【DevOps Enterprise 2015 参加レポート】第 2 回 – DockerによるDevOpsソフトウェアサプライチェーンの改善

10 月 19 日 ~ 21 日 San Francisco で開催された DevOps Enterprise 2015 参加レポートの第 2 弾です。お楽しみください。
Immutable Awesomeness - Josh Corman and John Willis
[View:https://www.youtube.com/watch?v=-S8-lrm3iV4:0:0]
https://www.youtube.com/watch?v=-S8-lrm3iV4
Immutable Awesomeness - Josh Corman and John Willis at DevOps Enterprise Summit 2015(動画)
※講演スライドはアップロードされていませんが、本動画の中でスライドが見れるようになっています。
前回のTarget 社の事例は組織導入の事例として興味深いストーリでしたが、技術面のストーリとして面白かった発表をご紹介したいと思います。
講演は 2 部構成になっていて、DevOps とセキュリティの関係について、専門家の Josha Corman さんが、そして、Container 主に Docker が導入されることによる、ソフトウェア サプライチェーンの変革についてお話を DevOpsDays の co-organizer の JohnWillis さんが解説してくれています。
※記事の内容は、当日話された内容、スライドを元に皆様にわかりやすくなるように牛尾が編集したものです。もしかすると間違いがあるかもしれませんが、その際は是非ご報告ください。
Security 専門家から見た DevOps
最初に Josha さんが、Security 専門家の視点から見た DevOps チームがどのように見えるのかを説明してくれました。
#does15: @joshcorman: "how infosec feels about DevOps": h/t @petecheslock pic.twitter.com/ry2Rvf7gmi
— Gene Kim (@RealGeneKim) 2015, 10月 21
もう会場大ウケです。
この図を解説してみますと、海外では技術的にイケてるエンジニアの人を Unicorn と言います。DevOps の素晴らしいユニコーンその技術力で、目がくらむばかりの虹色のアレをしていて、セキュリティの人が掃除しています。
スピード重視で、セキュリティが忘れ去られる現状
彼は、デリバリのスピードばかりが気にされて、セキュリティの事が横に置かれている現状を説明し、「Security is Dead. Long Live Rugged DevOps: IT at Ludicrous Speed」という彼の講演を紹介しています。この資料少し古めですが DevOps とセキュリティを考える上で参考になるので是非ご覧ください。
さらに IoT が広まり、ソフトウェアの適用範囲が広まるなかで、様々な脅威が生まれています。世界に衝撃を与えた The Heartbleed Bug はその一例です。しかし、この脅威に対して現在でも 300,000 ものアプリケーションが未だにパッチを当てる等の対処をしていません。これは、計画されたものではなく、苦痛を伴う作業だからです。
彼はまた、守るべき規定 (code) を定める重要性を説明します。ハイチと、チリの地震の結果を紹介してくれました。ハイチとチリの地震を比べると、M7 のハイチの推定死者数が 230,000 人に対して、M8.8 のチリの方が 279 人で規模の割には少ない被害になっています。これは、チリは直近で地震の経験があり、地震に対する守るべき規定 (code) を作っていたからです。一方、地震のなかったハイチではそんな規定はありませんでした。これが、被害をより大きくしたことが明白です。
A TALE OF TWO QUAKES New York Times に紹介された図をご覧ください。
“ベストを尽くすだけでは十分じゃありません。
何をすべきか知って、その後、ベストを尽くすのです。”
– W. Edwards Deming
トヨタから学ぶ品質の良いものを早く作るコツ
では、どうすればいいでしょうか?
ポイントは「複雑さ」です。ソフトウェアの複雑さは増すばかり。速さばかりが着目されますが、品質、セキュリティ、メンテナンス性、繰り返し可能な性質はイノベーションの阻害ではありません。
彼が例を出したのはトヨタのプリウスとシボレーの比較です。サプライチェーンの観点から見ると、トヨタの圧勝です。なぜ彼らは品質の良いものを早く作れるのでしょうか? (冒頭の動画の 11:09 付近 をご覧ください。比較表を見ることができます。)
キーポイントは、Plant Suppliers の箇所。シボレーが 800 人に対して、プリウスは 125 人しかいないのに、23,294 (Toyota) / 1,788 (Chevy) の売り上げが計上されています。ポイントは、少人数というところです。
【書籍】TOYOTA SUPPLY CHAIN MANAGEMENT
このトヨタからの学びをソフトウェアに持ってくるとどうなるでしょうか?
