Sam Guckenheimer's DevOps journey Q & A (English/日本語)

(注) 本記事の英語は、Sam Guckenheimer の書いたもの以外は、私 (牛尾) が書いていますので、英語で書いてあることと、日本語で書いてあることのニュアンスが異なることがあります。
I presented the DevOps journey in Microsoft in Japan. This presentation is originally created by Sam Guckenheimer. I translated it into Japanese, a lot of Japanese loves the story. After the session, I've got some questions from audience. I could meet with Sam in Seattle, so I'd like to share the answers. 先日の Scrum Gathering で、「Microsoft が実践した Scrum 導入 7 年間の旅そして DevOps」 という講演がご好評をいただき、著名な PublicKey 様にも取り上げていただきました。 マイクロソフトにはチーム開発をサポートしてくれる Visual Studio Team Services というサービスがあります。この開発を行っているプロダクト マネージャである Sam Guckenheimer 氏の講演を日本語にし、若干新しい情報を追加しているものです。 その後参加者の方からいくつかの質問をいただいていました。シアトルでたまたま彼と再会することが出来たので、質問に答えてもらいました。その結果をシェアしたいと思います。 |
|
1. 1 week duration after sprints.スプリント終了後の 1 週間について |
|
 Tsuyoshi Tsuyoshi |
You do 3 weeks sprint then have a week to deploy production. What do you do during the one week? I guess Canarying.Who is in charge of it? QA Ops or feature team? あなたのチームでは、3 週間のスプリントの後、デプロイまでに1週間の期間があります。 その間何をしているのでしょうか?きっとカナリアテストとかじゃないかな?と思います。 まだ、誰がそれを実施していますか?QAですか、Opsですか?それともフィーチャーチームですか? 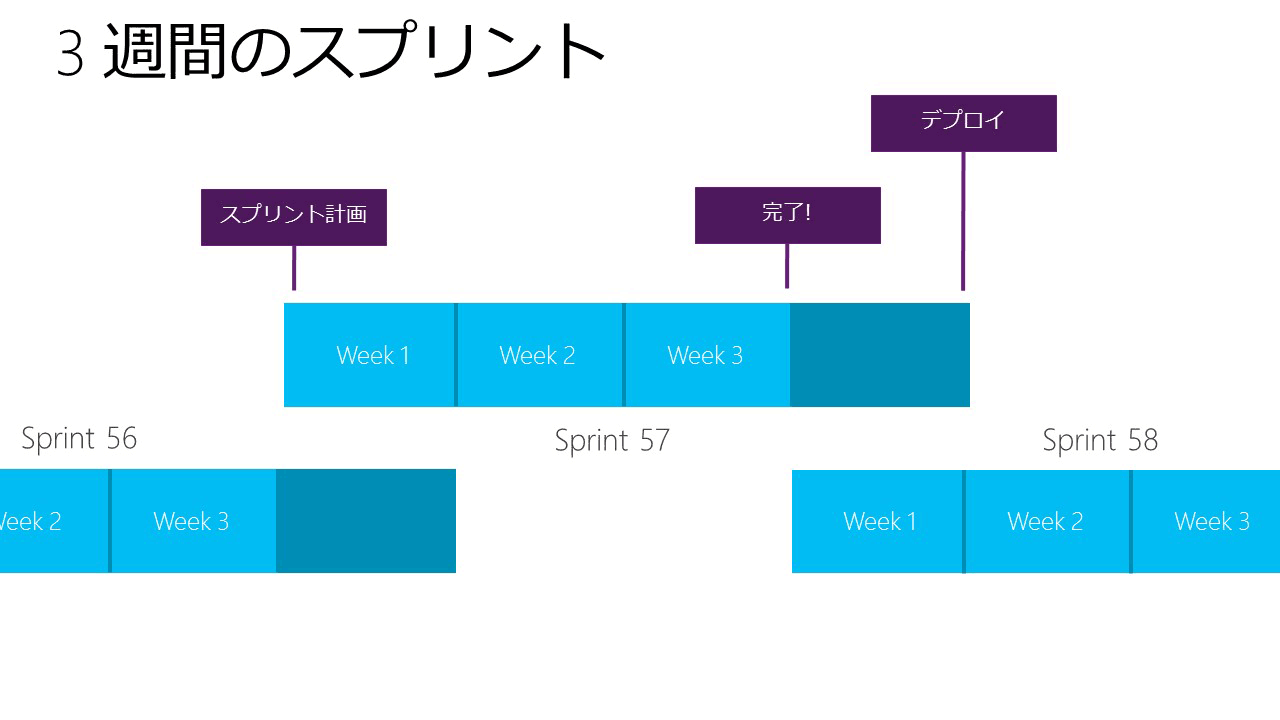 [Fig 1. 3 week sprints] [Fig 1. 3 week sprints] |
 Sam Sam |
The slide is oversimplified. (We used to have a simpler process when we were only in one data center and one scale unit.) We complete deployment across eight data centers within one week of the sprint end. We start canarying during week 3 of the sprint. The release management is automated across a series of (currently) 4 rings, for exposure control. The engineering team does the release, with one release manager who coordinates. For example, this was the sequence for the last deployed sprint: このスライド単純化しすぎています。(私たちはデータセンターが 1 つで、スケール ユニットが 1 つだったころは、より単純なプロセスを使っていました。) 私たちは、スプリントが終わったら、1 週間で 8 つのデータンセンターにデプロイを完了させていました。私たちはカナリア テストをスプリントの 3 週目からスタートさせています。 リリース マネジメントは、連続した (いまのところ) 4 つのリングをまたいで自動化されています。これは、公開することをコントロールするためです。エンジニアリング チームがリリースをおこなっています。1 人のリリース マネージャがコーディネイトしています。 例えば、前回のデプロイ スプリントのシーケンスです。
"SU" means Azure Scale Unit. "PPE" means Pre-Production Environment."SU0" is the primary production canary, where we work. Note that Ring 2 has the most public instances. The sprint ended on Friday 1/22. "SU"は、Azureスケールユニットのことです。"PPE"は、プリプロダクション環境です。"SU0" は、私たちが使っている主要なプロダクション カナリア テストのスケールユニットです。リング 2 は、最も公開されたインスタンスであることに気をつけてください。スプリントは、1/22 の金曜日に終わりました。 |
