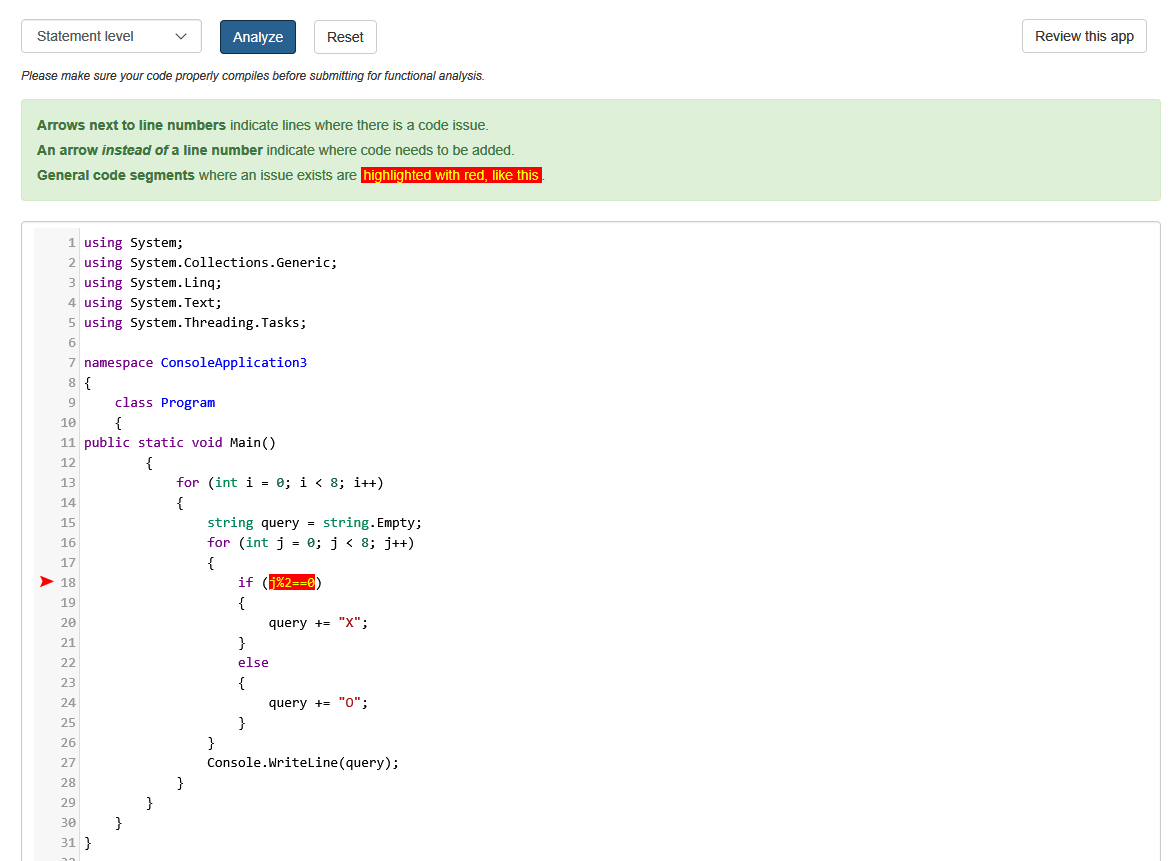
In the following example, the tool is showing where code was missing, as well as specifically what needs to be added in order for the program to work.
Previous approaches have tried to represent the meaning of a program through its syntax. However, it’s possible to understand all the surface-level syntax of a program without having a deeper understanding of what the program does. Ke and his colleagues have been investigating the application of deep learning techniques to address the same program analysis tasks in a more effective way: using a semantic approach to capture the essence of a program. By capturing the meaning of a program more accurately, the system understands what the program is supposed to do. One can accelerate the process of finding similar programs, locating the incorrect program region, and delivering the respective fixes.
On a large-scale evaluation of the system, with thousands of student submissions, this system can fix almost 90 percent of incorrect assignments—within three seconds! And, because of Ke’s approach, the system can be easily reused for other programming languages, courses, and problems, with the potential to help thousands more students.
Recently the team has been awarded a patent for this project (401696-US-NP), and Ke continues to work with Paul’s team to refine the tool. After using it with another set of students, Microsoft plans to make it more widely available. If you are interested in learning more, send mail to Paul.Pardi@microsoft.com.