Now Available: Speaker & Video APIs from Microsoft Project Oxford
This post is by Ryan Galgon, Senior Program Manager, Microsoft Technology and Research
Last month we announced new features for Microsoft Project Oxford machine learning APIs, enabling developers across different platforms to easily add intelligence to applications without having to be AI experts. Project Oxford is just one instance of a broader class of work Microsoft is pursuing around artificial intelligence, and our vision for more personal computing experiences and enhanced productivity aided by systems that increasingly can see, hear, speak, understand and even begin to reason.
Today, the Speaker Recognition APIs and Video APIs are available in public preview, and the Custom Recognition Intelligence Service (CRIS) is accepting invites at www.ProjectOxford.ai.
CRIS offers a way to customize the Microsoft speech recognition system to a particular vocabulary, environment, and/or user population. The Video APIs makes it easy to analyze and automatically edit video using Microsoft video processing algorithms to detect and track faces in video, detect when motion has occurred in videos with stationary backgrounds, and smooths and stabilize videos.
In the rest of this post we’ll share some more background on the new Speaker Recognition APIs, including how to use them and the technology behind them.
Example Use Case: Stronger Authentication with Speaker Recognition APIs
The Speaker Recognition APIs helps to recognize users and customers (speakers) from their voice. While Speaker Recognition APIs are not intended to be a replacement for stronger authentication tools, they do provide additional authentication measures to take security to a next level. Another way Speaker Recognition APIs can be used is to enhance customer service experience by automatically identifying the calling customer without the need for an agent to conduct a question and answer process to manually verify a customer’s identity.
Our goal with Speaker Recognition is to help developers build intelligent authentication mechanisms capable of balancing between convenience and fraud. Achieving such balance is no easy feat. Ideally, to establish identity, three pieces of information are needed:
- Something you know (password or PIN).
- Something you have (a secure key pad, mobile device or credit card).
- Something you are (biometrics such as voice, fingerprint, face).
Voice has unique characteristics that can be used to help identify a person. The past few years witnessed tremendous improvement in the performance of speaker recognition systems. [1][3]
There are two phases when using the Speaker Recognition APIs: enrollment and recognition. During enrollment, a speaker’s voice is recorded and a number of features are extracted to form a unique voiceprint that uniquely identifies an individual. These characteristics are based on the physical configuration of a speaker's mouth and throat and can be expressed as a mathematical formula. During recognition, the speech sample provided is compared against the previously created voiceprint.
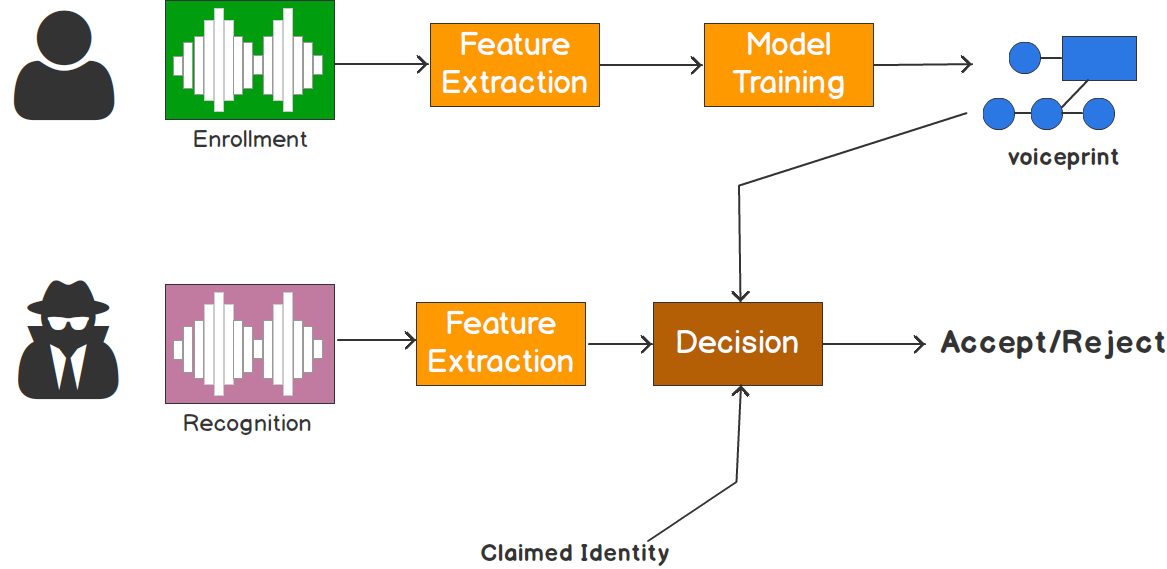
Speaker Recognition Phases (compiled by the author based on a slide from Douglas Reynolds)
Speaker Recognition provides state-of-the-art algorithms that enables recognition of a human’s voice from audio streams. It comprises two components: speaker verification and speaker identification.