2. Health Modelヘルス モデル |
|
| Tsuyoshi |
How do you route the alert automatically? どうやって、アラートを自動でルーティングしていますか? 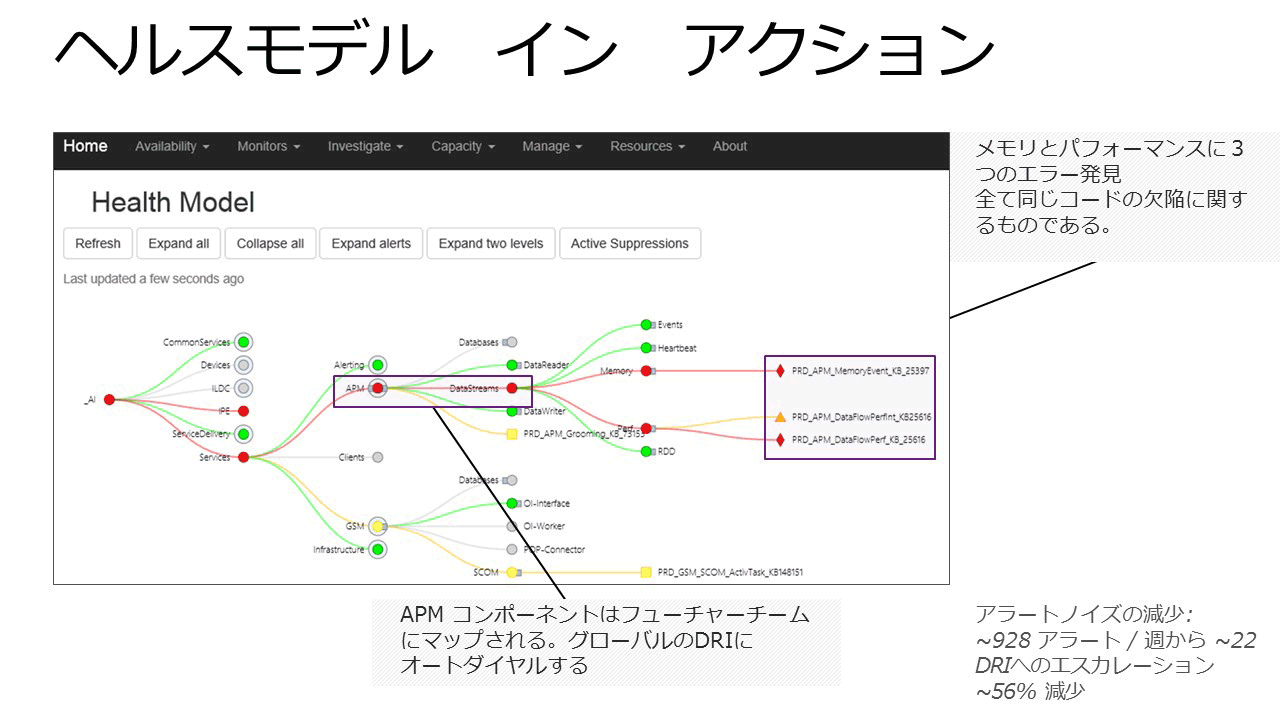 [Fig3. Health Model in Action] [Fig3. Health Model in Action] |
| Sam |
Typically by email, SMS and voice call. As soon as the recipient acknowledges receipt, it is considered delivered. There are a series of routing rules based on acknowledgement by the recipient. For example, for mobile phones on “quiet hours” or “do not disturb”, we have redial rules to punch through the call-blocking. E-Mail, SMS, ボイスコールです。受取人が受け取ったら、配達されたものだと考えています。ここでは、いくつかのルーティングルールがあります。これは、受取人の受け取った様子を基にしています。例えば、携帯電話が "quiet hours (静かにしている時間)" や"Do not disturb (邪魔しないで)" になっていると、コール ブロッキングにたいして、リダイヤル ルールを実行します。 |
| Tsuyoshi |
Can we use Helth Model system on Azure or VSTS? このヘルスモデルを、Azure や VSTS(Visual Studio Team Services) で使えますか? |
| Sam |
No. This is very specific to our code base and org structure. I hope we’ll be able to deliver a more general solution at some point. いいえ。これは、私たちのコードベース、私たちの組織の専用です。私はより一般的なソリューションをどこかの時点で ご提供できるように望んでいます。 |
3. Managing backlogs among the multiple teams複数のチームでのバックログの管理 |
|
| Tsuyoshi |
You must have multiple teams among the visual studio team services team. How do you keep the consistency among the backlogs? Visual Studio Team Services のチームでは、複数のチームがあると思います。どのようにバックログの一貫性を保っているのですか? |
| Sam |
We have one backlog. It is hierarchical, starting with epics, including one for “engineering investments,” and kept in our own VSTS project. 私たちは単一のバッグログを共有しています。それは、階層的に整理されています。エピックから始めます。エピックには、"エンジニアリング的な投資(※)"を含んでいます。そしてそれを私たちの VSTS プロジェクトに入れています。 ※engineering investments は、技術的負債の解消のことを指すと思われます。各種のリファクタリング、新しいアーキテクチャや仕組みの導入だと思われます。 |
| Tsuyoshi |
How do you prioritize the backlog items among the team? チーム間でのバックログの優先順位付けをどのように行っていますか? |
| Sam |
