Predictive Analysis for Telecom – Integrating Azure Data Lake and Azure ML
This post is authored by Daisy Deng, Software Engineer at Microsoft.
Big data is not just a buzz word; it's a reality. As data volumes have exploded in recent past, so have solutions to store and process the data, along with the number of formats to describe the data. Data formats are not just limited to text, audio, video, but also sensor data, clickstream, server logs and many others. To deal with these new types of data, new applications need to be developed, but these can take their own time to emerge and mature. It is wasteful to transform your native data to a defined structure before your business requirements are clear, and it is even more wasteful to throw the data in native raw format away before your new applications find their ways to develop insights. With so many data sources and formats, the data storage and retrieval problem is real and tough.
This is where Azure Data Lake comes to rescue.
A recent trend in the industry has been to extract and place data for analytics into a data lake repository without first transforming the data, which is unlike what would be needed to for a relational data warehouse or key-value store. By storing data in its native format, data lake maintains data provenance and no loss of information resulting from the extraction, transformation and loading (ETL) process. By shifting the process from ETL to ELT (extraction, loading and transformation), a data lake uses a schema-on-read approaches, therefore eliminates the work of defining schemas before business requirements are clear. This also saves greatly on computation, which happens to be much more expensive than storage. As data volumes, data variety, and metadata richness grow, the benefit of the new approach magnifies.
Figures 1 and 2 below illustrate the shift from ETL to ELT.

Figure 1: Traditional Data Management and Analysis
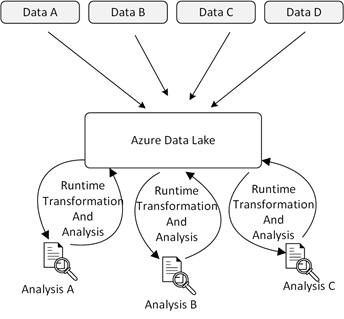
Figure 2: Data Management and Analysis in a Data Lake Environment.
Azure Data Lake is a fully managed on-cloud implementation of Data Lake from Microsoft. It consists of Azure Data Lake Store (ADLS) and Azure Data Lake Analytics (ADLA). ADLS is a data repository capable of holding an unlimited amount of data in its native, raw format, including structured, semi-structured, and unstructured data. And ADLA lets you define your extract schema on read by running U-SQL queries utilizing the power of customized C# code implemented as .NET libraries to perform advanced data extraction and transformation. By using ADLA, running analytics on your data is neither limited by the functionality provided by any query language nor as tedious as writing everything from scratch. ADLA provides enormous flexibility and extends your analytics without a boundary.
Integrating Azure Data Lake with other services in the Microsoft Cortana Intelligence Suite, especially Azure Machine Learning, enables you to build end-to-end advanced analytics solutions and intelligent applications that impact revenue-critical decisions and actions. An end-to-end complete solution involves Azure Event Hub and Azure Stream Analytics to provide highly scalable data ingestion and event processing service, uses ADLS to archive native data, and utilizes ADLA to transform native data into structured data that can be used by Azure ML to develop business insights. Azure ML provides a fully managed cloud service to build, deploy and share advanced analytics, including predictive maintenance, energy demand forecasting, customer profiling, anomaly detection and many other possibilities. Advanced analytics results are stored in Azure SQL Data Warehouse, which provides high-performance query on your structured data. Power BI renders visualization on your streaming data and data in Data Warehouse to show business insights. Azure Data Factory orchestrates data transformation and data movement among all the Azure services that your solution needs to use.
To demonstrate these techniques as well as the ease of building and deploying such intelligent solutions on Azure, we have published a tutorial that shows how to build end-to-end, fully operational real-time and predictive pipelines. The architecture is as follows:
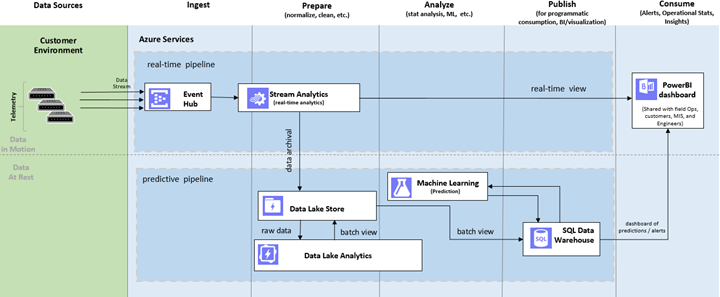
Figure 3: Architecture of Building Real-time and Predictive Analysis on Telecommunication Data
The use case is to predict a telephony network switch failure ahead of time by determining patterns in call drop rates using live and historical call description records. We use a data generator to simulate a phone switch to generate call detail records (CDR) and employ Azure Event hub to ingest data. Two Azure Stream Analytics jobs will work on the CDR data. One will send the data to Power BI for real time visualization, and one will archive the data into ADLS. ADLA runs a U-SQL job to pre-process the data before sending it to SQL Data Warehouse (staging and publishing store) for Azure Machine Learning to run predictive analytics. The AML web service imports data (dropped call aggregates) from SQL Data Warehouse and exports the prediction to SQL Data Warehouse. At the end of the solution, you should be able to see a dashboard like the one below:
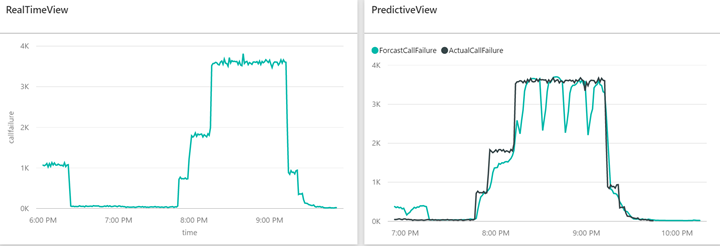
Figure 4: Result Dashboard of Real-time and Predictive Analysis on Telecommunication Data
Click here to get started, and I hope you have fun exploring the tutorial.
Daisy
References
Here are all the Cortana Intelligence Suite services used by the tutorial: