Microsoft Machine Learning Hackathon 2014
This blog post is authored by Ran Gilad-Bachrach , a Researcher with the Machine Learning Group in Microsoft Research.
Earlier this summer, we had our first broad internal machine learning (ML) hackathon at the Microsoft headquarters in Redmond. One aspect of this hackathon was a one-day competition, the goal of which was to work in teams to get the highest possible accuracy on a multi-class classification problem. The problem itself was based on a real world issue being faced by one of our business groups, namely that of automatically routing product feedback being received from customers to the most appropriate feature team (i.e. the team closest to the specific customer input). The data consisted of around 15K records, of which 10K were used for training and the rest were split for validation and test. Each record contained a variety of attributes including such properties as device resolution, a log file created on the device, etc. Overall, the size of each record was about 100KB. Each record could be assigned to one of 16 possible feature teams or “buckets”. Participating teams had the freedom to use any tool of their choice to extract features and train models to map these records automatically into the right bucket.
The hackathon turned out to be a fun event with hundreds of engineers and data scientists participating. Aside from being a great learning experience it was also an opportunity to meet other people in the company with a shared passion for gleaning insights from data using the power of ML. We also used this event as an opportunity to gain some wisdom around the practice of ML, and I would like to share some of our interesting findings with you.
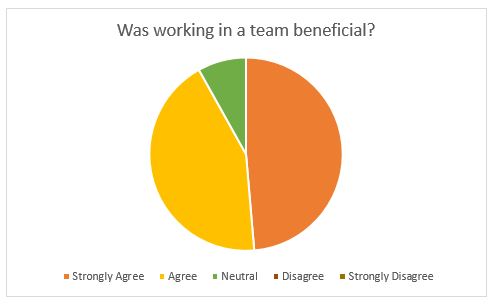
We had more than 160 participants in the competition track. We asked them to form teams of 1-4 participants and ended up with 52 teams. Many participants were new to the field of ML and therefore, unsurprisingly, 11 of 52 teams failed to submit any meaningfully significant solution to the problem at hand. However, when we looked closer at the teams that dropped out, we found out that all teams with just a single member had dropped out! While it is quite possible that the participants who showed up without a team were only there for the free breakfastJ, when we surveyed our participants and asked them whether working in teams was beneficial, a vast majority, well over 90%, agreed or strongly agreed with the statement.
 We also found out that there were two strategies for splitting the problem workload within teams. Most teams assigned specific roles to their team members with 1 or 2 participants working on “feature engineering”, while others tried different learning algorithms, or ramped up on the tools, or created requisite “plumbing”. The other strategy we saw teams use was to have each participant try a different approach to address the problem, i.e. build multiple end-to-end solutions, with each team member using a different strategy, and later zooming into most promising of their different approaches.
We also found out that there were two strategies for splitting the problem workload within teams. Most teams assigned specific roles to their team members with 1 or 2 participants working on “feature engineering”, while others tried different learning algorithms, or ramped up on the tools, or created requisite “plumbing”. The other strategy we saw teams use was to have each participant try a different approach to address the problem, i.e. build multiple end-to-end solutions, with each team member using a different strategy, and later zooming into most promising of their different approaches.
We did not notice significant difference in the performance of teams based on the strategy they used to split the workload. However, there was evidence that it was important to be working in teams and to be thoughtful about how to split a given ML challenge between team members. Assigning roles and having clarity on what tools to use were critical considerations.
Over the course of the day, teams were allowed to make multiple submissions of their candidate solutions. We scored these solutions against the test set but these scores were revealed only at the end of the event, when winners were announced. There were more than 270 submissions made, overall. It is interesting to look at these submissions when they are grouped together – the graph below shows all the submissions as blue dots, with the X-axis representing accuracy on the training set and the Y-axis representing accuracy on the test set.
