Problemas de atribuição manual de IP em um cenário com RRAS usando DOD
Por: Yuri Diógenes
1. Introdução
O artigo desta semana é baseado em um incidente de suporte que trabalhei aqui na Microsoft onde o cliente tinha um cenário semelhante ao mostrado abaixo:
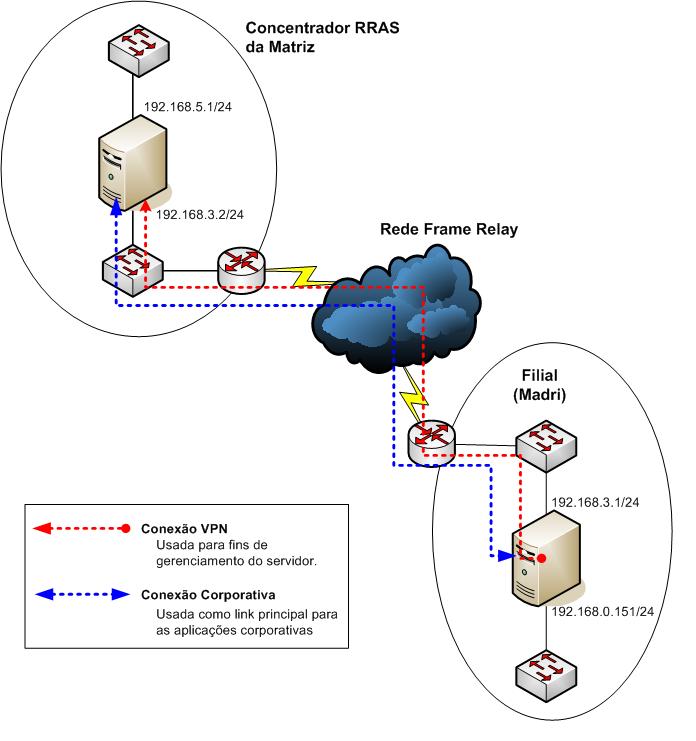
Figura 1 – No cenário acima apenas uma filial está sendo representada, porém existiam várias outras.
Neste cenário os servidores RRAS das filiais se conectavam com o servidor RRAS da matriz através de uma conexão sobre demanda (DOD – Dial on Demand) de um caminho único, ou seja, sempre a filial que vai discar para a matriz. Esta conexão DOD é usada para fins de gerenciamento, tendo em vista que a conexão principal entre o escritório remoto e a matriz é feita através de uma conexão dedicada nesta rede Frame Relay.
Neste cenário as conexões DOD utilizam endereçamento IP dinâmico atribuídos pelo servidor da matriz. Porém, neste cenário o cliente estava utilizando mapeamento estático através dos atributos da conta do usuário, com isso cada filial tinha seu devido usuário que por sua vez tinha o IP como um atributo definido nas propriedades da conta.
Durante o gerenciamento destes servidores remotos foi detectado que havia um problema com o endereçamento IP, pois ao acessar um determinado IP o mesmo apontava para um outro servidor. A solução de contorno era desconectar a conectar novamente, desta forma o IP correto era adquirido. Foi através da detecção deste problema que veio então a pergunta: por que mesmo com o mapeamento de IP sendo realizado na conta do usuário o servidor da filial obtém um IP diferente do que foi estabelecido?
2. Preparando o Ambiente
Para preparar o ambiente para obter as informações necessárias para iniciar a resolução do problema foi preciso realizar os seguintes passos nos servidores RRAS da matriz e da filial:
1. Habilitar todos os logs do RRAS através do comando netsh ras set tracing * enable. Estes logs serão armazenados na pasta %windir%\tracing.
2. Iniciar o “Network Monitor” para fazer a captura dos dados.
Após realizar isso foi necessário esperar que o problema ocorresse, pois o fato de ser um comportamento randômico foi algo que dificultou a captura dos dados sincronizados.
3. Análise dos Dados
Após ter capturado os dados no exato momento em que o problema ocorreu foi possível determinar basicamente o que tinha ocorrido. Porém antes de iniciar a leitura dos logs é importante entender os seguintes parâmetros configurados no servidor RRAS da filial, o servidor que inicia a conexão:
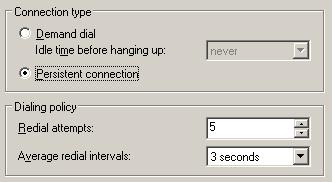
Figura 2 – Propriedades da conexão DOD no servidor RRAS da Filia.
