Twelve Methods of Flipping your Innovation/Operations Position
Think about the typical bell curve most SAP and other LOB IT organizations face today when it comes to investing in innovation (strategic or incremental), core IT operations, and operational excellence. I call this the “Innovation/Operations Spectrum.” In short, most IT organizations wind up focusing on core operations at the expense of innovation (at one end of the curve) and operational excellence (at the other end). Thus the bulk of IT budgets for Average Joe Company are tied today to ongoing or "core" operations like we see in the figure below:
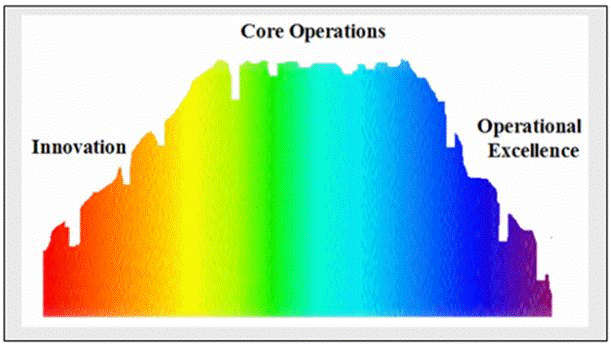
With all that cash getting dumped into keeping the IT machine running, there’s little left to innovate on the front end or pursue operational excellence initiatives on the back. Why? The fact is that we’re faced with a whole lot of realties today that, together, make it difficult for companies to reverse or “flip” their IT operations/innovation budget realties. To fix the IT/business relationship and move from order takers to transformation leaders, IT needs to do some things differently. I lump these into business, IT, and leadership buckets or "to do's":
Business To Do's
- IT needs to help business process and functional owners rethink how the company does business leveraging best, proven, and common technology solutions and practices to streamline the business of doing business.
- IT needs to help the business work in a manner that befits them: a geographically distributed & centralized organization requiring smarter methods of collaboration and communication front-ending a core set of secure and accessible-from-anywhere-and-any-device business processes.
- IT needs to provide the platforms and processes necessary for the business to run its LOB systems in a way that's adaptable to changing business requirements, geographic realities, compliance and regulation mandates, and so on.
IT To Do's
- IT needs the ability to better manage the application portfolio and deploy business applications in a manner that enables low acquisition costs as well as low ongoing total platform management and maintenance costs, all the while increasing the value and health of the organization's application portfolio.
- Infrastructure teams need to deploy business applications in a way that initially minimizes and pulls costs out of their computing platforms and tools, freeing dollars for innovation and operational excellence.
- Developers and functional experts need the necessary tools, time, and sandbox access to not only pilot and deliver but accelerate innovative business solutions which in turn enable the "agile enterprise."
Leadership To Do's
- CIOs need to intellectually stimulate the IT organization and its business stakeholders to take smart computing platform, LOB, device, and other risks.
- Business leaders need to buy into the premise that technology cand application onsolidation and simplification are good for them and their applications and business processes.
- IT organization design and staffing leaders need to create purposeful and lean post-go-live organizations enabled through automation and management-by-exception practices to more easily achieve operational excellence.
- Management must incentivize and encourage the kind of teamwork and behaviors that reinforce a business/IT culture characterized as effective, rewarding, and synergistic.
Amid all these realities is where we, Microsoft, are stepping back and figuring out where both incremental changes and broad innovations might be injected here and there to make a difference. To be most effective, and really raise the bar compared to others who have already found a better balance between operations and innovation, we understand the need to help our customers do it better… Our goal is to “flip” the continuum so that lower core operations costs enable greater opportunities for innovation and operational excellence like I’ve described in the figure below.
