Cloud-Scale Text Classification with Convolutional Neural Networks on Microsoft Azure
This post is by Miguel Fierro, Ilia Karmanov, Thomas Delteil, Andreas Argyriou, and Max Kaznady, all Data Scientists at Microsoft.
Natural Language Processing (NLP) is one of the fields in which deep learning has made significant progress. Specifically, the area of text classification, where the objective is to categorize documents, paragraphs or individual sentences into classes, has attracted the interest of both industry and academia. Examples include determining what topic is discussed in a sentence or assessing whether the sentiment conveyed in a text passage is positive, negative or neutral. This information can be used by companies to define marketing strategy, generate leads or improve customer service.
This is the fourth blog showcasing deep learning applications on Microsoft's Data Science Virtual Machine (DSVM) with GPUs using the R API of the deep learning library MXNet. The DSVM is a custom virtual machine image from Microsoft that comes pre-installed with popular data science tools for modeling and development activities.
In our first post, we showed how to set up a deep learning environment in one of the new DSVMs with NVIDIA Tesla K80 GPUs, installing CUDA drivers, Microsoft R Server and MXNet. In the second post, we presented a pipeline for a massive parallel scoring of 2.3 million images forming a collage of the Mona Lisa using HDInsight Apache Spark cluster. Finally, in the third post we illustrated how to train a network on multiple GPUs to classify objects among 1000 classes, using the ImageNet dataset and ResNet architecture.
In this sequel of the deep learning series, we will demonstrate how to use Convolutional Neural Networks (CNNs) in a text classification problem. We will explain how to generate an end-to-end pipeline, train a CNN for text classification and prepare the model for production so it can be queried by a user to classify sentences via a web service.
Deep Learning for Text Classification on Azure
The development of Recurrent Neural Networks (RNNs) has led to significant advances in deep learning for NLP. These networks, especially the subclass of Long Short Term Memory Networks (LSTMs), have achieved promising results in tasks related to temporal series, for instance, in speech recognition, text understanding and text classification, usually treating the text as groups of words.
The area of text classification has been developed mostly with machine learning models that use features at the word level. The use of word features such as bag of words, n-grams or word embeddings has been shown to be very successful. Some examples of text classification methods are bag of words with TFIDF, k-means on word2vec, CNNs with word embedding, LSTM or bag of n-grams with a linear classifier.
In parallel, there have been important advances in image recognition using different types of CNNs . The ResNet architecture introduced by Microsoft Research, which was the first to surpass human performance in image classification, is an example of this. The reason for this extraordinary success comes from the fact that CNNs learn hierarchical representations in increasing levels of abstraction. This means that they automatically generate features that allow for classifying the inputs.
Motivated in part by the success of CNNs in image recognition problems, where the inputs to the network are the pixels in images, a group of researchers proposed using CNNs for text understanding, using the most atomic representation of a sentence: characters. Even though other researchers have used sub-word units as inputs to deep networks for information retrieval and anti-spam filtering, the idea of using CNNs for text classification at character level first appeared in 2015 with the Crepe model. The following year the technique was developed further in the VDCNN model and the char-CRNN model.
Text Classification with Convolutional Neural Networks at the Character Level
To achieve text classification with CNN at the character level, each sentence needs to be transformed into an image-like matrix, where each encoded character is equivalent to a pixel in the image. This process is explained in detail in Zhang et al., but here's a quick summary.
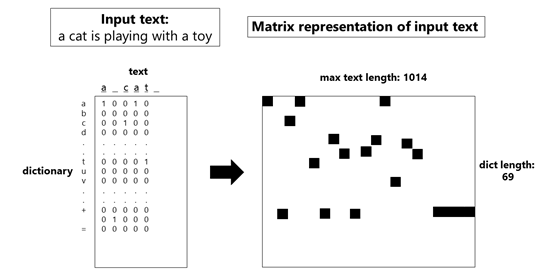
Fig. 1: Scheme of character encoding. Each sentence is encoded as a 69x1014 matrix.
The encoding of each sentence is represented in Fig. 1. Each sentence is transformed into a matrix, where the rows correspond to a dictionary and the columns correspond to the characters in the sentence. The dictionary consists of the following characters:
abcdefghijklmnopqrstuvwxyz0123456789-,;.!?:'\"/\\|_@#$%^&*~`+ =<>()[]{}
For each character in the sentence, we compute a one-hot encoded vector, that is, for each column, we assign a 1 to the corresponding row. As an example, if we want to encode the sentence "a cat" we will create the encoding shown in Fig. 1 (left).
Generally, networks require an input that is fixed-sized (to correspond to the fixed-size weights and bias matrices). The size of the vocabulary is fixed at 69 and the length of the text is fixed at 1014 characters – longer sentences are trimmed down and shorter sentences are padded with spaces.
One of the main bottlenecks in a process that parses and transforms vast amounts of data is memory management. In most situations, the dataset will not fit in the memory of the DSVM and is thus processed in mini-batches: reading a chunk, processing it to create a group of encoded images and freeing the memory before starting again. The current version of MXNet for R provides access to a C++ iterator that allows data to be in batches from a CSV file. We built upon this to create a custom-iterator (explained in this tutorial) that not only reads the CSV file in batches but also processes (and expands) the data into the image-matrix in batches.
Convolution with Characters
A convolution allows one to generate a hierarchical mapping from the inputs to the internal layers and to the outputs. Each layer sequentially extracts features from small windows in the input sequence and aggregates the information through an activation function. These windows, normally referred to as kernels, propagate the local relations of the data over the hidden layers.
As shown in Fig. 2 (left), a kernel applied to an image is usually symmetric (e.g. 5 by 5). A convolution of 3, 5 or 7 pixels can represent a small part of the image, like an edge or a shape.
In a model like Crepe or VDCNN, the first convolution has the size of 3xn or 7xn (see Fig. 2 right), where n is the size of the vocabulary.
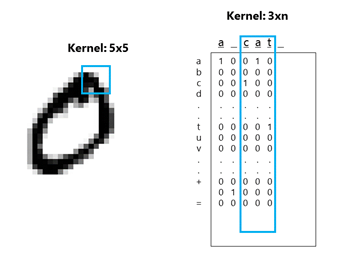
Fig. 2: Comparison of the kernel size in an image with that in a matrix representation of a sentence.
In Fig. 3, we represent the Crepe model, composed of 9 layers (6 convolutional and 3 fully connected). We provide the code for the Crepe model in R and Python. We also provide the code for the VDCNN model in R and Python, but do not show its representation due to space constraints.
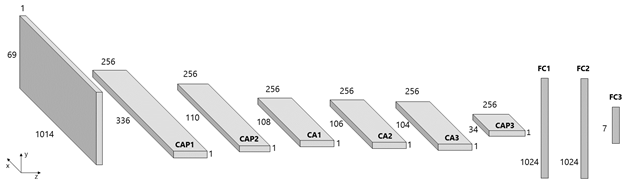
Fig. 3: Scheme of Crepe CNN. CAP stands for Convolution, Activation and Pooling. CA stands for Convolution and Activation.
FC stands for Fully Connected. This scheme assumes a batch size of 1.
As can be seen in the Fig. 3, the input, which is the encoded sentence, is initially transformed with a convolution of 7 in the x-axis and 69 in the y-axis with 256 feature maps, followed by a max pooling of 3 in the x-axis, flattening the image and reducing its size in that axis. The number of feature maps is constant in the rest of the internal layers of the network. After the first convoluted layer, there is a second convolution and pooling. Following that, there are three convolution layers. Next, there is a third convolution and pooling. Finally, there are 3 fully connected layers. All the technical details of the internal transformations of the network can be found in the paper or the code that we have provided.
As an interpretation of the Crepe architecture, we can speculate that, through the hidden layers, a hierarchical transformation is learned, where the first convolution of 7x69 could be loosely interpreted as a character n-gram approach, expressing something close to the average word whose length is 7 characters. The lower layers could represent groups of neighboring characters, with middle layers learning "n-grams" of these groups and final layers capturing semantic elements. However, more experiments would be needed in order to verify this hypothesis.
In Fig. 4 we show the results of training the Crepe model on the Amazon categories dataset, which can be downloaded using this script. This dataset consists of a training set of 2.38 million sentences and a test set of 420,000 sentences, divided into these 7 categories: "Books", "Clothing, Shoes & Jewelry", "Electronics", "Health & Personal Care", "Home & Kitchen", "Movies & TV" and "Sports & Outdoors". The model has been trained for 10 epochs on an Azure NC24 with 4 K80 Tesla GPUs. The training time was around 1 day.
