Speeding Up Azure ML Web Services Containing R or Python Modules
This post is authored by Danil Kirsanov, Senior Developer at Microsoft.
Response time is one of the critical parameters of a deployed Azure Machine Learning web service (see this walkthrough for information on how to create an Azure ML experiment and deploy a web service). In this post, we discuss one of the ways to speed up an R or Python based web service – by making sure that key initialization steps (e.g. time consuming computations, loading variables from attached .zip files, installing additional packages, etc.) happen only at the very first web service call.
First, a brief review of R and Python execution in Azure ML web services:
- The web service is backed by multiple machines, with load balancing. There is no way for users to know which machine processes a particular incoming call.
- To save time, R and Python interpreters are reused between calls.
- In particular, they might be shared between the multiple modules of the same experiment.
- All R user-defined variables and functions are cleared at the end of each call.
- For Python, global variables are not cleared.
The latter difference is due to the execution pattern for R and Python modules in Azure ML – while the Execute Python Script module is based on a function call, the Execute R Script allows arbitrary scripts.
The idea behind "initialize once" is very simple and boils down to keeping a global state between the service calls. Nevertheless, this simple trick is very helpful for many customers in production, and, in one recent case, this process helped cut down the web service response time by the factor of 6!
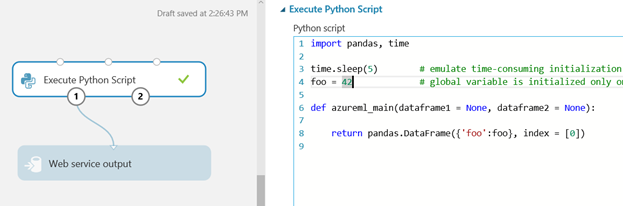
Execute Python Script
In Execute Python, initializing the global state is exactly the same as in the regular Python module – just put the initialization code and global variables outside the azureml_main function; it is executed only once and global variables are retained between function calls (see this experiment).

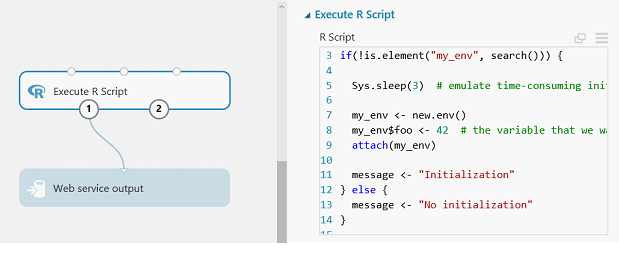
Execute R Script
Persisting variables in R modules is a bit trickier as all variables and functions are cleared at the end of the service call (roughly speaking, we call rm(list = ls(all.names = TRUE)) after each call). The easiest way to persist variables between calls is to keep them in the attached environment, which is not cleared.
In this experiment, we create and attach the environment my_env only once and re-use it at every call. You have to be careful re-implementing this advanced maneuver though – attaching the environment at every call leads to a memory leak.
Conclusion
We suggest deploying the experiments provided here as web services and making several test calls to see the effect. The first "initialization" call takes much longer than subsequent calls to the service.
Some final notes:
- This technique is not suited for accumulating information between calls – the web service is usually backed by multiple machines that do not talk to each other.
- This technique is only efficient for speeding up deployed web services. Regular Studio experiments have separate clean R/Python interpreters for every module, so the "initialization" step is always evaluated.
- If you use this technique for multiple R or Python modules inside a single web service, make sure that the global variable names are different and do not collide, since the same interpreter could be reused for processing all modules in a given service.
If you do try out these techniques, let us know how they worked out for you – you can share your feedback below.
Danil