Como (Rapidamente) Usar o DebugDiag
COMO (RAPIDAMENTE) USAR O DEBUGDIAG
Por: Roberto A. Farah
Como (rapidamente) usar o DebugDiag para coletar e analisar dumps de Memory/Handle Leak, Crash e Hangs?
Algumas semanas atrás, conversando com um cliente por telefone, ele me sugeriu de escrever um artigo sobre a ferramenta DebugDiag destinado a profissionais com pouco conhecimento de programação para que, rapidamente, pudessem analisar dumps de aplicações de modo a identificar o problema causando determinados sintomas e passar isso para seus clientes ou desenvolvedores.
Achei uma idéia boa, pois a ferramenta pode salvar horas de depuração manual ou troubleshooting e pode ser facilmente utilizada.
Para explicar como utilizar o modo de coleta de dumps e análise automatizada do DebugDiag farei uma introdução necessária para se entender alguns conceitos.
SINTOMAS
Basicamente classificamos os sintomas em quatro categorias principais:
Crash – É o sintoma que caracteriza uma queda de aplicação devido a uma exceção fatal, ou seja, uma exceção que propagou da aplicação para o sistema operacional. Regra geral indica uma exceção não tratada.
Termos como 1st chance exceptions referem-se a exceções tratadas pela aplicação, e 2nd chances exceptions a exceções que não foram tratadas e propagaram.
Hang – É o sintoma que caracteriza o estado onde a aplicação está rodando mas não responde para o usuário. Isso pode ocorrer juntamente com baixíssimo consumo de CPU, alto consumo de CPU, alto ou baixo consumo de memória, etc... Deadlocks são um exemplo típico de problema, entre vários outros, que ocasionam o sintoma de hang. Não é incomum ver um hang de aplicação causando um crash em determinados cenários.
Memory/Handle Leak – É o sintoma caracterizado por uma quantidade crescente de memória alocada pela aplicação que nunca é liberada ou por uma quantidade crescente de handles que não são fechados. É comum que o memory/handle leak acabe gerando um sintoma de hang ou crash após determinado tempo. Portanto, há cenários onde um sintoma pode ser o causador de outro sintoma.
Performance – Esse sintoma refere-se a situações onde uma aplicação que executava normalmente, dentro dos padrões de performance esperados, passa a executar com performance insatisfatória após algum tipo de mudança, como: alteração na aplicação, aumento de carga, alteração no banco de dados, atualização de software, etc... Geralmente quando uma aplicação apresenta sintomas de baixa performance quando antes executava dentro dos limites de performance esperado, é comum se descobrir, após investigação, que outro sintoma, como excesso de exceções, memory/handle leak ou hang estava ocasionando a queda de performance.
Em casos de sintomas de performance sempre temos que coletar um baseline, ou seja, dados que refletem a performance antes da otimização, para, após otimizar, comparar com o baseline e quantificar o ganho.
Em relação aos sintomas mencionados acima é importante ter em mente que:
1- É muito comum se ter diferentes problemas ocasionando, ao mesmo tempo, o mesmo sintoma. Portanto, se você identificar um problema claro ocasionando o sintoma, corrija o problema e monitore a aplicação para ter certeza que não há outros problemas ocasionando o mesmo sintoma.
Existem inúmeros exemplos disso e posso afirmar que dificilmente trabalhamos em incidentes onde após isolar e resolver um problema os sintomas param.
Exemplo: Num cenário onde você tem um hang, você descobre que há um problema com Critical Sections em um componente. Você arruma, testa e monitora, para depois descobrir que um deadlock em outro componente também ocasiona o hang, obviamente não no mesmo momento, do contrário você teria identificado ambos problemas ao mesmo tempo numa coleta de dumps dos processos suspeitos.
2- É comum que um problema ocasionando determinado sintoma, oculte outro problema menos visìvel/frequente ocasionando o mesmo ou outro sintoma.
Por isso, após corrigir um problema, monitore para ter certeza que os sintomas pararam.
Exemplos:
- Num cenário onde o sintoma é baixa performance podemos nos deparar com gargalos simultâneos em diferentes partes. Por exemplo, imagine uma aplicação web com um servidor IIS, componentes COM+ e outro servidor de banco de dados SQL Server. Após investigação você descobre que os componentes rodando no IIS estão impactando a performance. Você arruma o problema e nota que agora os componentes manipulam as requisições bem mais rapidamente, portanto, solicitando mais do banco de dados, que acaba por demorar para responder e gerar um efeito cascata. Portanto, o banco de dados agora é o gargalo de performance. Embora o problema seja diferente, o sintoma de lentidão permanece.
- Você isola um crash de aplicação, portanto, a aplicação que antes caía em menos de 5 horas de uso agora roda sem problemas. Entretanto, a aplicação tem um memory leak que antes não era visível porque a aplicação caía liberando a memória previamente alocada, e agora, como ela roda por mais tempo o memory leak acaba consumindo muita memória e gerando outros sintomas.
DEPURANDO
Existem dois tipos de depuração.
a) Live Debug – refere-se ao processo de se conectar o depurador na aplicação e depurá-la enquanto ela está executando.
b) Post-Mortem Debug – refere-se ao processo de se coletar um dump de aplicação e depurar o dump ao invés de se depurar a aplicação. O dump (um user mode dump) é um arquivo que representa o conteúdo do processo em memória, portanto, é um retrato da aplicação em um determinado momento.
Ambas abordagens têm suas vantagens e desvantagens, mas o tipo de análise efetuado é o mesmo, exceto pelo fato que no dump você não poderá acompanhar a execução de algo, forçar uma rotina a ser executada ou fazer algo mais que necessite da aplicação sendo executada.
Quando usar Post-Mortem Debug (coleta de dumps) e quando usar Live Debug (depurar a aplicação durante a execução)?
Aqui eu colocarei minha opinião pessoal, portanto, outras pessoas da Microsoft poderiam ter diferentes opiniões.
- Live Debug é usado quando:
– Você está depurando uma aplicação que não tem símbolos (arquivos PDB, explicarei sobre isso) e código fonte, portanto você tem que analisar o código disassemblado.
- Você precisa alterar o código binário em memória para testar algo durante a depuração e não tem fácil acesso ao código fonte. É o que os hackers chamariam de “patch” pois você pode alterar o binário em memória e salvá-lo em disco se necessário. Entretanto, não alteramos código binário e o sobreescrevemos pois isso tem implicações legais, usamos essa técnica apenas para comprovar algo durante o processo de depuração.
- Você tem fonte e símbolos e o sintoma é de fácil reprodução; você não precisa ficar aguardando pela ocorrência dos sintomas.
- Post-Mortem Debug é usado quando:
- O sintoma é intermitente, então é melhor preparar o depurador para coletar um dump do processo durante sua queda ou coletar dumps durante um hang do que conectar o depurador e prepará-lo para parar e te dar controle quando o sintoma ocorrer.
- O sintoma é de memory leak, portanto, você vai querer comparar as chamadas da aplicação, o estado dela, em diferentes momentos para saber quem está alocando memória e não liberando com o passar do tempo.
- A aplicação é muito grande ou tem muitos módulos a ponto de a instrumentação de código fonte para se isolar o problema tomar muito tempo para ser implementada caso o código não tenha sido previamente instrumentado.
- Não está claro qual a aplicação ou componente onde reside o problema. Afinal, podem ser tirados vários dumps de diferentes processos, ao mesmo tempo.
SÍMBOLOS
Basicamente símbolos são arquivos de extensão .PDB (Program Database) que contém informação de depuração. Eles são gerados durante o processo de compilação da aplicação.
São úteis porque contém informação como:
- Nomes de rotinas,
- Nomes de variáveis locais,
- Número da linha de código fonte correspondente,
- Parâmetros, etc...
Portanto, ao se depurar um dump de aplicação ou a própria aplicação, o uso de símbolos vai permitir uma análise mais profunda e rápida da aplicação/dump e poupará uma maior quantidade de análise de código disassemblado.
Uma boa regra é: sempre gere símbolos quando compilando suas aplicações porque você nunca sabe quando precisará deles, e em se tratando de grandes aplicações pode ser demorado e difícil se gerar símbolos quando necessário se depurar a aplicação.
DEPURADORES
Existem vários depuradores (debugger), portanto me focarei nos que julgo serem os mais usados e conhecidos.
Visual Studio .NET – O Visual Studio é um excelente ambiente para desenvolvimento e depuração. É bastante visual, fácil de usar e certamente útil para a grande maioria dos problemas que exige depuração de aplicações. Ótimo para Live Debug.
DebugDiag – O DebugDiag é uma ferramenta de coleta e análise de dumps. Em outras palavras, você não consegue fazer Live Debug com o DebugDiag apenas Post-Mortem Debug. A grande vantagem do DebugDiag é que além de possuir uma ótima interface gráfica ele analisa os dumps de modo automatizado e gera um relatório ao final. Além disso, pode ser customizado e extendido. (https://blogs.technet.com/latam/archive/2006/03/24/423426.aspx)
Funciona também como um serviço.
O DebugDiag foi criado pelo grupo de Critical Problem Resolution de IIS (https://blogs.gotdotnet.com/debugdiag/archive/category/12709.aspx) primariamente para depurar IIS mas ele pode ser usado para depurar qualquer processo.
WinDbg – O WinDbg é a ferramenta que mais uso, juntamente com o DebugDiag. O WinDbg é nosso mais potente depurador. Ele não faz análise automatizada de dumps como o DebugDiag, mas é muito mais potente que o Visual Studio .NET, permite se fazer depuração de aplicações e de kernel, é extensível, logo é possível se criar comandos para ele sob a forma de extensões, possui muito mais recursos que o Visual Studio .NET para se ir mais a fundo na depuração com mais acesso baixo nível.
Além disso, usando-se o script ADPlus.vbs que vem junto com o WinDbg é fácil se coletar hang ou crash dumps de aplicações ou específicos de IIS.
A grande desvantagem, a meu ver, é que a curva de aprendizado é bem maior porque a ferramenta é pouco intuitiva, entretanto, para a maioria dos problemas você pode usar o Visual Studio ou o DebugDiag para isolá-los.
O WinDbg é público e o arquivo de help é bem completo. Para quem quiser baixar:
https://www.microsoft.com/whdc/devtools/debugging/default.mspx
INSTALANDO O DEBUGDIAG
Para baixar o DebugDiag: https://www.debugdiag.com
A instalação é trivial. O help da aplicação é bem documentado e é uma boa idéia ler ele antes de usar a ferramenta pela primeira vez.
A instalação típica é feita no diretório IIS Resources:
USANDO O DEBUGDIAG PARA COLETAR DUMPS
Carregue o processo DebugDiag.exe. Você deverá ver uma janela modal assim:
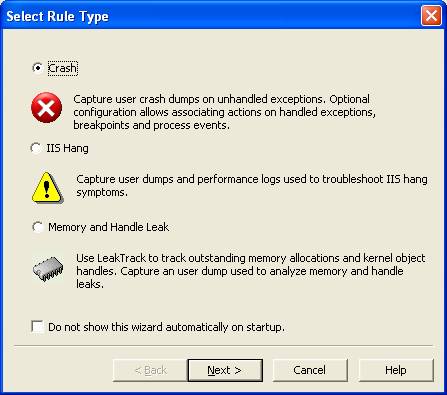
Acima você escolhe o tipo de monitoração que deve ser feita.
Em modo Crash quando o processo disparar uma exceção um dump será gerado antes da aplicação cair.
Em modo Hang um dump de processos do IIS será coletado quando houver demora na url do website para responder para a aplicação.
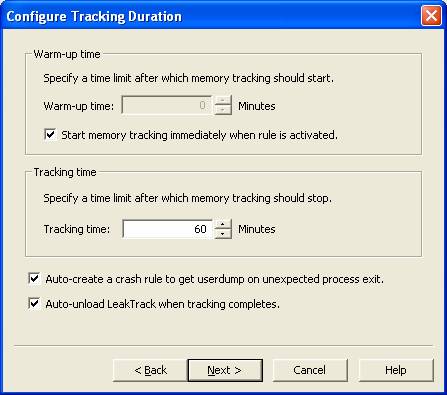
Em modo Memory and Handle Leak será injetada uma dll na aplicação que vai monitorar alocações de memória do processo durante um determinado intervalo de tempo. Então um dump será gerado.
Eis uma das telas do Wizard para a opção de Memory and Handle Leak:
A parte do modo de coleta, note que você tem 3 opções sob a forma de tab:
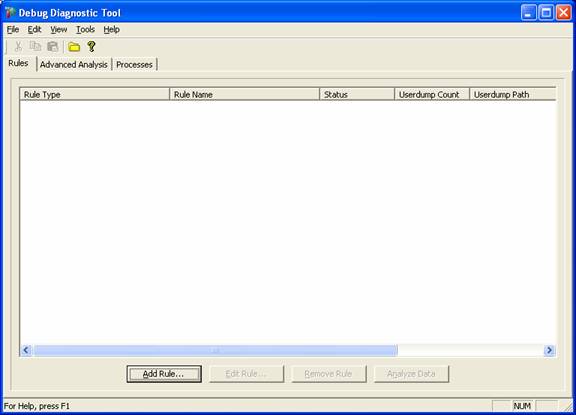
Rules refere-se as regras de Hang, Crash e Memory and Handle Leak.
Note que você pode criar mais de uma regra. Por exemplo, se você não tem certeza se o sintoma é um crash ou um hang, pode habilitar as duas regras.
Para isso basta clicar em Add Rule...
O terceiro tab, é o de Processes:
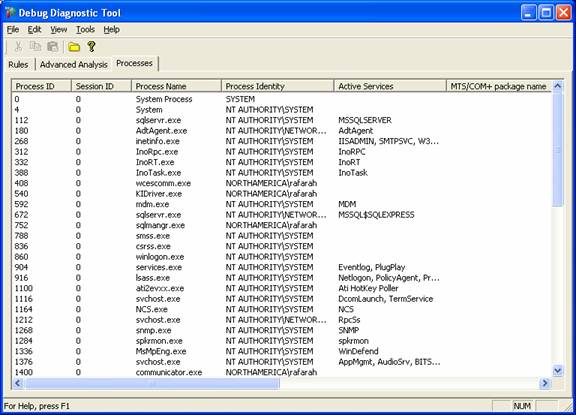
Com essa opção você pode, usando o botão direito do mouse, ativar algumas opções como:
- Monitor for Leaks (usando essa opção você pode forçar monitoração de leak)
- Create Full UserDump (usando essa opção você pode forçar a coleta de dump)
- Create Full MiniDump (usando essa opção você pode forçar a coleta de dump)
Note que o DebugDiag, por default, automaticamente coleta logs de Performance Monitor.
USANDO O DEBUGDIAG PARA ANALISAR DUMPS
Essa é a melhor feature do DebugDiag. Após coletar dumps seja com o DebugDiag ou outro depurador, você pode analisar os dumps via o módulo de análise do DebugDiag, que é o segundo tab, Advanced Analysis:
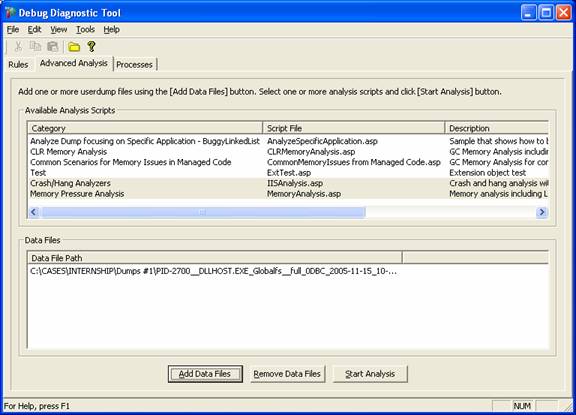
Note acima que temos o grupo de Available Analysis que contém scripts que usam extensões (dll´s ou objetos COM com que contém comandos para depurar) para fazer específica análise de dump e abaixo temos o Data File Path que é onde serão adicionados os arquivos de dumps a serem analisados.
Note que no exemplo acima foram selecionados 2 scripts específicos: Crash/Hang Analyzers e Memory Pressure Analysis.
Ok, agora basta pressionar Start Analysis para a análise automatizada iniciar. Isso pode levar alguns minutos dependendo do dump. Em seguida você terá um relatório.
Agora vem a parte realmente importante. Como interpretar um relatório de DebugDiag.
INTERPRETANDO RELATÓRIOS DE DEBUGDIAG
Dentro do diretório Reports onde o DebugDiag foi instalado é onde estarão localizados os relatórios.
Lembre-se que você pode analisar dumps coletados com outras ferramentas, e que os dumps podem ser de qualquer processo, não necessariamente de IIS.