- Speaker Verification can automatically verify and authenticate users from their voice or speech. It is tightly related to authentication scenarios and is often associated with a pass phrase. Hence, we opt for text-dependent approach, which means speakers need to choose a specific pass phrase to use during both enrollment and verification phases.
- Speaker Identification can automatically identify the person speaking in an audio file given a group of prospective speakers. The input audio is paired against the provided group of speakers, and in case there is a match found, the speaker’s identity is returned. It is text-independent, which means that there are no restrictions on what the speaker says during the enrollment and recognition phases.
Speaker Recognition Technology Overview
Modern systems, including the developed APIs, use the so-called i-vector approach. Most work in the literature focused on the verification scenario, either text-independent in the NIST evaluations or text-dependent associated with pass-phrase(s) e.g. in the RSR database. Both APIs were thoroughly benchmarked on standard tasks and in the case of identification on an internal large-scale task in a meeting scenario (with and without rejection). In the verification tasks the results obtained are competitive with the best published number. For identification, high precision (above 90%) is obtained at around a 5% rejection rate.
In the following paragraphs we briefly summarize different technology components and provide references for the interested reader.
We will briefly outline the basic blocks of an i-vector speaker recognition system. We will focus on verification but identification adds only simple modifications to the scoring stage.
- Feature Extraction: Feature extraction generates a vector that represents the speech signal every 10 ms. The Mel Frequency Cepstral Coefficients (MFCC) are widely used for speaker and speech recognition. In the API we use a robust, proprietary version of the MFCC. This is comparable to 60-dimensional MFCC that is widely used for speaker recognition and shows improved performance in noisy conditions.
- Unsupervised Training: This step is referred to unsupervised training because it does not use the speaker labels in any sense. Rather, it is used to characterize the acoustic space using a large Gaussian mixture model and the speaker (and channel) space using the total variability matrix (T). Building a universal background model (UBM) is very well-known from early works on speaker recognition and is constructed from large amount of data using standard GMM training techniques. The T matrix, on the other hand, has been recently studied in the context of the so-called joint factor analysis (JFA). We refer the reader to [1] for an introduction. Using both the UBM and T, an utterance can be mapped into a fixed dimensional space (typically in the order of several hundreds). In this space discriminant transforms are constructed and enrollment and scoring are performed.
- Supervised Training: In the training set, once UBM and T are constructed, each utterance is mapped into a fixed dimensional vector together with the speaker label. These (vector, label) pairs are used to construct a probabilistic linear discriminant analysis model (PLDA). (Think of this as a probabilistic version of linear discriminant analysis that helps to decompose the speaker and channel variability.) Details of how to train a PLDA and use it in scoring can be found in [2]. It is very important to train a PLDA model to encounter the same variability that will be seen in enrollment and testing (for example, channel variability and phonetic variability for text-dependent verification). This leads to very good performance in practice.
- Enrollment/Testing: All the above steps are done using a large speaker database that is different from the speakers that will be enrolled in the system. In fact, all the above models are trained on thousands of hours of speech and provided with the API. In the enrollment phase, each speaker that will use the system says several instances of a short phrase (for text-dependent verification) or a relatively long, e.g. one minute, segment for text-independent verification/identification. This input is used to construct the speaker model in the i-vector space. During testing, the test utterance is mapped to the i-vector space and is compared to the speaker model to make a decision.
We hope many of you will get started on these APIs soon. If you’d like to see similar posts on other technologies used in Project Oxford let us know in your comments below.
Ryan
References:
[1] Najim Dehak, Patrick Kenny, Pierre Dumouchel, Reda Dehak, Pierre Ouellet, «Front-end factor analysis for speaker verification » in IEEE Transactions on Audio, speech and Language Processing 2011.
[2] Simon J.D. Prince, James H. Elder, «Probabilistic linear discriminant analysis for inference about identity » in Proceedings ICCV 2007.
[3] Anthony Larcher, Kong Aik Lee, Bin Ma, Haizhou Li, «Text-dependent speaker verification: Classifiers, databases and RSR2015» in Speech Communication, (60), 2014.