Através deste parâmetro podemos então concluir que no lado da filial o RRAS vai esperar três segundos e então vai tentar conectar novamente.
Para termos certeza do que está ocorrendo com a filial Madri é necessário verificar as propriedades da conta deste usuário e checar qual o IP está de fato sendo atribuído para o RRAS desta filial:
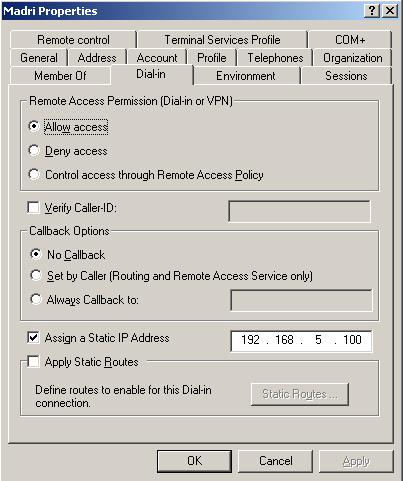
Figura 3 – Propriedades do usuário Madri.
Conforme é possível verificar na janela acima o endereço IP que deve ser atribuído automaticamente para o usuário Madri é 192.168.5.100.
Sabendo disso então focamos à análise em uma queda que ocorreu por volta das 7:12, a filial “Madri” perdeu a conexão por algum motivo e esperou 3 segundos para discar novamente.
No lado do servidor RRAS é possível verificar através do arquivo RASIPHLP.LOG o exato momento em que o usuário Madri tenta se re-conectar:
[2384] 02-20 07:15:09:506: RasSrvrAcquireAddress(hPort: 0x82, IP address: 0x6405a8c0, UserName: Madri, PortName: VPN4-126)
[2384] 02-20 07:15:09:506: rasSrvrGetAddressForServerAdapter
[2384] 02-20 07:15:09:506: Address 0x6405a8c0 is already in use
[2384] 02-20 07:15:09:506: RasDhcpAcquireAddress
[2384] 02-20 07:15:09:516: RasSrvrActivateIp(IpAddr = 0x6505a8c0, dwUsage = 0)
[2384] 02-20 07:15:09:516: RasTcpSetProxyArp(IP Addr: 0x6505a8c0, fAddAddress: TRUE)
[2384] 02-20 07:15:09:516: rasSrvrGetAddressForServerAdapter
O endereço IP que aparece em vermelho é justamente o endereço IP 192.168.5.100, a forma de encontrar isso é usando a seguinte regra:
- Endereço em hexadecimal que aparece no log = 0x6405a8c0
- Endereço em hexadecimal invertido e separado a cada dois dígitos = c0 a8 05 64
- Convertendo este endereço hexadecimal em decimal temos = 192.168.5.100
Note que às 7:15:09 temos o evento dizendo que o IP 192.168.5.100 já está em uso e com isso o IP 192.168.5.151 (0x6505a8c0) é atribuído para o cliente (Madri). Agora vejamos porque o servidor RRAS da Matriz acredita que este endereço IP ainda está em uso...
3.1. Conclusão
A conclusão deste cenário é que o RRAS da filial vai re-discar mais rapidamente do que o servidor RRAS leva para entender que a conexão caiu no lado remoto e desconectar o usuário. Com as configurações padrões do RRAS este tempo pode variar entre 2 a 3 minutos (mais informações sobre este comportamento ver o artigo KB262990), ou seja, mesmo com à atribuição manual do IP nas propriedades da conta, o RRAS precisa checar se o IP está em uso e caso esteja será necessário atribuir outro IP disponível no banco de dados do DHCP.
Desta forma quando vimos no RASIPHLP.LOG o evento dizendo que o IP estava em uso é justamente pelo fato de que o servidor RRAS ainda ter a conexão ativa com a filial e com isso o IP ainda não foi liberado.
4. Mas por que a conexão caiu?
Após termos identificado o motivo pelo qual o endereço IP era incorretamente atribuído então foi questionado o motivo pelo qual por várias vezes durante o dia a conexão havia sido perdida, fazendo com que a filial tivesse que re-discar para o servidor central RRAS.
