オンプレミスとクラウドのハイブリッド Hadoop データ パイプラインを Hortonworks と Cortana Analytics で実現
このポストは、2 月 1 日に投稿された On-premises and cloud hybrid Hadoop data pipelines with Hortonworks and Cortana Analytics の翻訳です。
Azure Data Factory と Hortonworks Falcon (英語) のチームはこのたび、ハイブリッド Hadoop データ パイプラインの構築を可能にする機能のプライベート プレビュー版を共同発表しました。この機能では、オンプレミスの Hortonworks Hadoop クラスターとクラウド ベースの Cortana Analytics サービス (HDInsight Hadoop クラスターや Azure Machine Learning など) を組み合わせて活用します。
オンプレミスで Hadoop ベースのデータ レイクを管理しているお客様の多くは、オンプレミスのデータ レイクをクラウドに拡張してハイブリッドのデータ フローも利用できるようにしたいと考えています。その理由は次のようにさまざまです。
- PII や他の機密情報はプライバシーやコンプライアンス上の問題からオンプレミスに保持したいが、機密情報には当たらないワークロードについては柔軟なスケールでクラウドを活用したい
- リージョン間レプリケーションや災害復旧の目的でクラウドを活用したい
- 開発やテスト環境用にクラウドを活用したい
このようなハイブリッド シナリオを前にして、個別の ETL・データ パイプライン ソリューションを 2 つ用意しても、それぞれのデータ フローをまとめて確認する方法がなく、分断された状況に行き詰まっているお客様は少なくありません。そうした課題を解消するのが、今回プライベート プレビューで提供されるハイブリッド パイプラインです。これを使用すると、オンプレミスとクラウドにまたがるデータのフローと依存関係全体をクラウド ベースのデータ ファクトリとしてモデル化し、視覚化することができます。データ ファクトリ向けの業界最高レベルのこの管理ツールを活用することにより、不具合のある箇所を特定し修正することから、ジョブの実行状況にかかわらず失敗したワークフローを再実行することまで、効率的な運用が可能になります。
ハイブリッド Hadoop パイプラインでは、オンプレミスの Hadoop クラスターをコンピューティング対象として追加し、データ ファクトリでジョブを実行することができます。クラウドの HDInsight ベース Hadoop クラスターのような他のコンピューティング対象を追加するのと同様です。
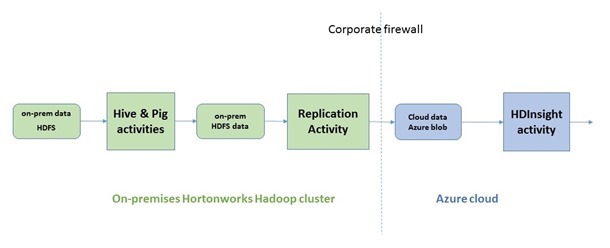
オンプレミスのクラスターとデータ ファクトリ サービスは、わずか数クリックで安全なチャネルを使用して接続できます (GitHub のサンプルは記事の最後のリンクからご覧ください)。接続が完了すると、上の図に示したように、ハイブリッド パイプラインを作成して以下を行うことができます。
- データ ファクトリ内の新しいオンプレミスの Hive アクティビティと Pig アクティビティを使用して、Hadoop の Hive と Pig のジョブをオンプレミスでオーケストレートする
- 新しいオンプレミスのレプリケーションアクティビティを使用して、オンプレミスの HDFS のデータをクラウドの Azure Blob にコピーする
- パイプラインにさらに処理を追加し、クラウドで Hadoop HDInsight アクティビティなどを使用してビッグ データ処理を続ける
プライベート プレビュー版は、ごく一部のお客様に提供されます。この機能にご興味のある方は、こちらの短いアンケート (英語) にご回答ください。お客様の用途が適していると判断された場合にこちらからご連絡させていただきます。
既にプライベート プレビュー版をご利用の場合は、GitHub のサンプル (英語) をご覧ください。ハイブリッド パイプラインを有効化する方法や、データ ファクトリと Falcon 間でデータをやり取りする方法、セットアップ方法の具体的な手順が詳細に記載されています。