Choosing a Learning Algorithm in Azure ML
This post is by Brandon Rohrer, Senior Data Scientist at Microsoft.
Machine Learning libraries seek to put state-of-the-art tools into the hands of data scientists, offering dozens of algorithms, each with their strengths and weaknesses. But choosing the right ML algorithm can be daunting for both beginner and experienced data scientists alike. The nature of the data partially drives the decision, constraining the choice to a class of algorithms, say, classification or regression. But often the final choice of algorithm is a black-box mixture of trial-and-error, personal experience and arbitrary selection.
To help you navigate through these choices, we have created a handy guide. We offer a Question-and-Answer-directed walk through a flowchart and make an algorithm recommendation for any of you bewildered data scientists out there. A few subtle aspects of data and features that may drive algorithm selection are explained in the footnotes at the bottom of this post.
Download the guide by clicking here or on the image below:
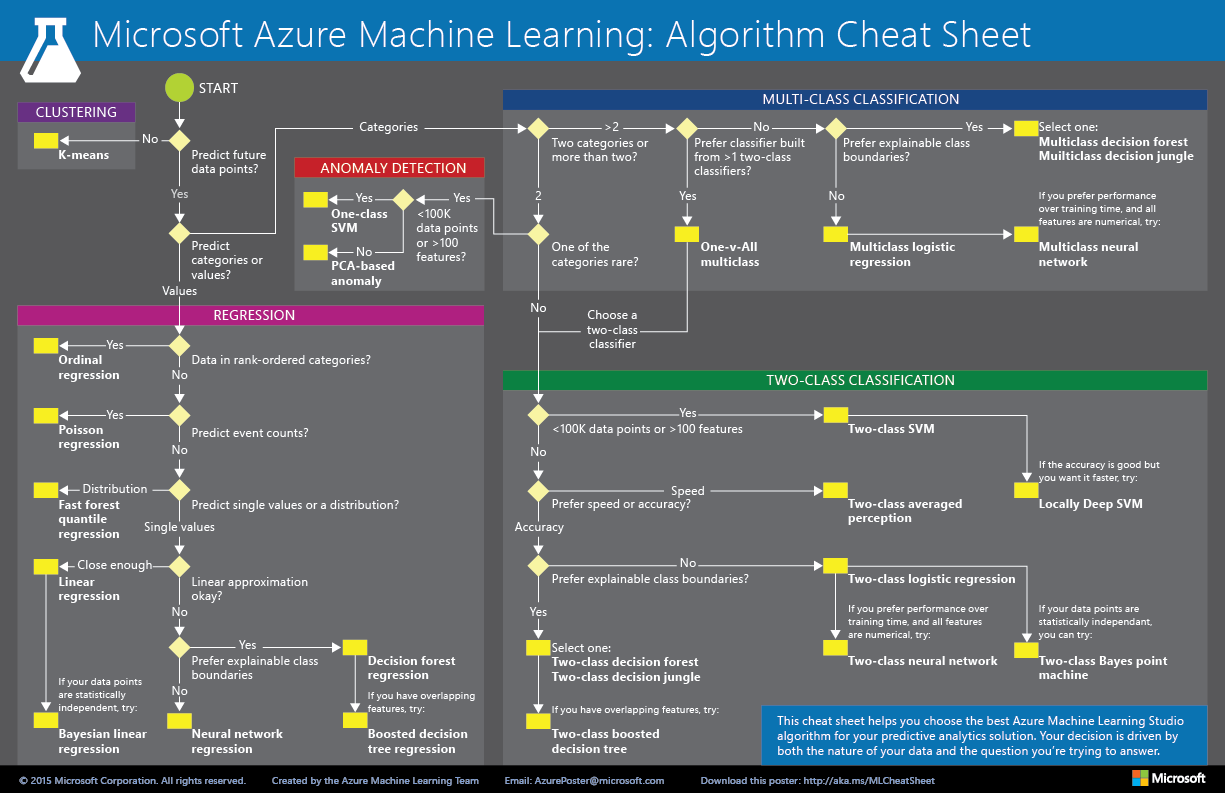
We hope the guide recommends an algorithm that proves to be a useful starting point for solving your problem. Also note that the suggestions we offer are rules of thumb – some of these rules can be bent, and others flagrantly violated. So do not be afraid run a head-to-head competition between several different algorithms on your data. There is simply no substitute for understanding the principles of each algorithm and the system that generated your data.
