Cluster Continuous Replication en Exchange 2007
Cluster Continuous Replication (en adelante CCR), es una nueva funcionalidad de alta disponibilidad incorporada en Exchange 2007. La misma combina la funcionalidad de “Log Shipping” discutida en Local Continuous Replication (LCR), y la funcionalidad de “Failover” en Microsoft Cluster Service de Windows 2003, para ofrecer una solución flexible y de bajo costo para alta disponibilidad distribuida. Este artículo es una descripción básica de sus características, bondades y limitaciones que pueden ser útiles en la evaluación del producto.
¿Cuáles son las principales diferencias entre LCR y CCR?
LCR |
CCR |
Fuente y Destino de la réplica se encuentran en la mismo servidor |
Fuente y Destino de la réplica se encuentran en diferentes servidores |
LCR no es habilitado automáticamente |
CCR se habilita por default |
LCR no se recupera de una falla automáticamente (Failover) |
Posibilita la recuperación automática en caso de falla (Failover) |
Luego de habernos recuperado de una falla, la réplica debe ser habilitada por el administrador. |
Luego de recuperarse de una falla, la replicación se invierte entre los nodos y se habilita automáticamente |
Se implementa en un servidor único |
Requiere Windows Cluster configurado con Quorum “Majority Node Set” |
El server LCR permite coexistencia con otros roles |
En CCR solo es posible instalar Mailbox Role |
El nombre del servidor Exchange es el nombre de la máquina |
El nombre del servidor Exchange es un nombre independiente al de los nodos del cluster conocido como “Clustered Mailbox Server” o CMS |
No requiere discos compartidos a ambos nodos del Cluster |
|
Aprovecha el “transport dumpster” en el servidor HUB para evitar la pérdida de mensajes. |
¿En que consiste la solución CCR?
Al igual que en un servidor Cluster Exchange 2003, el CCR es visto por los clientes como un servidor virtual que corre en el nodo activo. “Clustered Mailbox Server” (en adelante CMS) es el equivalente a lo que conocemos como Exchange Virtual Server en un cluster de Exchange 2003. El nombre de red correspondiente al CMS es implementado por un recurso de netrowk name del servicio de cluster, tendrá su propia cuenta en Active Directory y será identificado como un servidor de Mailboxes por los clientes.
La figura siguiente muestra la configuración de todos los elementos de una implementación CCR:
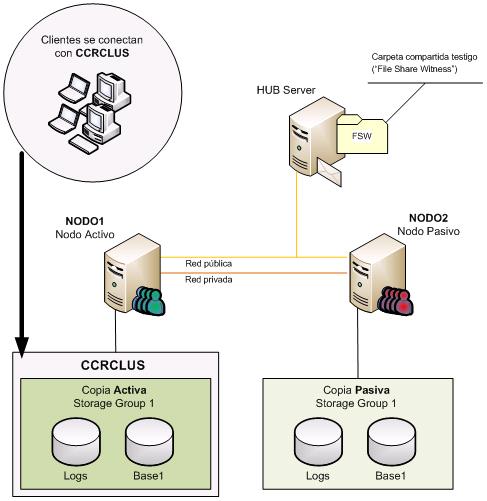
Características del cluster de Windows
Para la instalación de CCR, se utiliza una configuración especial del cluster de Windows en relación al recurso de quórum.
En implementaciones tradicionales de cluster, el recurso de quórum se utiliza para almacenar información de configuración y arbitrar que nodo debe ser dueño de los recursos, por lo tanto ambos nodos deben tener acceso al mismo. Cada nodo debe o bien ser el dueño del recurso o poder comunicase con el nodo dueño del recurso. Si uno de los nodos pierde comunicación y el mismo no está controlando el recurso de quórum, se considera fuera del Cluster. Este nodo detendrá el servicio de cluster y el nodo que continúa accediendo al quórum se apropia de sus recursos. En clusters con nodos geográficamente distribuidos, usar este tipo de quórum implica una conexión a distancia al storage compartido, o una solución de replicación del storage compartido en tiempo real. Ambas soluciones son viables pero a un costo alto.
Volviendo a la figura, vemos que no hay dispositivos de almacenamiento compartido entre NODO1 y NODO2. Esto se debe a que la implementación del CCR se realiza usando un nuevo recurso de quórum llamado Majority Node Set (en adelante MNS).
