How Indiana Farm Bureau Insurance Uses AI to Predict Customer Churn
This post is authored by Zoran Dzunic, Data Scientist, Chris Hoder, Program Manager, and Tao Wu, Principal Data Scientist Manager, at Microsoft.
Indiana Farm Bureau Insurance (IFBI) has served Hoosiers for more than 80 years. Organized in 1934 by Indiana Farm Bureau, Inc., the company has grown to include insurance products for auto, home, life, business and farm, along with other financial services. With a home office in downtown Indianapolis and local offices in all 92 counties, Indiana Farm Bureau Insurance serves its customers with more than 400 agents and approximately 1,200 employees living and working throughout the state.
Managing customer churn is a key part of the IFBI engagement strategy. Working closely with a Microsoft data science team, IFBI analysts used the machine learning and data wrangling capabilities of Microsoft's AI platform to identify "at risk" customers with high precision, helping them develop targeted programs for churn prevention.
The effective use of data specific to the insurance domain turns out to be a critical success factor for insurers looking to improve the accuracy of churn prediction. Existing churn prediction models from other domains often require detailed, high frequency user behavioral data. While such data is often easy to collect in domains such as retail, insurance companies typically have limited data about customer behavior (e.g. when renewing or cancelling policies, or dealing with claims). IFBI and Microsoft data science teams found that existing account and policy information were valuable churn predictors. Therefore, in addition to any user activities, customers should be represented using data that describe their current state.
Moreover, the insurance marketplace being dynamic, trends play a significant role in churn prediction. The best churn prediction models change rapidly over time and should be retrained with the most recent data, e.g. at least every month.
In addition, effective data aggregation is also important for identifying at-risk customers with high precision. Insurance data has a natural hierarchy that should be exploited when building machine learning models. To predict churn at a household level, policy-related information should be aggregated per household, and different aggregation functions may be needed for different attributes, i.e. features, to use machine learning terminology.
For instance, the discount percent makes more sense if it is taken as an average across policies, while the premium makes sense if taken both as a sum and an average across policies.
Operations like those mentioned above are generally called data wrangling, and they may be complex due to the nature of insurance data. Fortunately, tools such as Azure Machine Learning enable users to quickly manipulate data with easy-to-use browser-based UI, as well as with their support for open source languages such as Python and R.
A major advantage of using Microsoft's AI platform is ease of deployment. An operational architecture is illustrated below.
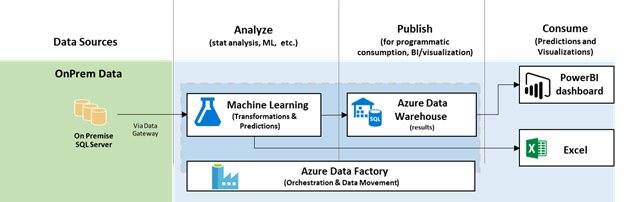
In this scenario, data that contains information about customers, their policies and claims resides in an on-premises database. Azure ML is responsible for churn prediction and has access to the on-premises database via the Microsoft Data Management Gateway. A churn model is (re)trained regularly using the most recent data. Predictions on active customers, which consist of predicted probability of churn and features that explain the prediction, are also performed regularly and stored into Azure SQL Data Warehouse. Azure Data Factory is used to orchestrate periodic execution of the training and scoring experiments. The results can be visualized using Power BI dashboards or Excel. Furthermore, by moving to the cloud, adopting modern platforms, and embracing comprehensive identity and management solutions, customers can improve the overall security of their solution as well.
Hong Gao, Manager of Enterprise Data Management at IFBI, explained that "analysts started with five years of data to build the customer churn model, but the Azure Machine Learning predictive model showed that the latest information was most relevant. Churn factors can evolve over time, so it made sense that the best predictors were the most recent factors. Feature engineering was a time-consuming process for IFBI because the data existed in multiple layers with complex relationships." Further, she reasoned that "using an experienced data scientist helped IFBI deconstruct and position the data for more instructive analytics. Azure Machine Learning provided a robust framework for manipulating data."
According to Chris Coffin, Director of Marketing Systems at IFBI, "future plans involve storing the churn probabilities directly in MS Dynamics CRM to direct mitigation strategies, leverage marketing automation capabilities, and further customer engagement activities."
Chris Coffin reflected that "IFBI wanted an agile, open, and flexible data analytics platform. By leveraging Cortana Intelligence, IFBI has been able to more successfully manage, store, analyze, and visualize data. Most importantly, IFBI now has enhanced tools to understand customers better, act on these insights, and make direct business impacts," he concluded.
Zoran, Chris & Tao