Falha ao Agregar um Nó a um Cluster Existente
Por: Yuri Diógenes
1. Introdução
Este artigo é baseado em um caso que trabalhei recentemente onde não era possível agregar um nó a um cluster existente. Apesar de toda a configuração estar correta e nenhum erro de hardware ao acessar os discos, o primeiro nó simplesmente não se agregava ao cluster. Pode parecer confuso dizer que o primeiro nó não agregava, mas o que aconteceu de fato foi que os dois servidores funcionavam perfeitamente, algumas mudanças foram feitas e ambos nós reiniciados. Após isso apenas o nó 2 conseguiu subir e assumir os recursos, como os recursos já estavam no nó 2 e o nó 1 não conseguia agregar-se ao cluster, então o serviço de cluster falhava ao iniciar.
2. Analisando os Dados
Começando a revisão dos dados pelo visualizador de eventos foi possível observar o momento da falha:
Event Type: Error
Event Source: ClusSvc
Event Category: Startup/Shutdown
Event ID: 1009
Date: 20/03/2007
Time: 10:18:44 PM
User: N/A
Computer: CNODE1
Description:
Cluster service could not join an existing server cluster and could not form a new server cluster. Cluster service has terminated.
O nó CNODE1 falhou primeiramente ao tentar juntar-se ao cluster. E logo em seguida houve a parada do serviço. Primeira coisa a fazer neste caso é entender o que houve na perspectiva deste nó (CNODE1) para ele não conseguir fazer o “join” no cluster. Para isso revisei o arquivo de log do cluster e nele pude observar as seguintes entradas:
Primeira Parte – Falha no Join
2007/03/20-14:18:41.872 INFO [JOIN] Asking 10.0.0.2 to sponsor us after delay of 0 milliseconds.
2007/03/20-14:18:41.992 WARN [JOIN] Unable to get join version data from sponsor 10.0.0.2 using NTLM package, status 1130.
2007/03/20-14:18:41.992 WARN [JOIN] JoinVersion data for sponsor 10.0.0.2 is invalid, status 1130.
2007/03/20-14:18:42.874 INFO [JOIN] Asking 192.168.0.2 to sponsor us after delay of 1000 milliseconds.
2007/03/20-14:18:42.874 INFO [JOIN] Asking CNODE2 to sponsor us after delay of 1000 milliseconds.
2007/03/20-14:18:42.884 WARN [JOIN] Unable to get join version data from sponsor 192.168.0.2 using NTLM package, status 1130.
2007/03/20-14:18:42.884 WARN [JOIN] JoinVersion data for sponsor 192.168.0.2 is invalid, status 1130.
2007/03/20-14:18:42.884 WARN [JOIN] Unable to get join version data from sponsor CNODE2 using NTLM package, status 1130.
2007/03/20-14:18:42.884 WARN [JOIN] JoinVersion data for sponsor CNODE2 is invalid, status 1130.
2007/03/20-14:18:43.875 INFO [JOIN] Asking 192.168.0.219 to sponsor us after delay of 2000 milliseconds.
2007/03/20-14:18:43.885 WARN [JOIN] Unable to get join version data from sponsor 192.168.0.219 using NTLM package, status 1130.
2007/03/20-14:18:43.885 WARN [JOIN] JoinVersion data for sponsor 192.168.0.219 is invalid, status 1130.
2007/03/20-14:18:43.885 INFO [JOIN] Got out of the join wait, CsJoinThreadCount = 1.
2007/03/20-14:18:43.885 ERR [JOIN] Unable to connect to any sponsor node.
Como você pode ver no log, toda a seqüência inicial está funcionando corretamente, mas podemos observar que logo ao tentar localizar o outro nó temos o erro 1130 (ERROR NOT ENOUGH SERVER MEMORY).
O erro em si não me disse muito, porém o fato de que temos o evento 1130 durante uma possível autenticação NTLM isso me fez direcionar o caminho de obtenção de novos dados para o lado de autenticação.
Se tratando de autenticação então o caminho ideal é entender o que está passando pela rede que pode nos dar mais informações acerca do problema. Resolvi então fazer um lab para entender qual deveria ser o comportamento esperado do ponto de vista do segundo quando um outro nó tenta agregar-se ao cluster. No lab usei o Network Monitor para fazer a captura dos dados durante o processo de “join” e aqui está o resultado:
192.168.0.200 |
192.168.0.255 |
NbtNs |
NbtNs: Registration Request for MYDOMAIN |
192.168.0.200 |
192.168.0.2 |
UDP |
UDP: SrcPort = 3343, DstPort = 3343, Length = 48 |
192.168.0.200 |
192.168.0.255 |
BROWSER |
BROWSER: Request Announcement, ResponseName = NODE1 |
192.168.0.100 |
192.168.0.200 |
UDP |
UDP: SrcPort = 3343, DstPort = 3343, Length = 48 |
192.168.0.200 |
192.168.0.255 |
NbtNs |
NbtNs: Query Request for DCSERVER |
192.168.0.200 |
192.168.0.2 |
UDP |
UDP: SrcPort = 3343, DstPort = 3343, Length = 48 |
192.168.0.2 |
192.168.0.200 |
UDP |
UDP: SrcPort = 3343, DstPort = 3343, Length = 48 |
Neste lab acima temos o servidor NODE1 (192.168.0.200) e servidor NODE2 (192.168.0.100) se comunicando. É possível notar que temos primeiramente um broadcast NetBIOS para registro do nome de domínio em seguida temos um pacote unicast UDP na porta 3343. Este pacote é usado comumente pelo serviço de cluster para controle e verificação se os nós estão acessíveis via rede (este é um pacote que aparece 4 vezes nesta captura). Em seguida temos outro broadcast do nó anunciando seu nome Netbios, mas um UDP e uma consulta para o DC. Em fim, não há muito segredo na comunicação padrão.
