Machine Learning for Developers - How to Build Intelligent Apps & Services
This post is authored by Daniel Grecoe, Senior Software Engineer at Microsoft.
There's a lot of talk about machine learning these days and how it will transform applications and services. Most of it is right on target: ML is definitely changing the way certain computing tasks will be implemented in the future, why wouldn't it?
In the traditional approach, developers build a rule based engine baked right into the source code. When knowledge of the problem becomes clearer, the rule engine is modified and the process of patching and updating existing applications begins.
With machine learning, we train machines how to recognize patterns and relationships in data for a wide group of problem sets. This training is then used to build a machine learning model. A model can simply be thought of as an API in that it accepts a data set and returns a result that can be acted upon. When more data is acquired the model can be retrained to produce more accurate predictions. Couple this approach with the cloud and we can publish these models online and build applications that consume them and remove the need for our local rules engines.
This is powerful stuff!
It means we can retrain the ML model without ever having to touch our applications and in many cases, we remove the need to ever patch and update.
To be clear, I'm an engineer at Microsoft not a data scientist. I do, however, interact with Data Scientists daily and part of my job is to incorporate ML into cloud-based big data pipelines. In that capacity, I've been in a unique position to learn about the data science process and operationalizing ML models in enterprise grade solutions using the cloud, the Azure cloud.
At Microsoft Build 2017 I held a talk for developers that covered Data Science and Machine Learning basics to demystify these topics and finished by giving two examples on how to operationalize ML in work flows. In the first example, I built a simple Azure Machine Learning model and describe how it could be used in an application or service. The second example reviewed a big data pipeline utilizing text analytics from the Cognitive Services API and finished with a Power BI dashboard to show progress.
It was a lot to cover in an hour, but it's an exciting topic which is hard to compress into 60 minutes and provide full context.
If you are a developer interested understanding machine learning and the Azure cloud infrastructure in which to build pipelines, the following links are for you.
Understanding Data Science and Machine Learning
- Build 2017 Machine Learning for developers, how to build more intelligent apps and services.
- Data Science for the rest of us.
Machine Learning Tools
- Cognitive Services API: Provides a broad set of API's for vision, speech, text, knowledge and search.
- Azure Gallery: Find existing models you can use out of the box.
- Azure Machine Learning: Build powerful models using a web based drag and drop interface.
- Microsoft R Server: Build R models and more
- Microsoft SQL Server 2017 with built-in R and Python support.
- Cognitive Toolkit: For building deep learning models.
- Data Science Virtual Machine: A powerful data science toolbox for both Windows and Linux.
Azure Services Used in the Pipeline Described in the Build Talk
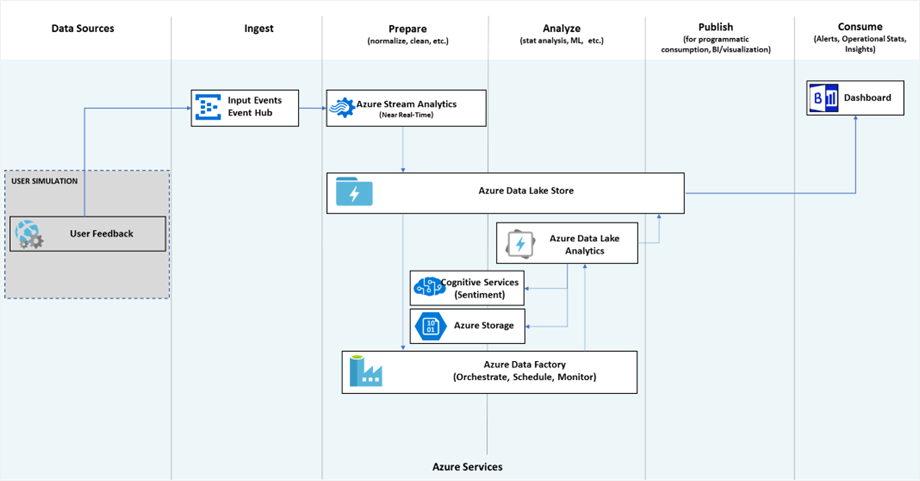
- Azure Web Jobs (user simulation)
- Azure Event Hub
- Azure Stream Analytics
- Azure Storage
- Azure Data Lake Store
- Azure Data Lake Analytics
- Cognitive Services API – Text Analytics
- Azure Data Factory
- Power BI
- The Intelligent Data Lake is a great article to read more about this type of solution.
Hope you find these resources useful in your machine learning / AI journey!
Daniel