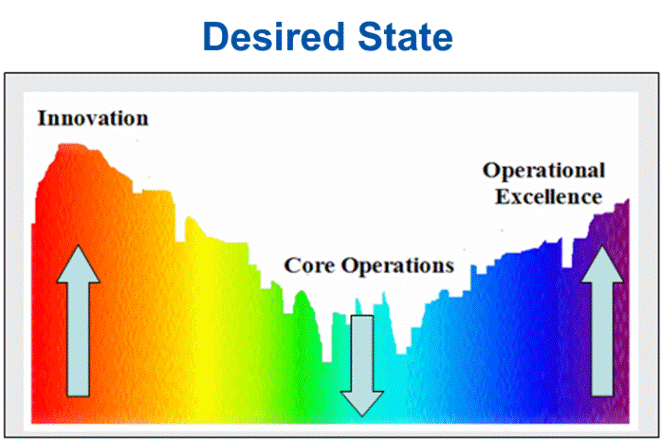
At this point we're busy helping paint a vision and develop roadmaps with our customers to navigate to a new innovation/operations position – a better cost model. As we work together to establish a roadmap to transition from average to exceptional, we're also focused on the reality that simply having a roadmap is really not enough. We also need to help our customers manage and coordinate the speed with which we navigate this roadmap so as to leave no one (very few?) behind. But the roadmap is critical and often includes items like the following (many of which should be familiar). Each one of these represent a pretty major initiative or project by itself, intended to suck costs out of operations. Which ones are you already pursuing? Which ones need to be added to your roadmap?
· Identify tax-advantageous financing alternatives. By leveraging cloud service models, moving activities to low-tax areas, adopting factory models, or structuring project teams and support orgs in a particular way, significant tax benefits may be realized; further, CAPEX may become OPEX and so on....
· Identify shadow IT and transition these resources to IT. According to Alinean a few years ago, shadow IT typically accounts for 10-33% of all IT expenditures, representing potentially millions of dollars out of the CIO’s direct control, complicating standardization, application portfolio simplification, integration, and more – across the board. ‘Nuff said.
· Consolidate data centers and IT functions. Collapse multiple data centers into a dual (or similar) data center strategy, addressing HA, DR, performance, and scalability; this is a cost reduction and risk mitigation play that must consider cloud hosting models as well as traditional hosting models.
· Consolidate and rationalize your applications portfolio. Identify business process and application standards and priorities, architectural principles, and so on. Evaluate the application portfolio against a set of factors or considerations spanning user experience, functional fit, performance, strategic alignment, and more, to develop a list of non-standard or non-strategic applications that should be replaced, replatformed, refactored, retired, or further invested in. More importantly, take the necessary steps to actually retire, replatform, or replace those apps!
· Standardize your application platforms in the same way as outlined above, but from a computing platform (HW, OS, database, and integration technologies) perspective. Fewer = simpler = cheaper and better. It’s hard to argue with that kind of math. :)
· Replatform with green in mind. Retire non-standard assets with greener, standardized assets; develop replatforming and migration strategies, particularly those that can replace expensive-to-maintain platforms while providing significant social impact. Remember to measure this green impact!
· Virtualize everything on your way to creating a “future of alternatives” (where you can then pursue new alternatives, including cloud development and hosting alternatives where they make sense) spanning servers, storage, desktops, and so on. Ideally, once standard assets are in place, Hyper-V and other virtualization technologies, and Microsoft Azure and other cloud platforms will give you the agility and flexibility you need to accelerate ‘speed-of-deployment’ and ‘speed-of-change’ benefits.
· Own less/Own nothing. That is, transition workloads to cloud and other service models by developing strategies that might include new sourcing models, co-hosting models, leasing models, and variants of cloud computing models (especially when it comes to hosting non-core applications and the non-production systems like sandboxes and demo systems that support all of your production systems).
· Automate operations by pursuing lights out or near-LO models. Consider adopting a cloud-based management service to pay-as-you-go. Develop and implement strategies and tools for automating SAP systems management and operations; automate to proactively identify and track performance, capacity, and availability trends.
· Rationalize your Staffing Models in light of the above changes. One of the worst things you can do is to transform your IT environment without transforming how, who, and what manages that environment.
· Conduct intentional Load Testing and Stress Testing to validate that both your on-premises and cloud-based applications can indeed scale and shrink in the wake of changing workloads (an insurance policy). Consider cloud-based performance management and load testing capabilities to avoid investing in tools that are realistically used only one to four times a year.
· Invest and reinforce use of a Knowledge Repository. Create an accessible and well-maintained KM repository to reduce time to resolution, enable more rapid troubleshooting, and ultimately reduce unplanned downtime and facilitate effective staffing/sourcing models; a cost and risk play.
Together, these initiatives, projects, and practices will help save enough money to fund not only these projects themselves but also allow some of the savings to fall to the bottom line. There it can be used to further reverse the operations/innovation position, increase stockholder wealth, and more….
What else am I missing? Share your thoughts with me as usual: george.anderson@microsoft.com
george