Sabendo o que esperar da comunicação padrão, então agora era necessário capturar um tráfego real do ambiente do cliente. Foi então colocado o network monitor na placa pública do servidor CNODE2 e iniciado a captura. Eis o resultado:
CNODE1 192.168.0.255 NbtNs NbtNs: Registration Request for CTEST
CNODE1 192.168.0.255 NbtNs NbtNs: Registration Request for CTEST
CNODE1 192.168.0.2 EPM EPM: Request: ept_map: unknown, {05000000-1300-0D00-A0AA-176E471AD111} v48536.30200, DNA Phase 4
CNODE1 192.168.0.2 EPM EPM: Request: ept_map: unknown, {05000000-1300-0D00-A0AA-176E471AD111} v48536.30200, DNA Phase 4
192.168.0.2 CNODE1 CONV CONV: ConvWhoAreYou2 Request, Actuid={E745A373-D459-48DD-BD44-39C563AD3035}
192.168.0.2 CNODE1 CONV CONV: ConvWhoAreYou2 Request, Actuid={B5B69FA3-D09C-4158-8F2D-A1ADD8371400}
CNODE1 192.168.0.2 CONV CONV: ConvWhoAreYou2 Response, CasUuid={41F03860-A887-493A-B03A-537671E7A323}
CNODE1 192.168.0.2 CONV CONV: ConvWhoAreYou2 Response, CasUuid={41F03860-A887-493A-B03A-537671E7A323}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Ack: Seq=0x0 Opnum=0x1 Frag=0x1 Serial=0x1 Act Id={484F6597-81D8-478B-9BA2-B825A96B633F}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Response: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x0 Act Id={E745A373-D459-48DD-BD44-39C563AD3035}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Ack: Seq=0x0 Opnum=0x1 Frag=0x1 Serial=0x1 Act Id={E7D4BED3-F693-43D4-B17F-E740FEDEFF56}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Response: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x0 Act Id={B5B69FA3-D09C-4158-8F2D-A1ADD8371400}
CNODE1 192.168.0.2 MSRPC MSRPC: dg Ack: Seq=0x0 Opnum=0x3 Frag=0x1 Serial=0x1 Act Id={E745A373-D459-48DD-BD44-39C563AD3035}
CNODE1 192.168.0.2 MSRPC MSRPC: dg Ack: Seq=0x0 Opnum=0x3 Frag=0x1 Serial=0x1 Act Id={B5B69FA3-D09C-4158-8F2D-A1ADD8371400}
CNODE1 192.168.0.2 MSRPC MSRPC: dg Request: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x0 Act Id={756C388D-281C-4860-807B-72764EC078E3}
CNODE1 192.168.0.2 MSRPC MSRPC: dg Request: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x0 Act Id={72E15D7B-3348-4931-9544-2945F9A9284C}
192.168.0.2 CNODE1 CONV CONV: ConvWhoAreYouAuth Request, Actuid={756C388D-281C-4860-807B-72764EC078E3}
192.168.0.2 CNODE1 CONV CONV: ConvWhoAreYouAuth Request, Actuid={72E15D7B-3348-4931-9544-2945F9A9284C}
CNODE1 192.168.0.2 CONV CONV: ConvWhoAreYouAuth Response, CasUuid={41F03860-A887-493A-B03A-537671E7A323}
CNODE1 192.168.0.2 CONV CONV: ConvWhoAreYouAuth Response, CasUuid={41F03860-A887-493A-B03A-537671E7A323}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Ack: Seq=0x0 Opnum=0x3 Frag=0x1 Serial=0x1 Act Id={ADBD1148-6E89-492C-8147-7F3BDDD9FD9E}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Ack: Seq=0x0 Opnum=0x3 Frag=0x1 Serial=0x1 Act Id={E4FC6D76-72BE-43A8-9430-74BECA2ECE35}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Reject: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x0 Act Id={756C388D-281C-4860-807B-72764EC078E3}
192.168.0.2 CNODE1 MSRPC MSRPC: dg Reject: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x1 Act Id={72E15D7B-3348-4931-9544-2945F9A9284C}
Só pela quantidade de tráfego já foi possível notar que existe uma diferença considerável entre um e outro. No início (registro do nome) tudo parecia o mesmo de antes, porém veio então veio um novo tráfego que foi EPM (RPC End Point Mapper) para determinar quais portas deverão ser utilizadas pelo RPC. Para maiores informações sobre como analisar tráfego de rede com RPC veja o artigo 159298.
