Azure Data Lake のご紹介: ビッグ データをより使いやすくするためのマイクロソフトの取り組み
このポストは、9 月 28 日に投稿された Introducing Azure Data Lake – Microsoft’s expanded vision for making big data easy の翻訳です。
今週は 2 つのビッグ イベントの開催が予定されています。1 つは AzureCon (英語) で、マイクロソフトはこれに向けて着々と準備を進めています。もう 1 つはニューヨークで開催される Stata + Hadoop World で、ビッグ データ関連の大きなイベントとなっています。今回マイクロソフトは、このタイミングで、Azure Data Lake の新機能の導入と機能強化を発表 (英語) しました。Azure Data Lake は、ビッグ データの処理と分析のスムーズな実行とアクセス性を強化する新しい Azure サービスです。
Build カンファレンス (英語) の際には、Azure Data Lake Store を発表 (英語) しました。Azure Data Lake Store は、サイズや種類を問わずさまざまなデータを簡単に取得し、どのようなスケールのデータでもアプリケーションを変更することなく高速に処理することができる単一のリポジトリです。データを安全に共有して共同作業を行ったり、HDFS アプリケーションや HDInsight、Hortonworks、Cloudera、MapR などのツールを利用して処理や分析を実行することができます。
本日新たに分析サービスが追加され、また、既存の Azure HDInsight ソリューションが Azure Data Lake に追加されました。これにより、マイクロソフトが描いていたビジョンが完全に公開されたことになります (英語)。私たちの目標は、ビッグ データ テクノロジをよりシンプルに、より使いやすいものにして、より多くの皆様にご利用いただけるようにすることです。Azure Data Lake (英語) ではあらゆるサイズのデータの格納、加工、高速処理が可能であり、ここに含まれるさまざまな機能を使って、開発者やデータ科学者、アナリストの皆様が馴染みのプラットフォームや言語で簡単に処理や分析を行うことができます。このため、膨大なデータの取得と格納にかかる労力が大幅に減り、バッチ形式、ストリーミング形式、対話形式での分析の準備と実行にかかる時間が大きく短縮されます。Azure Data Lake では、ID、管理、セキュリティ目的で使用している IT 資産を活用できるため、データの管理や統制も簡単にできます。さらに、運用中のストレージやデータ ウェアハウスとシームレスに統合できるため、現在使用しているデータ アプリケーションを拡張することも可能です。
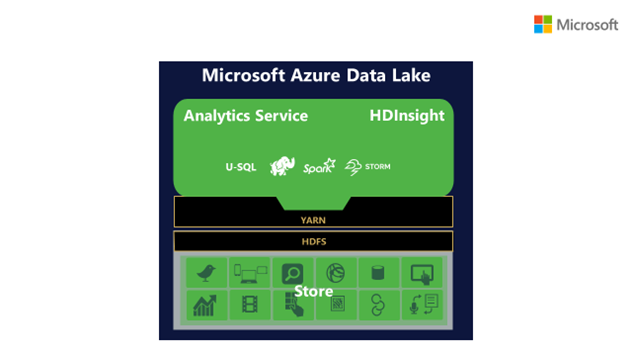
今回導入された新機能
Azure Data Lake Store のほかに、新しい分析サービスである Azure Data Lake Analytics (英語) も発表されました。このサービスの注目点は、ソリューションを実行する分散型インフラストラクチャではなくアプリケーションのロジックで、ハードウェアの展開、構成、調整を行うことなくデータを変換するクエリを作成して価値ある情報を抽出できることにあります。このサービスは Apache YARN を基盤とするクラウドに最適化された設計となっていて、必要な処理速度に応じてダイヤルを設定するだけでどのようなスケールのジョブにもすぐに対応できます。また、従量課金のサービスであるためコスト効率が高いほか、Azure Active Directory がサポートされていることから、簡単にアクセス許可やロールを管理したりオンプレミスの ID システムと統合したりすることができます。
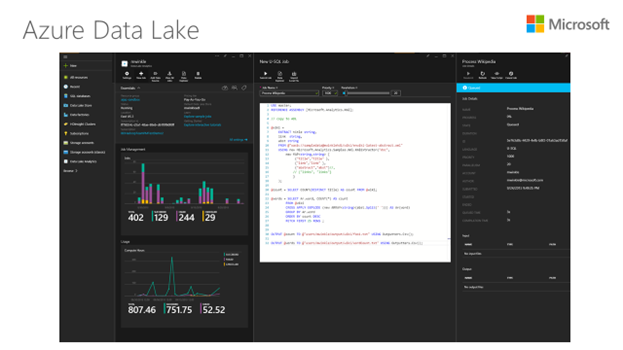
現在、多くの開発者やデータ科学者が既存のテクノロジやツールを使用してビッグ データの活用に取り組んでいますが、Azure Data Lake Analytics では U-SQL (英語) 言語を使用できるため、既存の強力なコードと SQL のメリットを統合することができます。U-SQL 言語は、マイクロソフト内部で使用しているビッグ データ システムで利用されているものと同一の分散型ランタイムで構築されています。SQL および .NET の開発者の方々は、あらゆるデータの処理や分析に現在のスキルを活用できます。

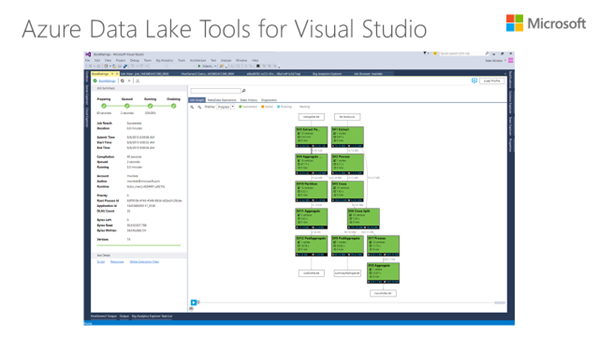
Azure Data Lake Tools for Visual Studio では、U-SQL の最新のオーサリング機能、デバッグ機能、高度なパフォーマンス分析機能がサポートされているため、膨大な数のノードでジョブを実行する場合に最適化して生産性を向上させることができます。U-SQL コードを視覚化すると、そのスケールでコードがどのように実行されているかを確認し、パフォーマンス上のボトルネックやコストの最適化について把握したうえで、クエリの調整を簡単に行うことができます。
