Running Selective Parts of an Azure ML Experiment
This post is authored by Mickaël Savafi, Software Engineer at Microsoft.
Introduction
Azure ML is a drag and drop tool that lets users create machine learning experiments. Experiments are typically constructed by adding modules, tweaking parameters and validating these changes by running the experiment. For every change, however, validation requires running the entire experiment again, and so that can sometimes get quite tedious and time consuming.
Today, we are excited to introduce the ability for users to select a portion of their experiment graph for execution. By selecting the modules which you want to run, and clicking the "Run selected" button, only your selection and its upstream dependencies will be executed.
When is it Appropriate to Use "Run selected"?
The experiment-authoring experience can be done either by running the entire experiment, or by running a portion of the experiment using "Run Selected". Running the entire experiment can help you ensure that it is working fine from start to end, but this can sometimes take a long time, especially for large or complex experiments. On the other hand, if you're iterating on just one portion of an experiment where you happen to be making adjustments, it could be more convenient to only run just the part that's being adjusted. You can iterate very quickly on changes to your modules.
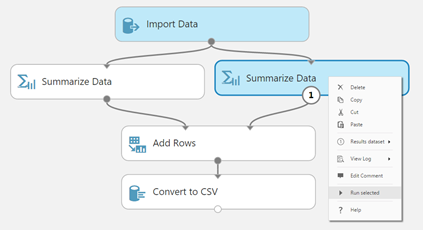
Figure 1: Selecting a part of an experiment to execute; run upstream modules only if necessary.
Running a Selection
Selection choices include either running a single module or a number of modules. If you want to run a subset of modules, select them using your favorite selection method (e.g. click, square selection, Ctrl-click), right-click on the canvas, and select "Run selected". As an alternative, you can open the command bar sub-menu: hover over the "RUN" button, and select the "Run selected" option.
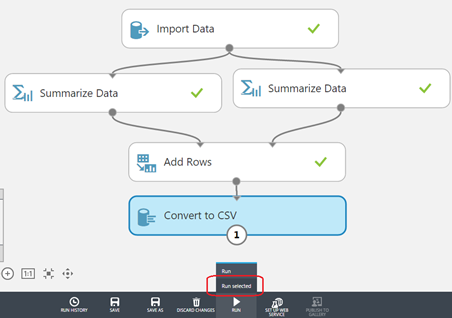
Figure 2: The "RUN" button has a sub-menu that lets you choose between "Run" (runs the entire experiment)
and "Run selected" (runs the selection and its dependencies)
Note that just placing your mouse over the "Run selected" button (whether it's the one from the right-click menu or from the command bar) gives you a preview of which nodes will actually run, by highlighting them in blue.
Why Run More Than Just the Module I Selected?
When you decide to run a part of your experiment, the modules that were previously run and which are not required to run again will stay untouched. Any module impacted by the new run will lose its cached results. This will allow faster runs of experiments, especially in the case where you are making minor adjustments to your experiment. Any data available from previous runs will be persisted in your partial run: Previous results, coming from the previous run's cache, are used and there's no need to run everything right from the top of the experiment down to the module being changed.
Note that if you are selecting a module, but a module it depends on has not been run yet, then that latter module will need to be run.
The same applies to modules which have already run, but have non-deterministic behavior (for example, the "Import Data" module): if these have to run before the selected module, they will run again. However, regardless of previous runs, you can disable re-runs of the module and use cached results (when available). To do so, click on the module (e.g. "Import Data"), go to the Properties pane on the right, and check the box "Use cached results" .
In the example below (Figure 3-1), the module "Convert to CSV" has been selected and is about to run. Notice that it can only run with the results of the "Split Data" module, which has not run yet. Therefore, "Split Data" is also highlighted because it will run. Notice also that "Split Data" depends at the very top on "Import Data", a module which has non-deterministic behavior. In this example, we have checked the box "Use cached results" for "Import Data" (example on Figure 3-2); therefore, it will not run again.
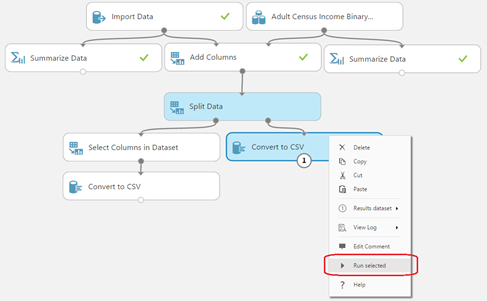
Figure 3-1: Before running the selection, all modules which will be run are visually indicated.