Por fim (pacotes em vermelho) temos o segundo nó (192.168.0.2) rejeitando a comunicação com o CNODE1. Expandindo este pacote de rejeição foi possível observar o código de erro:
- RPC: dg Reject: Seq=0x0 Opnum=0x0 Frag=0x0 Serial=0x1 Act Id={72E15D7B-3348-4931-9544-2945F9A9284C}
- Reject:
- DgHeader:
RpcVers: 4 (0x4)
PType: 0x06 - Reject
+ Flags1: 0x00
+ Flags2: 0x00
+ PackedDrep: 0x10
SerialHi: 0 (0x0)
+ Object: {6E17AAA0-1A47-11D1-98BD-0000F875292E}
+ IfId: {00000000-0000-0000-0000-000000000000}
+ ActId: {72E15D7B-3348-4931-9544-2945F9A9284C}
ServerBoot: 1174226917 (0x45FD47E5)
IfVers: 0 (0x0)
Seqnum: 0 (0x0)
Opnum: 0 (0x0)
IHint: 65535 (0xFFFF)
AHint: 14 (0xE)
Len: 4 (0x4)
Fragnum: 0 (0x0)
AuthProto: None
SerialLo: 1 (0x1)
St: 0x1C00001B unknown
O erro que aparece como desconhecido é uma questão de “parser” (forma com que a ferramenta de análise interpreta o erro). O erro RPC 0x1C00001B de fato significa ERROR NOT ENOUGH SERVER MEMORY. Note que este erro é o mesmo que temos no log do cluster. Com isso podemos concluir que temos então um problema de autenticação NTLM e estabelecimento de conexão RPC.
3. Revisando o Ambiente
Para entender exatamente o que poderia estar acarretando este problema de autenticação foi necessário conversar com o cliente e entender o que ele havia mudado no ambiente. Foi então que ele mostrou que a política abaixo havia sido alterada:
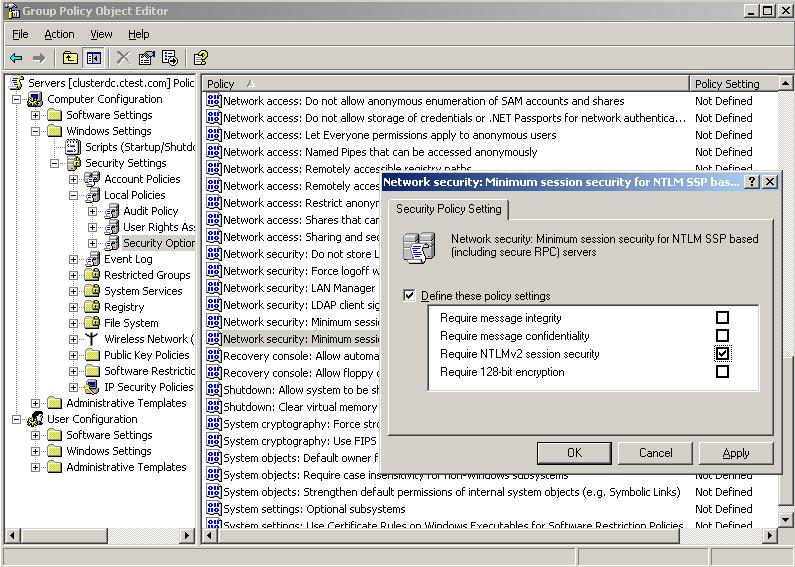
Figura 1
Esta política força o uso de conexões RPC seguras e também o uso de NTLMv2 durante a comunicação entre os servidores.
Desabilitamos esta política na OU dos servidores em cluster, executamos o comando gpupdate /force em cada um dos nós e reiniciamos os nós. Após isso foi possível agregar os recursos normalmente.
4. Mas como aplicar as políticas de segurança no Cluster?
Existem algumas diretrizes que devem ser seguidas para avaliar se a política de segurança efetivamente é válida para seu ambiente ou não. No caso do cluster as diretrizes são descritas no artigo abaixo:
891597 How to apply more restrictive security settings on a Windows Server 2003-based cluster server
https://support.microsoft.com/default.aspx?scid=kb;EN-US;891597
Neste artigo acima é possível entender quais as melhores práticas e testes que devem ser feitos antes de fazer uma alteração de política de segurança em servidores em cluster.
Também é possível avaliar o efeito colateral das políticas de segurança no documento “Threats and Countermeasures - Chapter 5: Security Options” que pode ser encontrado no Microsoft Technet.