Azure HDInsight が Azure Data Lake の主要機能に
Azure Data Lake では、Apache Hadoop ベースのサービスである HDInsight が重要な役割を果たしています。HDInsight はマイクロソフトが監視およびサポートしているマネージド サービスで、Hadoop エコシステムを幅広く活用するものであり、Azure の中でも急速に成長しているサービスの 1 つです。このサービスでは、生産性向上の取り組みを進めるために、Visual Studio ツールを更新して HDInsight のオーサリング機能、高度なデバッグ機能を強化し、Hive クエリと Storm トポロジの調整を行いました。
また本日、Linux 向けの HDInsight の一般提供開始が発表されました。Hortonworks (英語) および Canonical (英語) との緊密な協力により、Ubuntu オペレーティング システムで HDP™ ディストリビューションを提供し、Data Lake で Linux バージョンの HDInsight を利用できるようにしました。これも、このサービスを環境を選ばず簡単にご利用いただくための 1 つの重要な取り組みです。また、これはマイクロソフトがかねてより公言してきた「オープン性」を象徴するものでもあり、.NET Core のオープン ソース化や Apache Hadoop への取り組み (英語)、Docker コンテナーのサポート (英語) といった成果からもおわかりいただけるかと思います。このオープン性への取り組みは、Windows 以外の選択肢として、Linux でも Hadoop ワークロードを実行できるようにするために必要なものです。マイクロソフトでは引き続きオープン性を拡大するために、業界の各方面と連携を図り、お客様の声に応えていきたいと考えています。最近では、人気のオープン ソース ビッグ データ プロジェクトである Apache Spark を新たにサポート (英語) したほか、GitHub では完全な Power BI の視覚化フレームワーク (英語) の開発にも取り組んでいます。

Linux 用 HDInsight は、Strata + Hadoop World で初めてパブリック プレビューが発表 (英語) され、パートナー様とお客様の両方から高い評価を得て多方面でご採用いただきました。Linux でアプリケーションをオンプレミスの Hadoop に統合している Hadoop エコシステムのパートナー様 (英語) も多数いらっしゃいますが、現在は HDInsight をクラウドに統合するための開発に取り組まれています。これには、エンドツーエンドのビッグ データ分析を行う Datameer (英語)、ビッグ データのセキュリティや統制を行う Dataguise (英語) や BlueTalon (英語)、ストリーム処理やバッチ処理を統合する DataTorrent (英語)、さらに、ビジネス ユーザーにわかりやすい形でデータの視覚化と分析を可能にする AtScale (英語) や Zoomdata (英語) などのアプリケーションがあります。Azure Data Lake では各マイクロソフト パートナーのサポートを受けて、最適なアプリケーションをご利用いただけます。
Linux 向けの Azure HDInsight の一般提供開始に伴い、Hadoop からその基盤の Linux OS に至る 99.9% の可用性を保証するサービス レベル アグリーメントがすべてのお客様に適用され、すべてのスタックでテクニカル サポートが完全に提供されます。
マイクロソフトは、ビッグ データと分析機能をより使いやすくするために、Azure Data Lake への取り組みをさらに強化していきます。今週は AzureCon (英語)、そして Stata + Hadoop World (英語) が開催されるニューヨークでお会いしましょう。さらなる魅力的な情報をもってお待ちしています。
また、Azure でのビッグ データの簡単な活用方法を紹介したビデオもありますので、そちらもぜひチェックしてください。
関連情報
- 今回の発表に関する詳細情報は、T.K. “Ranga” Rengarajan が執筆したこちらのブログ記事 (英語) でご確認いただけます。
- ビッグ データ処理用の新しい言語に関する詳細については、U-SQL に関する Visual Studio ブログ記事 (英語) を参照してください。
- Data Lake ソリューションに関するページは、こちら (英語) から参照してください。
- Azure でのビッグ データの簡単な活用方法については、こちらのビデオ (英語) をご覧ください。
- Hortonworks HDP で Linux 向けの Azure HDInsight を使用する方法については、Hortonworks のブログ記事 (英語) を参照してください。
- Ubuntu で Linux 向け Azure HDInsight を使用する方法については、Canonical のブログ記事 (英語) を参照してください。