Data Manipulation at Scale with Microsoft R Server & Spark on Azure HDInsight
Re-posted from the Revolutions blog.
Dealing with distributed data and having to program concurrent systems is not always the easiest of tasks, and data scientists familiar with R are unlikely to have extensive experience with such systems. In such scenarios, Spark offers a very popular, intuitive distributed data processing platform, with R and Python APIs that are more familiar to the average data scientist than scala. An intriguing set of APIs available for Spark for R users is the sparkapi package from RStudio and the associated sparklyr project, which provides a similar dplyr syntax for manipulating Spark DataFrames.
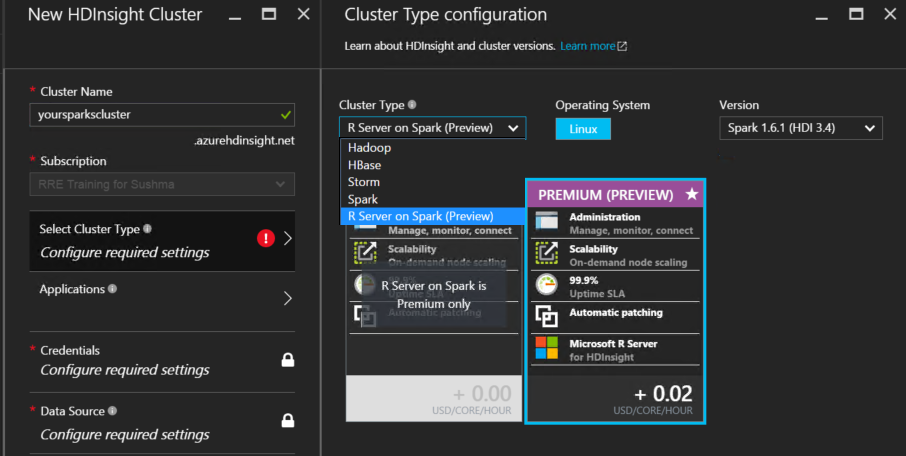
Azure HDInsight, a key component of the Cortana Intelligence Suite, is Microsoft's Apache Hadoop distribution for the cloud. HDInsight offers easy to use Hadoop, Spark, R, HBase, and Storm cloud services. Configuring the numerous components of the Hadoop ecosystem can be a tricky job at best, so the HDInsight service was designed to give data scientists and analysts the power of scalable distributed computing in the cloud without the hassles of configuration and management.
In this post, we demonstrate how to utilize premium HDInsight Spark clusters with a complete installation of Microsoft R's stack for doing data manipulation at scale. Read the original post here or by clicking the image below.
CIML Blog Team