VM で発生するイベントを事前に把握するには: VM 内部通知サービスの紹介
パブリック クラウドでサービスを実行している所有者の方は、「仮想マシン (VM) で次にどのようなイベントが発生するのか?」という質問を受けたことがあるのではないかと思います。この記事をお読みいただければ、その質問に適切にお答えいただけるようになります。この記事では、VM でイベントが発生する 5 分前に、サービス所有者がイベントの内容を把握する方法を説明します。
Azure で VM を実行するメリットの 1 つに、可用性セットごとに VM をグループ化して冗長性を確保できるという点があります。これにより、プラットフォームの計画的なメンテナンスが実行されている間や予期しない問題が発生した場合でも、サービスの稼動状態を常に維持することができます。Azure が特定のノードの問題を検出すると、その VM はプロアクティブに新しいノードに移行され、アクセス可能な実行中の状態が復元されます。また、更新の際には VM の再起動が必要になる場合があります。このようなイベントが発生する場合はマイクロソフトが事前にメールで通知しますが、より長い準備期間がほしいという場合もあるかと思います。
サービスによっては、イベントがいつ発生するか事前に知っておくことが重要です。これからご紹介する機能を利用すれば、いくつかの手順を実行するだけで、エンド ユーザーへのサービス中断の影響を最小限に抑えられるようになります (影響が完全になくなることもあります)。ここでは、VM 内部メタデータ サービスをご紹介します。このサービスは IETF 3927 (英語) に基づくもので、同一の物理ノードに接続された他の VM と 169.254/16 のアドレス範囲内で通信する場合に使用する動的なネットワーク構成が可能です。
使い方
VM 内部メタデータ サービスでは、下記のコマンドを実行して標準的なメソッドで VM のメンテナンス状態を取得できます。
curl https://169.254.169.254/metadata/v1/maintenance
このコマンドの標準的な結果セットには、InstanceID、配置のアップグレード ドメイン、配置の障害ドメインの 3 つの属性が含まれます。現在のメンテナンス アクティビティの開始が近い場合 (5 分以内)、さらにメンテナンス イベントが追加されます。
通常の結果
{}
VM の再起動が近い場合の結果
{
"EventID": "6f0a13a3-dc0d-4bbe-ab24-df710a3917e6",
"EventCreationTime": "9\/15\/2015 6:42:51 AM"
}
このサービスを使う理由
このサービスの使い方は簡単で、どの OS でも実行できます。VM からプル ベースで使用できるため、DevOps チームはこのサービスを使って VM の状態をほぼリアルタイムで把握することができます。そうすれば、可用性の問題が起きてもエンド ユーザーに知られることなく、サービスの可用性も向上します (基本的な可用性ログの記録や次に起きる再起動イベントに対するプロアクティブな対応が可能になります)。
VM 内部メタデータ サービスを使用するシナリオとしては、次の 2 つがあります。
1. システムでイベント ログを記録する場合: この場合、サービス所有者は定期的にデータを取得して EventLog (Windows の場合) または syslog (Linux の場合) に保存し、リソースの可用性を追跡します。
