Optimizing Intelligent Apps Using Machine Learning in SQL Server
Re-posted from the Azure blog.
SQL Server 2016 introduced a new function called R Services, bringing machine learning capabilities to the platform, and the next version of SQL Server will further extend this with support for Python. These new capabilities – of running R and Python in-database and at scale – let developers keep their analytics services close to the data, eliminating expensive data movements. They also simplify the process of developing and deploying a new breed of intelligent apps.
There are several optimization tips and tricks available to developers, to help you get the most mileage out of SQL Server in these scenarios, including fine-tuning the model and boosting performance. In a new blog post, we apply some of these optimization techniques to a resume-matching scenario and demonstrate how such techniques can make your data analytics much more efficient and powerful. The optimization techniques covered are:
- Full durable memory-optimized tables.
- CPU affinity and memory allocation.
- Resource governance and concurrent execution.
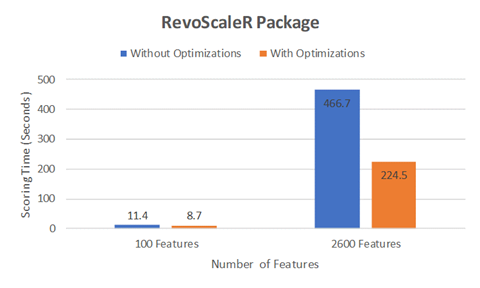
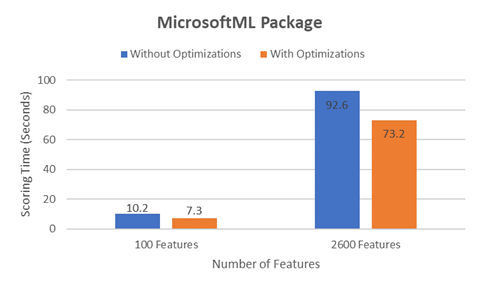
We ran benchmark tests where we compared the scoring time with and without these optimizations, scoring 1.1 million rows of data using the RevoScaleR and MicrosoftML packages to separately train a prediction model. Tests were run on the same Azure SQL Server VM using the same SQL query and R codes. As the charts below show, using such optimizations can significantly boost performance.
Click here to read the original post and access the full tutorial, complete with sample code and detailed step-by-step walkthroughs.
CIML Blog Team