- 少数の、よりよいサプライヤを使う
- 彼らの最も品質のよいパーツを使う
- どこに、どのパーツを使ったか、どこにつかったかをトラックする
トヨタ生産方式では、Visualize (見える化) も重要です。彼はその Sonatype を使ってデモを実施しました。このツールは、上記の学びにならって、プロジェクトで使われるソフトウェア ライブラリを見える化させるものです。動画では 11:15 - 16:35 付近 でデモを見ることができます。
Impact of software supply chain principles- fewer suppliers, ⬆️quality parts, track and trace @joshcorman #does2015 pic.twitter.com/1Y1yyH6JO5
— Karen Gardner (@karenDgardner) 2015, 10月 21
私も詳しくこのツールを理解できていませんが、こういったものがあると、望まれていないものがどの程度含まれていて、ライセンスを制限されているものがどの程度含まれていて、欠陥率を定義すると、欠陥が発見されたときに、度の程度計画されていないタスクに時間が消費されるかが見える化されます。
Code hygiene (コードの衛生) を保つことが結局安くつくとお話しされていました。
最後に、彼がオススメしたいことはこの 3 つ
- 計画していない仕事を減らすこと
- サービスの中断をほとんど無くすこと
- 迅速な MTTD, MTTR
このために、セキュリティへの考慮は DevOps 環境でも重要になってきますね。
最後に紹介されていたこの名言を
マイクサービスやコンテナの世界がやってきていますが、
運用の痛みは、作られたり、無くなったりしない。
誰かに移動させられるだけ。
- Nick Glabeth
そして、Joshua は「運用の痛みは君が作り出すことはできるよ」と言っています。
“Operational pain can neither be created nor destroyed – only moved to someone else”
– Nick Galbeath
“Well … you can create it … ;) “
– Joshua Corman
John Willis のイミュータブル万歳!
次は John Willis さんのパートです。彼は Docker を始めとするコンテナがソフトウェア サプライチェーンにどういう影響を与えるか?ということを説明してくれました。DevOps Enterprise は技術そのものより、大きな組織がどのように DevOps 化していくか?ということに関するトピックが紹介されています。彼の講演は、エッジの技術者以外にどうやってこのムーヴメントの重要さを伝えるかという事の重要なヒントになるかもしれません。
現在はコンテナや、マイクロサービスへの痛みを伴った移行が起こっているタイミングであることの説明から始めました。
Immutable Infrastructure
彼は、Netfilx の Building with Logos と Immutable Server という 2 つのブログを紹介しています。これらの記事で書かれているのは、ソースコードをビルドするだけではなく、ソフトウェアスタックを丸ごとデプロイできるマシンイメージにしてしまうとう話でした。今までのように一度起動させたサーバーをメンテナンスするのではなく、インフラを変えないようにするというアプローチです。
2002 年の論文 “Why Order Matters: Turing Equivalence in Automated System Administration” で次のように述べられています。
“ 2 つのホストの振る舞いを全く同じにするための、最もコストが安くつく方法は
同じ変更を同じ順番で、両方のホストの実施することである”
“The least-cost way to ensure that the behavior of
any two hosts will remain completely identical is
always to implement the same changes in the same order on both hosts.”
ここから始まった動き、そして、Docker がどのような影響を与えるのでしょうか?