Eis um exemplo:
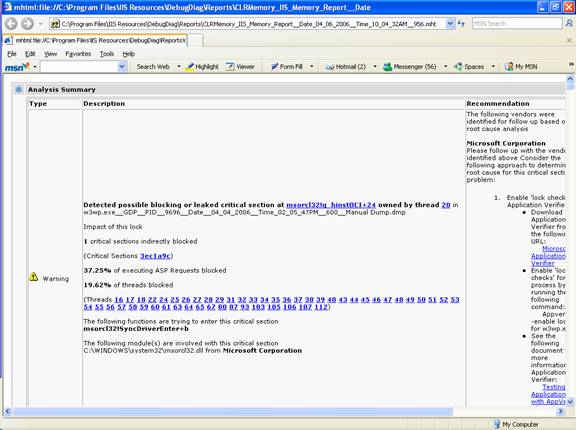
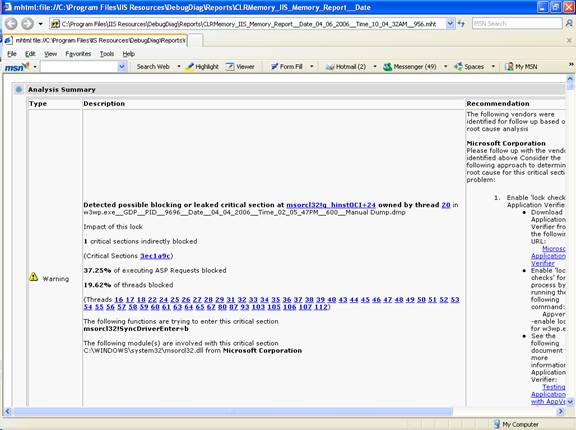
A primeira seção é uma espécie de Plano de Ações. É mostrado o tipo de problema identificado, onde Error e Warning são importantes, em seguida a descrição do problema e, por fim, a recomendação.
Note abaixo a descrição do problema onde é mostrada a porcentagem de threads ASP bloqueadas, o número das threads e o componente causador.
Ao se clicar nos links em azul você terá um detalhamento de cada coisa.

Depois de Tipo e Descrição temos, mais a direita, a Recomendação:
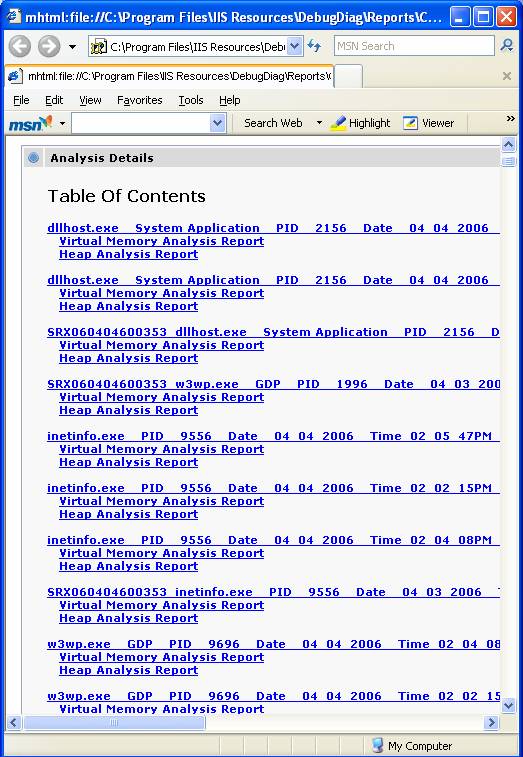
Abaixo a vista completa. Note que essa informação, independente do resto do relatório é suficiente para mostrar que o hang ocorrendo no dump em questão é devido a serialização de Critical Sections ao redor do driver msorcl32. Inclusive é possível ver quais e quantas são as threads presas!
Após o Sumário da Análise temos os Detalhes da Análise:
Novamente, ao clicar nos links acima, que equivalem a vários dumps analisados de uma vez, temos o detalhamento por dump.