MNS es introducido en Windows 2003 y permite configurar el recurso de quórum en discos locales, replicados entre sí, para facilitar la distribución geográfica de los nodos. En este nuevo esquema, el arbitraje de los recursos se calcula de la siguiente manera: los cambios en el cluster solamente son válidos si hay sido grabados en la mayoría de los nodos del cluster. Esto es, para que un nodo no se considere parte del cluster, tiene que poder contactar a (<número de nodos>/2)+1 nodos. De otra forma el servicio de cluster se detiene abruptamente para evitar inconsistencia en su estado.
OK, entonces, en un cluster de 4 nodos, 3 deben estar activos. En uno de 3 nodos 2 deben estar activos. En un cluster de 2 nodos…. ¿?. Este esquema, no fue pensado originalmente para dos nodos, porque corremos el riesgo, por ejemplo, si perdemos la comunicación entre ellos, que ambos nodos se crean con derecho de seguir ejecutando por tener acceso al quórum local (este problema se denomina Split-brain), provocando divergencia en las aplicaciones.
En Windows 2003 SP1, se introduce nueva funcionalidad que permite configurar un tercer servidor (no necesariamente parte del cluster) como votante en el arbitraje, y así continuar con la formula (<número de nodos>/2)+1. Esta funcionalidad se denomina “File Share Witness” (en adelante FSW) y consiste en un directorio compartido que es accedido por los otros dos nodos del cluster, permitiendo la configuración MNS con solo dos nodos. Si un nodo pierde comunicación con el otro, el que mantenga comunicación con el FSW es que correrá los recursos.
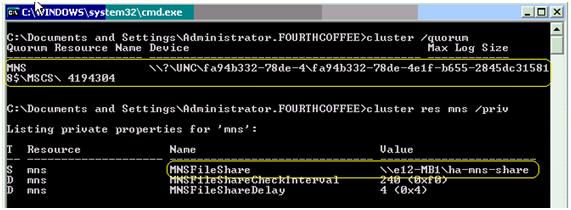
La siguiente imagen muestra la configuración del recurso de quórum donde se ve el nombre del mismo MNS, su resource guid y la configuración del FSW como propiedad privada con valor \\E12-MB1\HA-MNS-SHARE. En este ejemplo el servidor E12-MB1 donde está definido el FSW es un Hub Transport server como se recomienda en las mejores prácticas.
Ventajas del CCR
La mayor bondad del CCR es poder combinar la funcionalidad del cluster de Windows con la de log shipping. Esta combinación evita puntos de falla únicos, ya que la base de datos se encuentra replicada en el nodo pasivo, permite utilizar hardware estándar porque no implementa almacenamiento compartido, y por tal motivo, sus nodos pueden ser instalados en sitios geográficamente distantes.
Otra bondad de esta configuración es que podemos realizar respaldos a la copia de la base de datos, permitiendo descargar el nodo activo de esta responsabilidad y permitiendo el normal truncamiento de los log de transacciones.
CCR presenta un esquema simplificado de recursos en cluster, eliminando los recursos existentes en 2003 como pop3, smtp, routing, etc., y manteniendo también fuera del cluster nuevos servicios incorporados en Exchange 2007 como Active Directory Topology, Mail Submission Service y Replication Service entre otros.
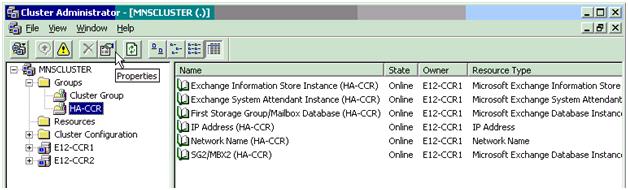
La siguiente es un ejemplo de cómo se ve un grupo de Exchange en CCR con dos bases de datos “First Storage Group/Mailbox Database (HA-CCR) ” y “SG2/MBX2 (HA-CCR) ” y sus recursos de cluster asociados:
Se ha agregado soporte para la funcionalidad de instalación “/disasterrecovery” que no era soportado en Exchange 2003 clusters. El comando “Setup.com /recoverCMS” permite recuperar un CMS tanto sea para CCR como para para Single Copy Clusters.
Servicio de Replicación
Este servicio juega un importante papel en CCR y es el encargado de la implementación del log shipping. Aquí se los presento en sus tres denominaciones dependiendo del a interface con que se consulte:


En el momento de instalación, el servicio de replicación copia la base de datos al nodo pasivo en un proceso inicial llamado “Seeding”. A continuación, se copian los logs de transacciones desde el nodo activo al pasivo para mantener actualizada la copia de la base de datos.