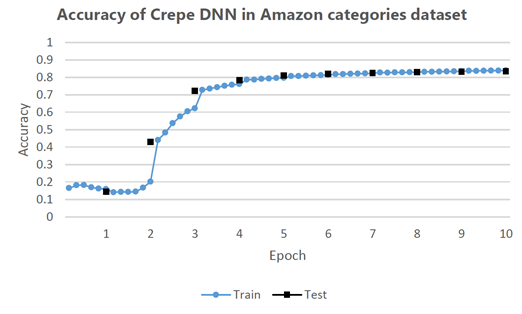
Fig.4: Training and test accuracy using the Crepe model on the Amazon categories dataset.
Development of Cloud Infrastructure for Text Classification in Azure
Once we have the CNN trained model, we can use the Azure cloud infrastructure to operationalize the solution and provide text classification as a web service. The complete pipeline of creating a deep learning text classifier in Azure is detailed in Fig. 5.
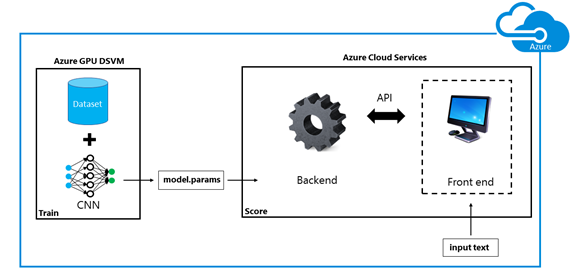
Fig. 5: Workflow of the solution. In the training phase, we use a dataset to train the model parameters of the CNN in an
Azure GPU DSVM. These parameters are fed to the backend of the Azure Cloud Service for scoring. Through an API,
the front end is shown to the user who can interact with the application. The front end can be run on different clients.
As shown in Fig. 5, the first step is to process the dataset. Once the model is trained, we can host it on Azure Cloud Services and use it to classify sentences via a web service. We created a Python web service that exposes the model for scoring via a web API. There is also a simple web app, programmed in JavaScript and HTML, that consumes the API, and provides a flexible environment for experimenting with different trained models.
The front end is managed by an AngularJS application, which consumes the Python API hosted on Azure Web Apps, and visualizes the classification for the user. The Python API uses a popular framework called Flask to handle the requests and responses. The model is held in memory by the web service process for superior performance. The code and instructions are open sourced in this repo.
On this web page, we show the complete system, which also contains the text analytics API from the Cortana Intelligence Suite.
Fig. 6 shows the result of the text classification API when we type the following review: "It was a breeze to configure and worked straight away."

Fig. 6: Result of the sentence: "It was a breeze to configure and worked straight away".
From the sentence, we can guess that the user is talking about the setup of some technological device. The system predicts that the most probable class is "Electronics".
In Fig. 7 we input "It arrived as expected. No complaint.". The Crepe model shows a very positive sentiment. In a general scenario, something arriving as expected could be seen as neutral. However, in the context of an online-retailer (such as Amazon) a review that a product arrived on time may be considered a positive experience, rather than neutral.

Fig. 7: Result of the sentence: "It arrived as expected. No complaint".
The code for the end-to-end solution can be found in this repo, along with a more detailed explanation of the whole implementation.
Summary of the End to End Text Classification Solution
In summary, in this post, we showed how to create an end-to-end text classification system using deep learning and the Azure cloud infrastructure.
The CNNs we discussed in this post were trained at the character level. This means that we do not use words or groups of words as the input to a network. In contrast, we encode each sentence as a matrix, mapping each character of the sentence to a dictionary. The resulting matrix is fed into a convolutional network, which can learn increasingly abstract hierarchical representations of this input. These features are used to determine the class of the text.
We demonstrated how easy it is to train one of these networks on our high-performance GPU DSVMs by distributed computation with 4 GPUs. Once the model is trained, one can very quickly create a web service in Azure Web Apps to host the prediction system.
All the code is open source and accessible in this repo.
Miguel, Ilia, Thomas, Andreas & Max
Acknowledgements
We would like to thank TJ Hazen from Microsoft for his assistance and feedback on this post.