Three Ways of DevOps
本講演の内容は、彼自身が書いたに Docker and the Three Ways of DevOps という記事がベースになっています。素晴らしい記事なので是非読んでみてください。本記事でもそのサマリを日本語で紹介しています。
著名な書籍 The Phoenix Project で Gene Kim が説明していますが、組織でハイパフォーマンスを得るため ”Three Ways of DevOps” というプリンシプルがあります。尚これは、DevOps Cookbook Gene Kim と、John, Joshua などが中心になって執筆中です。DevOps は現在はフィロソフィーみたいになっていますが、より実践的な内容を整理してくれているようです。詳細は上記リンクをご覧ください。
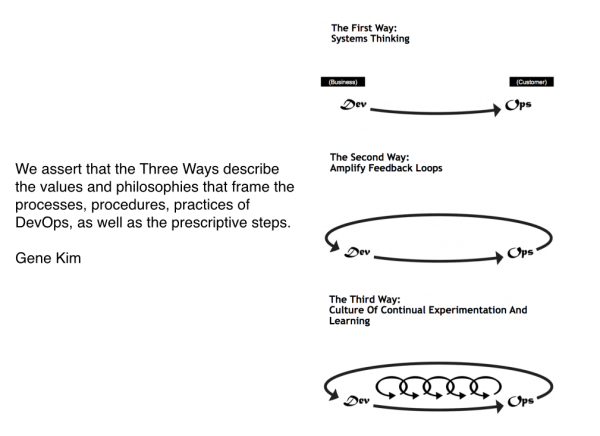
Three Ways of DevOps は、DevOps を実践し、効果を上げるための 3 つの方法について表しています。1 つめは、Dev から Ops への流れを効率化する。つまり、ソフトウェアデリバリを効率化すること。ただ、これだけでは不十分です。2 つめは、Ops から Dev の流れを効率化します。何か問題が発生したときのフィードバックを高速化する流れです。最後に継続的な実験と学びのサイクルを生み出すこと。この 3 つを達成して、DevOps のソフトウェア サプライチェーンが完成すると言っていいでしょう。さて、このことに、Docker のムーヴメントがどう貢献するかをみていきましょう。
3 つのデリバリ モデルと Congruence モデル
スライドは動画の 22:28 付近 をご覧ください (もしくは https://www.slideshare.net/botchagalupe/devops-and-immutable-infrastructure-cloud-expo-2015-nyc の 7 ページにもその図が掲載されています)。
- Divergence (違いがある状態)
- Convergence (同じ状態に収束させていく)
- Congruence (一致している状態)
ここ 10 年で、Infrastructure as Code は多大な利益をもたらしました。Puppet や Chef や Ansible といったものです。それらは Convergence のモデルでした。しかし、先に紹介したような多くの論文から言えることは、最も利益をもたらすのは Congruence モデルです。
Immutable Delivery
Immutable Delivery は、John が名付けた概念です。デリバリをするときに、インフラ環境も含めたバイナリとしてデプロイするという考え方です。この考え方は、「The First Way」で紹介されていきます。さて、これがどのようなメリットをもたらすでしょうか。
彼が紹介していた Gartner のAssessing Docker and Containers for Five Software Delivery Use Cases、自身が書いた Docker and Three Way of DevOps も併せてご覧ください。
The First Way
【参考ブログ】 Docker and the Three Ways of DevOps Part 1: The First Way – Systems Thinking
Dev から Ops への流れ、つまり何かを思いついてから、実際にそれがデリバリされお金に変わるまでのリードタイムを短くしていく必要があります。
TOYOTA SUPPLY CHAIN MANAGEMENT の書籍で用いられているカテゴリを元に考えてみます。これらの概念に Docker はどう貢献するでしょうか?
■ Velocity
Velocity は何かに向かうための速度を上げるという意味合いです。ここでは、ソフトウェアのデリバリを行うときに速度をどのように上げることに Docker は貢献していくでしょう?
■ Developer Flow
大抵の技術者は Vagrant や Boot2Docker というアプリケーションを使って Docker での環境をラップトップの上にワンコマンドで構築して、使っています。これにより、サービスのテストが簡単にできます。
Integration Flow
仮想マシンと異なり、Docker は独立されたプロセスとして動作するので、大変高速です。ビルドスレーブの中で動く Docker は、テストサービスも高速に実行できます。1,000 もの Integration tests を 1 分で終了させるなどが可能でした。
さらに Docker は CI (継続的インテグレーション) のパイプラインのベロシティをあげます。
それは、Union FileSystem と、Copy on Write(COW) と呼ばれる仕組みを用います。Docker のイメージは、仮想マシンのイメージとは異なり、複数のレイヤを積み重ねて動作します。
書き換えができるのは、カレント (トップ) レイヤだけです。例えば、MySQL のイメージを作るときに、テーブルが特定の状態で初期化されたレイヤを作って、それを継承して、対象に対するテストデータを含んだレイヤを作っておきます。
継承元のレイヤにはいつでも復帰可能です。ですので、このような作りにしておくと、環境ごといつでも初期化された状態に戻すことができます。このことは、複数のテストの効率を上げるのにとても役立ちます。
■ Deployment Flow
Docker は継続的デリバリに関してもベロシティを高めることを助けます。
本番環境へのデプロイを考えると、いかにシームレスに、本番にアプリケーションを移行するか?ということが重要になってきます。
Blue/Green Deployment (参考: 「Blue-Green Deployment」とは何か、マーチン・ファウラー氏の解説) はその 1 つの手段です。Docker は Roll Back と Roll Forward を簡単にします。
他にも dark launches(Dark launching and other lessons from Facebook on massive deployments) / canarying などの手法も、Docker で簡単に実装可能です。