Na mesma seção, mas descendo mais temos:
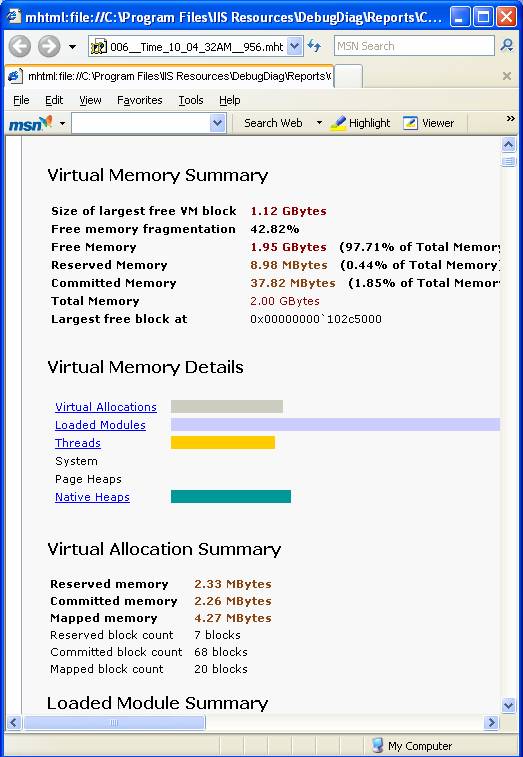
Há uma completa análise da memória, com detalhamento, gráficos, etc.
Fica fácil se identificar quem está consumindo mais memória e quanto a mais.
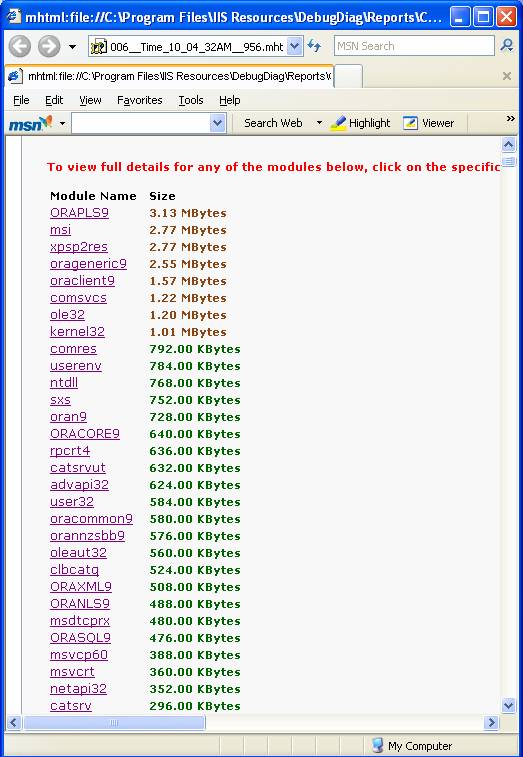
Temos todos os módulos carregados pelo processo:
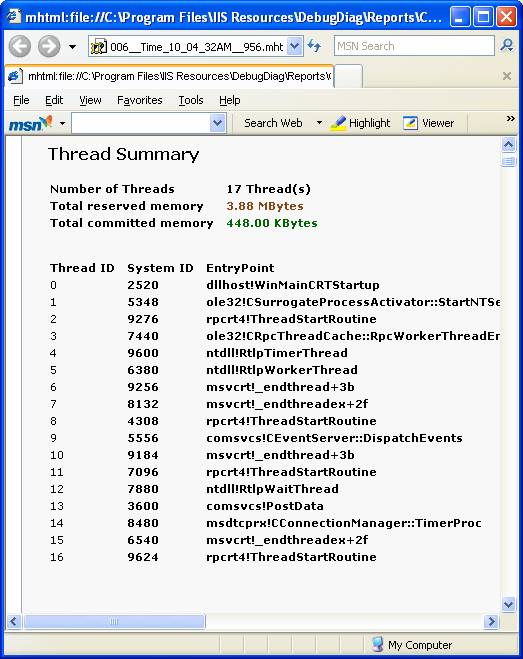
Sumário do que as threads estão fazendo:
Sumário de alocações no Heap:
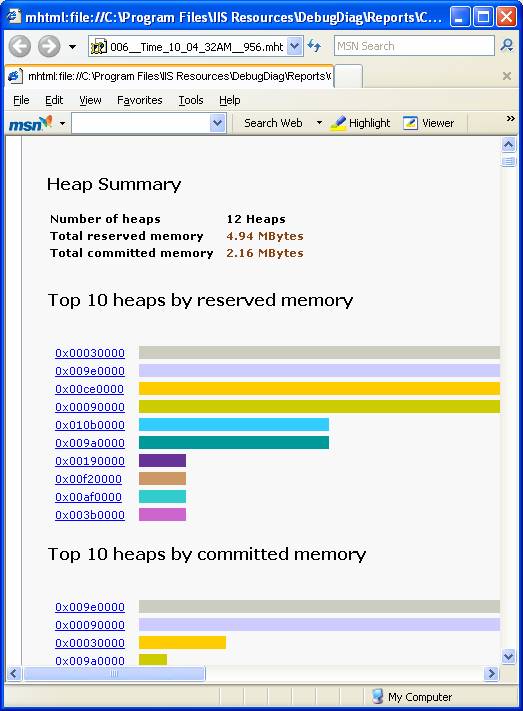
Em seguida temos o detalhamento de cada área do Heap:
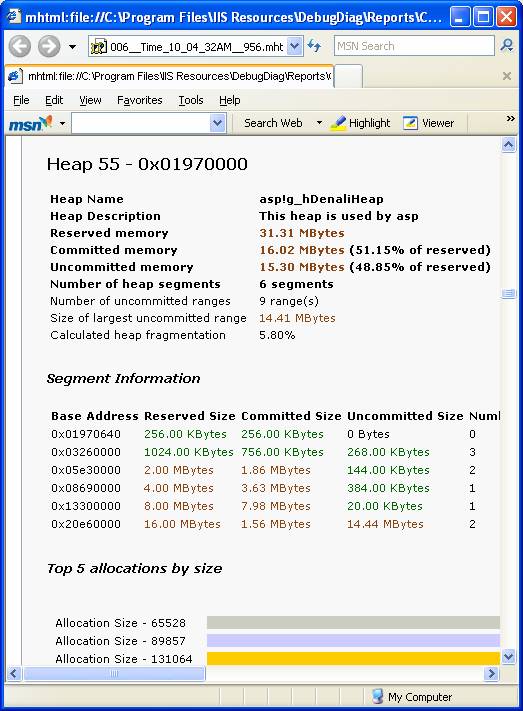