Este sería el esquema de trabajo del servicio de replicación:
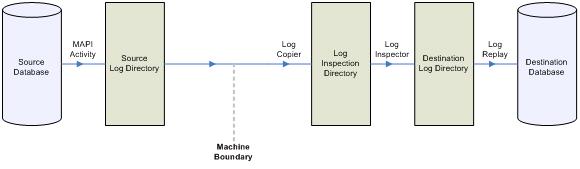
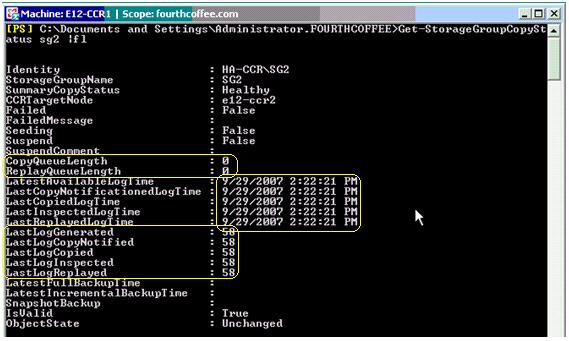
La actividad de la base de datos activa genera transacciones que se almacenan en los logs, estos logs son leídos y copiados desde el nodo pasivo (modalidad “pull”) por el servicio de replicación, que los copia un directorio temporal de inspección (directorio inspector). En este directorio el ESE que es el motor de la base de datos, se encarga de verificar que el checksum de los log es correcto y pasar el control al servicio de replicación para que los mueva al directorio de trabajo. Una vez que los logs se encuentran en el directorio de trabajo, nuevamente el ESE se encarga de aplicar las transacciones de estos logs a la base de datos (proceso de “replay”). Este proceso es asincrónico, porque los logs se copian recién luego de ser procesados por el nodo activo. Este asincronismo, resulta en que la copia de la base de datos nunca esté completamente sincronizada en cualquier momento en el tiempo, sino que siempre habrá un retraso en dicha sincronización. El comando Get-StorageGroupCopyStatus nos muestra el estado de esta copia con detalles como cual es el último log generado, último copiado, el último inspeccionado, cuantos logs en cola, y la hora para cada evento entre otra información.
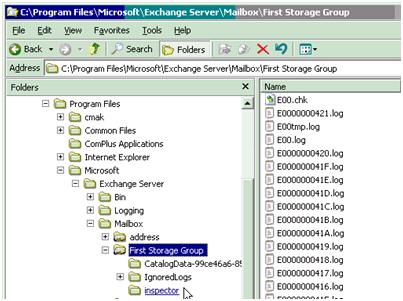
El servicio de replicación copia los logs en modalidad de extracción o “pull” desde el nodo pasivo, o sea que los recursos dedicados por el nodo activo al proceso son mínimos. El nodo pasivo usa el protocolo SMB para realizar la copia desde un directorio compartido como se muestra en la figura, que es creado automáticamente para cada grupo de almacenamiento en el nodo activo.
En caso de que el proceso de replicación falle por problemas de copia o corrupción, se generará una divergencia entre la base origen y destino que puede corregirse realizando un “reseed” de la base de datos. Este proceso copia y reemplaza la base de datos en el nodo pasivo por la que corre en el nodo activo.
El esquema de replicación, requiere que haya una relación 1:1 entre log de transacciones y grupos de almacenamiento (SG), para que cada base de datos tenga sus propios log de transacciones. En caso de tener más de un grupo de almacenamiento, el servicio de replicación trabajará con varias instancias de replicación. Cada par de base de datos y grupo de almacenamiento es representado por un recurso en el administrador de cluster.
Recuperación automática
Una de las ventajas de CCR con respecto a LCR y SCR es que la recuperación del CMS en caso de falla es automática. Esta recuperación la implementa el servicio de cluster quien monitorea los recursos de Exchange generando un failover hacia el nodo pasivo. El servicio de replicación complementa la operación revirtiendo automáticamente el sentido de la replicación.
En caso de un failover manual, ambos nodos se encontrarán disponibles y la actualización completa de la base de datos en el nodo que se convierte de pasivo a activo, se realiza copiando el último log Exx.log desde el nodo previamente activo antes de montar la base de datos en el nuevo nodo activo. Aquí aseguramos que la base de datos está completamente sincronizada.