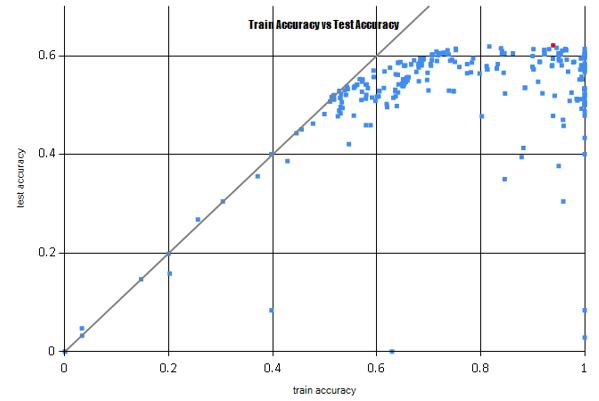 Most submissions with a training accuracy < 0.55 had a good match between the train and test accuracy (the gray line shows the equal train-test accuracy). However, the test-accuracy keeps improving even when the gap between the train and test accuracy becomes ridiculously large. For example, the winner (the red dot) had a training accuracy of 94% and test accuracy of 62%.
Most submissions with a training accuracy < 0.55 had a good match between the train and test accuracy (the gray line shows the equal train-test accuracy). However, the test-accuracy keeps improving even when the gap between the train and test accuracy becomes ridiculously large. For example, the winner (the red dot) had a training accuracy of 94% and test accuracy of 62%.
Next, let us look at the behavior of the algorithms used by the different teams in this particular competition. We are able to understand and analyze these algorithms only because we had asked participants to add a short description to every submission they made (i.e. akin to textual comments provided by software developers each time they update code in a source control system).
It is interesting to see these algorithms plotted on a graph (below). The submissions with a large gap between training and test were mostly using boosted trees. This makes sense since boosting works by aggressively reducing the training error. Additionally, note that 4 of the leading teams – each of who were among the top 15 submissions, overall – were using boosted trees to solve this particular problem.
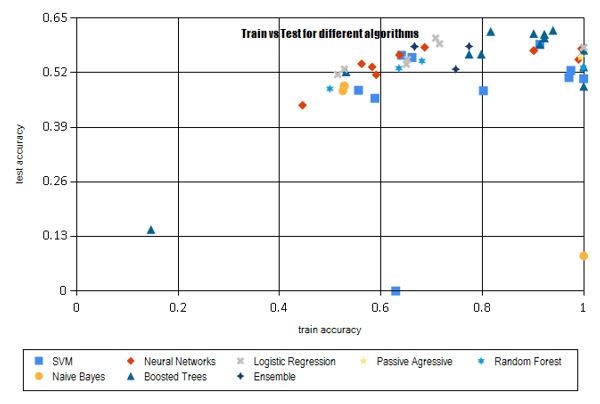 We have seen similar patterns in other cases too, and boosted trees are a strong candidate on many ML tasks. If you have some special or temporal structure to the data, it may be easier to encode it using neural-nets (although exploiting it may be non-trivial). However, if there is no structure to the features or if you have a limited amount of time to spend on a problem, one should definitely consider boosted trees.
We have seen similar patterns in other cases too, and boosted trees are a strong candidate on many ML tasks. If you have some special or temporal structure to the data, it may be easier to encode it using neural-nets (although exploiting it may be non-trivial). However, if there is no structure to the features or if you have a limited amount of time to spend on a problem, one should definitely consider boosted trees.
Beyond the numbers and the graphs, what was cool about this event was that hundreds of engineers got a chance to work together and learn and have some plain fun – do check out our quick 1 minute time-lapse video of this, our inaugural ML hackathon.
With over half our hackathon participants indicating that they were new to ML, it was great that they showed up in such big numbers and did as well as they did. In fact one of our Top 5 teams comprised entirely of summer interns who were new to this space. If some of you out there are emboldened by that and wish to learn ML for yourself, you can start at the Machine Learning Center – there are videos and other resources available, as well as a free trial.
Ran
Follow my research