Predictions at the Speed of Data
This post is by Joseph Sirosh, Corporate Vice President of the Data Group at Microsoft.
Online transaction processing (OLTP) database applications have powered many enterprise user-cases in recent decades, with numerous implementations in banking, e-commerce, manufacturing and many other domains. Today, I'd like to highlight a new breed of applications that marry the latest OLTP advancements with advanced insights and machine learning. In particular, I'd like to describe how companies can predict a million events per second with the very latest algorithms, using readily available software.

Take credit card transactions or loan applications, for instance. These can trigger a set of decisions that are best handled with predictive models. Financial services companies need to determine whether a particular transaction is fraudulent, or whether a loan will be repaid on time.
As the number of transactions per second (TPS) increase, so does the number of predictions per second (PPS) that organizations need to make. The Visa network, for instance, was capable of handling 56,000 TPS last year and managed over 100 billion yearly transactions. With each transaction triggering a set of predictions and decisions, modern organizations have a need for a powerful platform that combines OLTP with a high-speed prediction engine. We expect that an increasing number of companies will need to hit 1 million PPS or more in coming years.
What kind of architecture would enable such use cases? At Microsoft we believe that computing needs to take place where data lives. This minimizes data movement and the prediction engine sits close to the database (in-database analytics). That's precisely how SQL Server 2016 was designed.
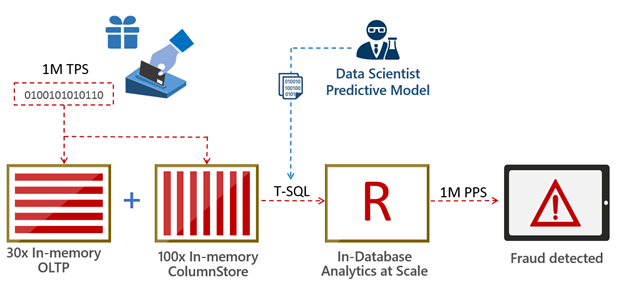
Take the credit card fraud detection example I mentioned above – one can handle it in the following manner:
- A data scientist creates a predictive model for credit-card fraud detection based on historical transaction data. This model is stored as a standard database object.
- New credit-card transactions are ingested and stored in high-speed in-memory columnstores.
- The data is likely to require some preparation for advanced analytics. This includes operations such as joining data across multiple tables, cleansing, creating aggregations and more. SQL shines here because these steps execute much faster in production when done at the database layer.
- The new transaction data and the predictive model are sent using T-SQL to an in-database predictive engine. Predictions can be done in batch or at the single transaction level. In SQL Server 2016 you can build on the power of R, with its extensive set of packages and the built-in high scale algorithmic library (ScaleR) provided by Microsoft.
- Predictions can be retuned immediately to an application via T-SQL and/or stored in the database for further use.
This is shown visually below:
The above architecture is very versatile. In addition to using it in fraud detection, we've applied this architecture to perform what-if analysis on an auto loan dataset. Imagine scanning through millions of loan applications and being able to predict – within seconds – which loans will default. Now imagine a business analyst launching the same exercise while modeling a scenario where the Federal Reserve increases interest rates. Our loan default prediction model was able to reach and exceed a staggering 1,250,000 predictions per second, completing the what-if analysis within seconds.

Similarly, we executed a fraud detection model on retail transactions at a rate of 700,000 predictions per second. In this case, the predictive model was based on a boosted decision tree algorithm with 50 trees and 33 features. Naturally, the throughput of any given solution is determined by a variety of factors, including the algorithm used, the data types involved and many more.
Several banking and insurance companies rely on very complex architectures to do predictive analytics and scoring today. Using the architecture outlined here, businesses can do this in a dramatically simpler and faster manner.
If you're attending the Microsoft Machine Learning and Data Science Summit or Microsoft Ignite next week, you can see demos of the above solutions in action as part of my sessions there: I will keynote at the Microsoft Machine Learning & Data Science Summit on Monday, September 26th, at 9AM, which will be followed by my General Session at Ignite from 11:00 AM – 12:15PM at the Georgia World Congress Center.
Swing by and learn how companies are predicting at the speed of data, today.
Joseph
@josephsirosh