Este proceso puede no completarse en caso de un failover consecuencia de una falla en el nodo activo. Si el nodo activo no está disponible, el nodo pasivo no va a poder copiar el/los últimos logs para asegurar la sincronización completa de la base de datos. En este caso, el administrador puede optar por perder algunos logs en pos de la disponibilidad del sistema, configurando dos parámetros en el objeto MailboxServer. –AutoDatabaseMountDial y -ForcedDatabaseMountAfter configura la cantidad de logs que estamos dispuestos a perder:
AutoDatabaseMountDial
· Lossless - Ninguno. Todos los logs generados en el nodo activo deberán ser copiados al pasivo antes de que esta base de datos monte automáticamente
· GoodAvailability – Dos. El parámetro “CopyQueueLenght” que es la cantidad de logs que el nodo pasivo reconoce como faltantes desde el nodo activo, debe ser menor o igual a dos para que la base de datos monte automáticamente. Si este valor es mayor que dos, la base no montará pero el servicio de replicación continuará intentando copiar los logs desde el nodo activo.
· BestAvailability – Cinco. “CopyQueueLenght” debe ser menor o igual a cinco para que la base monte automáticamente. Como en el caso anterior el servicio de replicación continuará intentando copiar los logs desde el nodo activo.
La configuración por omisión de este parámetro es BestAvailability. Si se especifica BestAvailability o GoodAvailability, es posible que se pierda información. Sin embargo la funcionalidad de Transport Dumpster que está habilitada por omisión, reenviará los últimos mensajes entregados por el rol de transporte a este CMS evitando así la perdida de nuevos mensajes. Operaciones no relacionadas con el transporte, como borrado de mensajes, movimiento de los mismos entre carpetas, etc. pueden formar parte de las transacciones perdidas.
ForcedDatabaseMountAfter
Este parámetro especifica cuanto tiempo esperar antes de que Exchange monte la base de datos automáticamente aunque los logs requeridos en AutoDatabaseMountDial no se hayan podido copiar.

¿Desventajas?
Algunas de las desventajas que identifico son en realidad consecuencia de las grandes ventajas en disponibilidad, yo las llamaría desventajas relativas. Una de ellas es la posibilidad de pérdida de información durante un failover por falla del nodo activo. Esto es opcional, ya que podemos decidir no usar la copia de la base de datos o no permitir perdida de información, prosiguiendo con métodos estándar de recuperación desde respaldo. Obviamente esto tendrá su costo en disponibilidad del servicio.
Otra desventaja es la necesidad de reseed (re-copia) de la base de datos en caso de divergencia. No es posible una sincronización parcial de la base de datos una vez que la divergencia pasa a formar parte del archivo .edb. La desventaja aquí es que para una base de datos grande la copia de la misma a través de la red es una operación costosa.
El soporte de Public Folders es limitado. Por limitaciones de interoperabilidad entre el servicio de replicación de Public Folders y el servicio de replicación de Exchange, si optamos por tener un Public Folder Store en CCR, este no puede replicar con otro PF Store. Como la replicación de Public Folders se establece automáticamente cuando instalamos un segundo PF Store en la organización, solamente podremos tener un PF Store en la organización si este reside en CCR.
Requerimientos
Entre los requerimientos de CCR caben destacar los siguientes:
· El servicio de Windows Cluster debe estar instalado y configurado para MNS con File Share Witness antes de la instalación de Exchange.
· Se requiere una base de datos por grupo de almacenamiento
· Los nodos del cluster deben estar en la misma subred TCP/IP y el mismo sitio de Active Directory
· La latencia de red debe ser menor a 500ms para asegurar que el servicio de replicación funcione correctamente.
· El sistema operativo y los binarios de Exchange deben estar instalados en los mismas rutas de directorio en ambos nodos, y tener la misma versión.
· La configuración de discos en ambos nodos debe ser similar (mismas letras para sistema operativo, bases de datos, log de transacciones, etc.). No tienen por qué ser idénticas en tecnología y tamaño.
· Es altamente recomendado que utilice DNS que soporte actualización dinámica
¿Donde consigo más información?
Hay varias fuentes de información para profundizar sobre aspectos específicos de CCR. Algunas de ellas son:
· Documentación del producto en línea.
· Blog del grupo de producto de Exchange
· Grupo Latinoamericano de Usuarios de Exchange (MSGlue) por charlas, grupo de discusión y documentos en Español.
· Support Academy Open Edition. Presentaciones técnicas en vivo, en Español y Portugués.
Hasta la próxima!