Indo mais para baixo no relatório temos a call stack, ou seja, a pilha de cada thread com uma breve descrição dela:
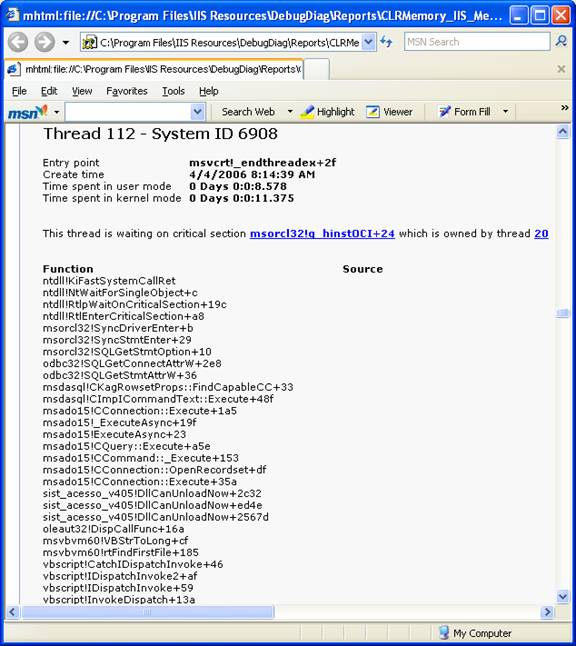
Essa informação é extremamente útil para os desenvolvedores porque mostra onde iniciou a chamada.
No exemplo acima temos a clara explicação que a thread está bloqueada, aguardando a Critical Section que msorcl32 apropria na thread 20.
Note, abaixo, que ao final da stack, se for uma thread ASP é mostrada a linha de código fonte do ASP sendo executado!!!
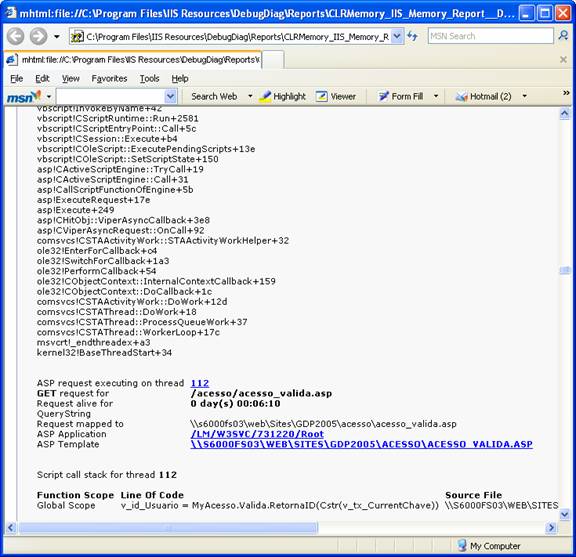
Reparem no detalhamento da informação acima!