Every six months we set a plan at the epic level on the business objectives we want to achieve (“the needles we want to move”) and how we will measure these, which will include a lot of custom telemetry typically." We will also adjust the number of crews per epic area at this time."The epic owner will work with the crews on the experiences in support of these goals and break these down in the backlog. 6 ヵ月毎にエピックレベルのビジネス目的の計画をしています。それは、私たちが達成したいこと、("私たちが進みたい方向性")そして、どのようにそれを測定するのか? これは、多くのカスタム テレメトリが含まれます。" 私たちはこの時点でエピックのエリア毎に、クルーの数を調整します。エピックのオーナーは、経験豊かなクルーと共に、これらのゴールの助けを得て、バックログに落としていきます。  [Fig 4. Planning horizons] [Fig 4. Planning horizons]At the start of every sprint, it is up to the feature crew (scrum team) to pull the right items from the backlog that it thinks represent the next hypotheses and experiments to move the needles. At the end of the sprint, the team reports how they have done, including an update on the key metrics. Roughly every three sprints (sometimes more), all of the leads meet. 全てのスプリントのはじめに、フィーチャークルー (スクラムチーム) が、適切なアイテムをバックログからとってきてきます。 それは、ゴールを達成するための次の仮説と実験を表していると考えています。スプリントの最後で、チームはどのように、やったのかをキーメトリクスとともに報告します。 大体 3 スプリント毎です。 (時にはそれ以上に) 全てのリードが会うようにしています。 |
4. Policy of refactoring among the multiple teams複数チーム間でのリファクタリング ポリシー |
|
| Tsuyoshi |
You must share the code base among the teams. Do you have some conflict about the refactoring policy among the teams? If so, how do you solve it? コードベースをチーム間でシェアしていると思いますが、チーム間でリファクタリングのポリシーが衝突することはありませんか?もし、そうならどうやって解決していますか? |
| Sam |
One of the epics we plan for is around Engineering, which includes shared services, frameworks, etc. We decide how much to invest in this area and prioritize these items similar to others. Typically, code will be refactored when we make the judgment call that not refactoring is more expensive than refactoring. When we revisit old code, of course we refactor. エピックのうちの 1 つが、エンジニアリングに関するものです。それは、共有サービスだったり、フレームワークであったりします。私たちは、どの程度このエリアに投資すべきかを決めて、ほかのバックログアイテムと同じように優先順位付けをします。リファクタリングしないことが、リファクタリングするより高くつく場合は、リンファクタリングします。古くなってしまったコードがあったらもちろん、リファクタリングします。 |
| That's it. Sam is a great guy who published a lot of great books and organize an excellent team of DevOps. When I met him again, he was really pleased that Japanese people enjoyed his story. I really like him and love to share his great idea among the world. いかがでしたでしょうか? 素晴らしい著書を何冊も書いて、素晴らしいチームを作っている Sam に直接会うとわかるのですが、彼は本当にかわいらしい人です。私が彼に日本で彼の DevOps ジャーニーが多くの人に喜んでもらったことを伝えていたのですが、実際に再開したときに、凄く照れながら喜んでくれていました。そして、私がたまに彼がまだ考えてなかったことに関して質問すると、本当に一生懸命うーん。って考えてくれます。アメリカの人らしくなくかなり真面目な感じです。そういう彼の人柄も素敵ですね。これからも彼の素晴らしい経験とアイデアを皆さんにお伝えするお手伝いが出来ればと思います。 |
|