■ Variation
Docker イメージの最大の利益は、アプリケーションのデリバリに、アプリケーションのともに、インフラが含まれることです。出来上がったバイナリをバージョン管理されるようになります。
※筆者注: Docker では Dockerfile というファイルを書いておくと、Docker image というイメージを生成することができます。
それには、アプリケーションだけではなく、インフラ環境まで丸ごとパッケージ化されます。そのバイナリを DockerHub にバイナリごとアップロードしていく形態が一般的な使い方です。
イメージをバージョン管理にコミットするのです。
Immutable infrastructure with Docker and EC2 by Michael Bryzek(Gilt) の講演で、彼は、毎回インフラが変わる完全なる Immutable な環境をデブロイする様子をみて、そのことをImmutable Deliveryと名付けました。
■ Visualization
どうやって見える化を進めたらいいでしょう? Google は、週に22億個ものコンテナを使っています。1 秒に 15 コンテナです。
今 IT 業界で起こっている、破壊的なモデルは、「コンテナ化されたマイクロ サービス」と呼ばれるものです。
マイクロ サービスでは、サービスは「バウンダリ コンテキスト (boundary context)」と呼ばれるものとして定義されます。このサービスは、現実の世界のドメインを表します。
※筆者注: Conway の法則があります。ソフトウェアのアーキテクチャは、実際の組織の構造に従い、実際の組織もソフトウェアのアーキテクチャに従うというものです。
これらのバウンダリサービスが Docker のコンテナとして実装され、結合し、デリバリのパイプラインの一部として使われたら、それらは、実際の世界のドメインを表します。
DevOps の運用面からの視点でいうと、組織がどれだけ、MTTR (Mean time to Repair/Restore) をうまく管理できるかという話になります。この見える化 (Visibility) 戦略は、組織が、独立して、発見し、適切なオーナーシップを決定するのに役立ちます。それによって、MTTRを短縮することができます。
1 つの例として先程もあげた Immutable Infrastructure with Docker and EC2 by Michael Bryzek (Gilt) がモノリシックなアプリケーションから、マイクロ サービスに移行した「見える化」の良い事例です。彼らは、Docker のイメージに、メタファイルを加えて、イメージの見える化を行います。例えば Docker のイメージが生成されたときに、GitHub の Commit のハッシュなどを埋め込んでおきます。
The Second Way
講演では、The First Way について多くに述べられており、それ以降に関しては触れていますが、詳しくは述べられていませんので、講演の補足として、先にご紹介した記事である Part 2: The Second Way – Amplify Feedback Loops の内容を一部ご紹介します。
The Second Way は、DevOps のフィードバックループです。つまり、運用から開発へのフィードバックです。Docker はどう貢献するでしょうか?
欠陥は、顧客が出会うまで欠陥ではありません。リーンの原則によると、より早く将来欠陥になる可能性を捕まえることができたらコストを抑えることができます。そのためには、3 つの V が有効です。
◆ Velocity
Velocity つまり、何かに向かう速度が重要です。
ソフトウェア デリバリのフローはいつも同じ向きに流れるとは限りません。欠陥が発生したら、切り替えの時間が発生します。
デリバリの速度を上げることと、問題が発生して、切り替えが発生したときに、どれだけ早くできるか、つまり両方の方向の速度を上げる必要があります。
The Second Way には、トヨタの あんどん方式 がヒントになります。
あんどん方式とは、欠陥を発見したら、工場のラインの人が、ラインを止める仕組みだ。すごく小さな欠陥でも躊躇なくラインを止める。これにより、欠陥を修正するプロセスが主要なプロセスとして組み込まれることになります。
※筆者注: 次のリンクが参考になります。
- (参考) トヨタ生産方式について
- 自働化について
Docker を用いると、パッケージング、プロビジョニング、Immutable delivery を実施します。このプロセスは、欠陥が発見されたとき、簡単にラインを止めることができ、切り替え時間の短縮に貢献することと同じことができます。
◆ Variation
組み合わされた複雑なソフトウェアをスケールさせることはシステムの脆さを招きます。ソフトウェアは、何千ものクラスやライブラリで構成されています。ほんの少しのデリバリ方式の違いが修正し難い欠陥の引き金になります。
安全なよいサービスは、バージョン管理システムに、すべての成果物が入っていることを必須としています。
ところが、ソースからすべての成果物を再ビルドすることは、欠陥を引き起こす十分な「バリエーション」になる可能性があります。
Docker のデリバリと、Immutable な artifact (注: アプリケーションとインフラを含んだ Docker のイメージ) を使う点が、このバリエーションのリスクの発生確率を劇的に下げてくれます。この性質により、デリバリ パイプラインの最後の方で問題が発見されるリスクを小さくしてくれます。
◆ Visualization
Immutable delivery プロセスの利点は、アプリケーション、インフラ含む、すべての成果物が、バイナリとしてデリバリされることです。
これを見える化するためには、サービスデリバリのチームがソースから、メタデータを作成して、パイプラインのステージを見える化できるとよいでしょう。
例えば Git のコミット時に付与される Git の SHA ハッシュを Docker イメージの特定のセクションに埋め込むことはとても一般的なことです。メタデータとしては、次のようなものを埋め込むとよいでしょう
- どこで、いつ、なぜそれはビルドされたか?