Após a call stack das threads temos o detalhamento de chamadas COM e o estado de algumas configurações do IIS.
No exemplo abaixo, note a quantidade de threads esperando para apropriar uma Critical Section, ocasionando o cenário de hang.
Detalhes das threads ATQ do IIS e do número de conexões e o detalhamento de cada conexão! Omiti essa parte justamente por ter informação confidencial.
Posteriormente temos um relatório completo do ASP:
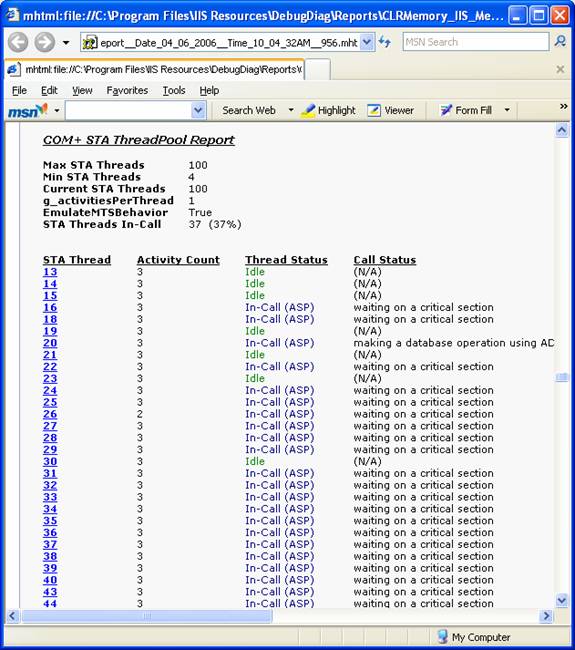
Incluindo os detalhes de cada thread processando páginas ASP!
Posteriormente temos um relatório do ASP Template Cache, ou seja, as páginas ASP que estão no cache de templates.
Novamente omito essa informação por revelar detalhes confidenciais.
Ao final temos os Scripts de depuração que foram usados e eventual informação de erro do processamento dos scripts:
CONCLUSÃO
Usando o DebugDiag, mesmo sem ter conhecimento algum de desenvolvimento/depuração, objetos de sincronização de threads, etc.. você pode coletar dumps de processos suspeitos de modo rápido e fácil, além de análisá-los de modo completamente automatizado!
A análise tem uma recomendação do que deveria ser feito em relação ao problema e rica informação técnica logo na primeira parte, portanto, salvo se você precisar de mais detalhes a informação inicial é suficiente para, no mínimo, dar uma boa pista de onde o problema está localizado.
Note que a informação acima poderia ser um pouco diferente dependendo do script de depuração sendo usado e do processo, se é um processo do IIS ou não, entretanto, a forma geral de apresentação é a mesma.
A recomendação do relatório é bastante genérica, mas a descrição do problema encontrado e a informação técnica é extremamente valiosa para os desenvolvedores!
Aqui https://blogs.technet.com/latam/archive/2006/03/24/423426.aspx no exemplo número 2 há um script que usa a extensão SOS.DLL para analisar problemas de memória de aplicações .NET. No artigo há o link para download.
Nota importante! É necessário se configurar o DebugDiag para acessar os símbolos do Windows e, melhor ainda, se puder acessar também os símbolos das aplicações contidas no dump, para se ter uma análise ainda mais detalhada. O help do DebugDiag na parte de Symbols, explica detalhadamente isso.
Como teste você pode criar uma aplicação com um bug proposital para gerar um ou mais dos sintomas descritos acima, usando símbolos (.PDB) de preferência, configurar os símbolos públicos do Windows, coletar dumps com qualquer depurador ou com o DebugDiag e analisá-los com o DebugDiag.
Particularmente no meu trabalho SEMPRE uso DebugDiag para fazer uma primeira análise de dumps recebidos de clientes, assim posso economizar muito meu tempo, dispensando dumps inúteis e focando a análise em informações que extraio do relatório gerado pelo DebugDiag.
Vejo vocês no próximo artigo! J