In this case, the module "Import Data" at the top is using cached results.
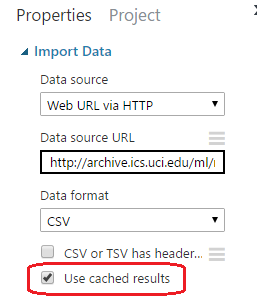
Figure 3-2: "Import Data" will run only if cached results are not available.
To illustrate the difference, see the next example (Figure 4), where the "Import Data" module does not have the "Use cached results" box checked: Even though "Import Data" and "Add Columns" modules have already run, they will run again. Also, the "Summarize Data" module on the left, which depends on "Import Data", would not be valid anymore and would need to run again to get the correct results.
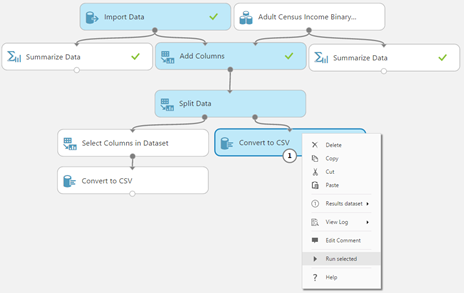
Figure 4: In this example, the module "Import Data" at the top is not using cached results.
Use Case: Don't Get Blocked by Errors
While creating experiments, its sometimes the case that parts of the experiment are failing, but they don't need immediate attention. In a full run of the experiment, the failing modules would potentially stop the execution of the rest of your experiment. The "Run selected" option allows you to keep working on your module and ignoring the failing modules, giving you the flexibility to focus on a particular section of your graph. For instance, in Figure 5, the top left part has failed. This doesn't stop you from being able to run just the part of the experiment you're interested in, i.e. the bottom "Execute R Script" module.
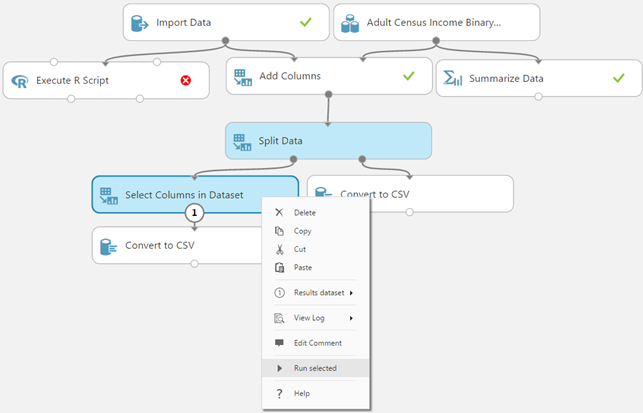 Figure 5: Even though a part of the experiment has failed, you can continue
Figure 5: Even though a part of the experiment has failed, you can continue
editing your experiment and running a subset of it
Use Case: Avoid Side Effects
Some modules can have impact that you do not yet want them to have. For instance, a module which may take too long to run, or a module that writes data to storage, etc. You may just not yet be ready to run that module since you aren't fully done with the experiment, but you've added them for completion later. Running just the selection of modules which actually matter to you right now can help you make faster progress.
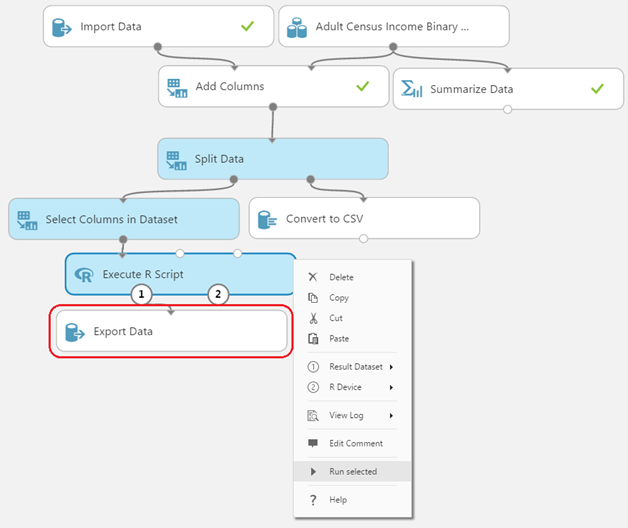
Figure 6: The "Export Data" module will write to the storage you specify. In this case, running just the
"Execute R Script" module avoids having to run the "Export Data" module.
In summary, the ability to run only selective portions of experiments should help make users of Azure ML even more productive.
If you have any thoughts, feedback or suggestions about this new capability, please share them with us below.
Mickaël