Usando uma captura de exemplo de uma queda que aconteceu por volta de 8:20, é possível notar que um pouco antes deste evento temos os dois servidores trocando informações de controle PPTP normalmente, conforme é possível verificar no tráfego capturado. Estes pacotes de controle do PPTP são enviados a cada 60 segundos:
8:19 192.168.3.2 192.168.3.1 PPTP PPTP: Control Message , Echo Request
8:19 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Echo Reply
Às 8:20 temos o seguinte evento no arquivo RASMAN.LOG:
[1992] 02-20 08:20:43:284: d:\nt\net\rras\ras\rasman\rasman\util.c 1997: Disconnected Port 252, reason 1. rc=0x0
Logo em seguida temos o seguinte evento no arquivo RASTAPI.LOG:
[1992] 02-20 08:20:43:284: PortTestSignalState: DisconnectReason = 2
No arquivo RASMAN.LOG foi mostrado que a razão da desconexão foi igual a 1 (HARDWAREFAILURE) e no arquivo RASTAPI.LOG a razão foi igual a 2 (LINKDROPPED). Com isso podemos verificar que houve um problema em níveis de enlace ou físico. É possível com isso deduzir que houve um problema na portadora, seja ela a placa de rede ou o equipamento ativo que está à frente deste servidor RRAS.
Na captura de rede é possível verificar que ficamos um pouco mais de 1 segundo sem conectividade de rede total e às 8:21 começamos novamente o processo através de um ARP Request:”
8:21 192.168.3.1 192.168.3.1 ARP ARP: Request, 192.168.3.1 asks for 192.168.3.1
8:21 192.168.3.1 192.168.3.2 ARP ARP: Request, 192.168.3.1 asks for 192.168.3.2
8:21 192.168.3.2 192.168.3.1 ARP ARP: Response, 192.168.3.2 at 00-03-FF-0F-2B-29
Em seguida temos o TCP 3 Way Handshake do PPTP (TCP 1723):
8:21 192.168.3.1 192.168.3.2 TCP TCP: Flags=.S......, SrcPort=1149, DstPort=1723, Len=0, Seq=3777429460, Ack=0, Win=65535 (scale factor 0) = 65535
8:21 192.168.3.2 192.168.3.1 TCP TCP: Flags=.S..A..., SrcPort=1723, DstPort=1149, Len=0, Seq=1936732946, Ack=3777429461, Win=16384 (scale factor 0) = 16384
8:21 192.168.3.2 192.168.3.1 TCP TCP: Flags=....A..., SrcPort=1723, DstPort=1149, Len=0, Seq=1936733135, Ack=3777429809, Win=65187 (scale factor 0) = 65187
Em seguida temos a criação da conexão PPTP:
8:21 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Start Control Connection Request
8:21 192.168.3.2 192.168.3.1 PPTP PPTP: Control Message , Start Control Connection Reply
8:21 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Outgoing Call Request
8:21 192.168.3.2 192.168.3.1 PPTP PPTP: Control Message , Outgoing Call Reply
8:21 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Set Link Info
Após isso a comunicação continua sem maiores problemas.
5. Conclusão
Conforme mencionado antes na referência ao artigo KB262990, é possível fazer alguns ajustes no sentido de controle da ociosidade do link. O servidor RRAS pode ficar verificando se um link está ocioso através do ajuste do parâmetro InactivityIdleSeconds na chave abaixo:
HKEY_LOCAL_MACHINE\SYSTEM\CCS\Control\Class\{4d36E972-....}\instanceid
O valor padrão é 60 segundos, se este valor for reduzido para 1 o serviço de RRAS pode levar 30 a 45 segundos para detectar a queda do link PPTP.
Um outro parâmetro que pode ser usado é o DefaultIdleTimeout na chave abaixo:
HKLM\SYSTEM\CurrentControlSet\Services\RasMan\PPP
Este é um parâmetro global e afeta todas as conexões PPP, ou seja, o que o servidor RRAS vai fazer é verificar se a conexão está ociosa e caso esteja então vai desconectá-la.
Uma solução de contorno para esta necessidade seria:
- Configurar por exemplo o servidor RRAS para desconectar após 6 segundos sem tráfego alterando o DefaultIdleTimeout;
- Configurar o RRAS da filial para manter sempre algum tipo de trafego por este link, por exemplo um arquivo BAT com um ping -t para o endereço interno do servidor RRAS da matriz;
- Configurar o RRAS remoto para re-discar em 10 segundos caso a conexão tenha sido interrompida.
Com este tipo de solução de contorno, no final o que teríamos era o seguinte comportamento:
- Se a conexão de fato cair por completo no lado do cliente remoto ele vai contar 10 segundos para re-discar, já o servidor RRAS vai ficar 6 segundos vendo que a linha está ociosa e então vai desconectá-la;
- O resultado seria que quando o cliente remoto tentar se re-conectar ele não deverá ter o problema de pegar outro IP, tendo em vista que a conexão anterior já foi liberada e com isso o IP não estará em uso.