If you have suggestions for improving this guide, or perhaps recommendations for other similar guides you would like to see, we would love to hear from you via the comments below or in our Feedback Forum.
Brandon
Follow me on Twitter
Footnotes:
-
Every ML algorithm has its own style or inductive bias. For a specific problem, several algorithms may be appropriate and one algorithm will be a better fit than others. But knowing which will be the best fit beforehand is not always possible. In cases like these, several algorithms are listed together in the cheat sheet. An appropriate strategy would be to try one algorithm, and if the results are not yet satisfactory, try the others. Here’s an example from the Azure Machine Learning Gallery of an experiment that tries several algorithms against the same data and compares the results: Compare Multi-class Classifiers: Letter recognition.
There are three main categories of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
In supervised learning, each data point is labeled or associated with a category or value of interest. An example of a categorical label is assigning an image as either a ‘cat’ or a ‘dog’. An example of a value label is the sale price associated with a used car. The goal of supervised learning is to study many labeled examples like these, and then to be able to make predictions about future data points – for example, to identify new photos with the correct animal or to assign accurate sale prices to other used cars. This is a popular and useful type of machine learning. All of the modules in Azure ML are supervised learning algorithms except for K-means Clustering.
In unsupervised learning, data points have no labels associated with them. Instead, the goal of an unsupervised learning algorithm is to organize the data in some way or to describe its structure. This can mean grouping it into clusters, as K-means does, or finding different ways of looking at complex data so that it appears simpler.
In reinforcement learning, the algorithm gets to choose an action in response to each data point. It's a common approach in robotics, where the set of sensor readings at one point in time is a data point, and the algorithm must choose the robot’s next action. It is also a natural fit for Internet of Things (IoT) applications. The learning algorithm also receives a reward signal a short time later, indicating how good the decision was. Based on this, the algorithm modifies its strategy in order to achieve the highest reward. Currently there are no reinforcement learning algorithm modules in Azure ML.
Bayesian methods make the assumption of statistically independent data points. This means that the unmodeled variability in one data point is uncorrelated with others, that is, it can’t be predicted. For example, if the data being recorded is number of minutes until the next subway train arrives, two measurements taken a day apart are statistically independent. Two measurements taken a minute apart are not statistically independent – the value of one is highly predictive of the value of the other.
Boosted decision tree regression takes advantage of feature overlap, or interaction among features. That means that, in any given data point, the value of one feature is somewhat predictive of the value of another. For example, in daily high/low temperature data, knowing the low temperature for the day allows one to make a reasonable guess at the high. The information contained in the two features is somewhat redundant.
Classifying data into more than two categories can be done by either using an inherently multi-class classifier, or by combining a set of two-class classifiers into an ensemble. In the ensemble approach, there is a separate two-class classifier for each class – each one separates the data into two categories: “this class” and “not this class.” Then these classifiers vote on the correct assignment of the data point. This is the operational principle behind the One-v-All Multiclassclassifier.
Several methods, including logistic regression and the Bayes point machine, assume that the boundaries between classes are approximately straight lines (or hyperplanes in the more general case). Often, this is a characteristic of the data that you don’t know until after you’ve tried to separate it, but it’s something that typically can be learned by visualizing beforehand. If the class boundaries look very irregular, stick with decision trees, decision jungles, support vector machines, or neural networks.
Neural networks can be used with categorical variables by creating a dummy variable for each category and setting it to 1 in cases where the category applies, 0 where it doesn’t.