- 先祖のイメージはどれか?
- どのようにスタートされるか、評価して、モニタしてアップデートするか?
- どのGit リポジトリか、ハッシュは?
- ビルド時点で付けられたタグは?
- プロジェクト名は?
- 権限をもったユーザがリッチなメタデータを付与する権限
トラブルシューティングや、欠陥を発見したときに、メタデータを見える化してあれば、欠陥を修正する時間をスピードアップします。それにより、全体のリードタイムをより短くすることが可能です。
The Third Way
The Third Way に関しても講演の補足としてご紹介させていただきます。3 つ目は、継続的な実験と、学びの文化を作る段階です。
【参考ブログ】Docker and the Three Ways of DevOps Part 3: The Third Way – Culture of Continuous Experimentation and Learning
3 つ目は、Continuous Learning つまり、継続的な学びの文化を作ることです。
DevOps では Kaizen (改善) という言葉が組織の継続的な改善を指し示す言葉として使われます。Kaizen は、組織の中で、継続的な実験と学びの文化を作り出していく中で達成されます。
アメリカの有名なソートリーダーである Edward Deming は、このことをPlan Do Study Actサイクル(PDSA)と呼んでいます。ここでも、Johnは、DevOpsの起源の一つはトヨタ生産方式であることを紹介しています。その上で、“トヨタ生産方式は、継続的に実験する科学者の集まりである” という言葉を紹介しています。
そのアイデアをさらに進めるものとして、日本語の Kata (型) を紹介しています、皆様もご存知の通り、武道で行なわれる練習で、繰り返し、同じことを行って体で覚えることです。実際の実験を継続的に行って、常に学んでそれを常に次のアクションにつなげていく。こういうことが大切です。
Docker と Thrid Way
Docker を使うと非常に簡単に「実験」をすることができます。あるファイナンスの組織は Docker を ”Container as a Service” として使っていました。彼らは 100 を超えるデータ サイエンティストを組織に抱えています。彼らは、正しいデータと、正しい分析ができる環境を探していました。もし、それが間違った組み合わせだったら、重要な判断をミスしてしまう。そして、以前はとても大変な作業でした。
この解決策として、この組織は、Docker を使って、サンドボックスの環境をつくり、データやツールなどをそこにパッケージ化しました。結果として、データ サイエンティストは、1 分で正しいデータと、分析ツールのセットを手にいれることができるようになり、実験の結果をずっと少ない時間で得ることができるようになりました。以前は環境のセットアップだけで 2 日以上かかっていました。今、彼らは複数のツールの実験自体を数時間で終えることができます。
また、John は 12 歳の自分の子供と、野球データの分析を教えていました。RとRの野球用のパッケージをインストールしようとしたときに、同僚が、”Using an R Container for Analytical Models” というブログをツイートしたのを見かけました。実際に John と彼の子供は、DockerHub からイメージを落として、簡単に統計データにアクセスできました。このような実験が、データと、環境付きの ”Container as a Service” として簡単にできるようになります。
このことによって、実験と学習の効率性をあなたの組織にもたらすことができるのです。
John Willis からのメッセージ
講演が面白かったので、終了後に彼にインタビューしてみました。彼に「なんで、日本で今は DevOpsDays がやってないの?」と聞いたのですが、「DevOps の起源は日本なのに、それが開催されない理由はないよ」という話をおっしゃっておられたのが印象的でした。彼に是非日本に来てもらいたいですね。
https://channel9.msdn.com/Blogs/livedevopsinjapan/DevOpsEnterprise2015-4