2. 再起動をエンド ユーザーに知られないようにする場合: 次に起きる再起動イベントをその場で追跡し、再起動される VM からトラフィックを他の VM に移動します。VM は、VM 内部メタデータ サービスで取得した動的な情報に基づいて、可用性セットから除外することができます。
再起動のログ記録はシンプル
下の例は、Azure VM で次に実行される再起動が、標準的なログ (Windows では EventLog、Linux では syslog) にどのように記録されるかを示しています。IsVmInMaint.ps1 (英語) が 5 分おきに実行されるように設定されていて、VM の再起動が近い場合は EventLog にイベント ログが記録されます。
$result=curl https://169.254.169.254/metadata/v1/maintenance | findstr -i EventID
if ($result) {Write-EventLog -LogName Application –Source "IsVmInMaint" -EntryType Information –EventID 1 –Message "Incoming VM reboot"}
IsVmInMaint.sh (英語) でも同じ操作が可能です。この場合、IsVmInMaint.sh が 5 分おきに実行されるように crontab に登録されている必要があり、Linux の syslog を使用して次の再起動イベントのログが記録されます。
#!/bin/bash
result=`curl https://169.254.169.254/metadata/v1/maintenance | grep -i EventID`
if [ -n $result ]; then
`logger Incoming VM Event`
fi
再起動をエンド ユーザーに知られないようにする
下の図 1 は上の 2 つ目のシナリオを示したもので、ロード バランサーが構成された 1 層構造のシンプルな分散型アプリケーション (可用性セット) であり、ソース IP でのセッションを維持しようとします (クライアント i の最初の要求が VM1 に送信された場合を示しています)。
その後に続くすべての呼び出しは、VM1 が稼働している限り VM1 に送信されます。他のクライアントでは、ロード バランサーにより取得された稼働中の VM の負荷状態に応じてサービスが実行されます。
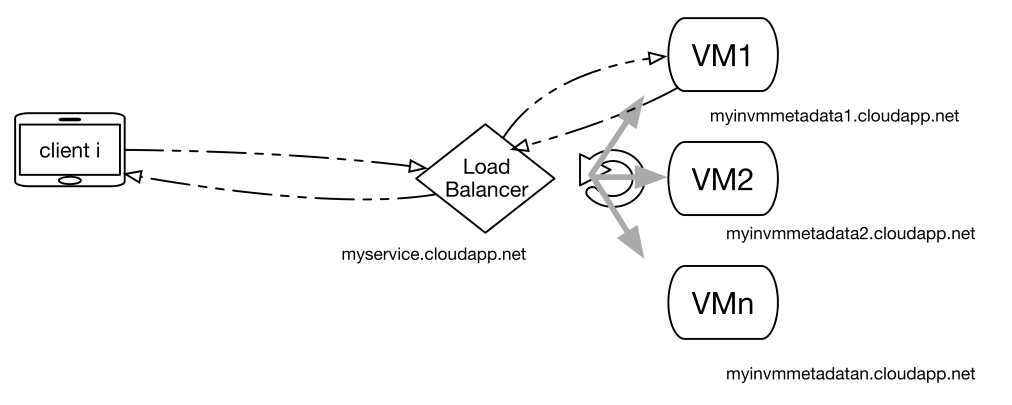
図 2 は、VM1 がメンテナンス中であり、サービスを (1) VM1 のエンドポイント (https://myinvmmetadata1.cloudapp.net/) から新しいクライアント セッションにプロアクティブに移動し、(2) VM1 をロード バランサーの稼動状態の分散対象から除外して、稼動状態のエンドポイントを https://myinvmmetadata2.cloudapp.net/ および https://myinvmmetadata3.cloudapp.net/ に変更する場合を示しています。
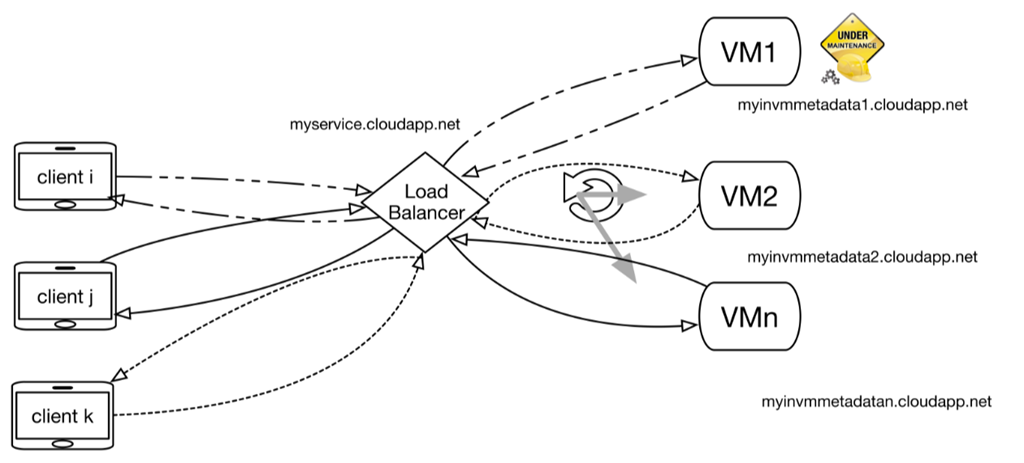
この時点では、影響を受ける VM がロード バランサーのトラフィック マネージャーに対してコマンドを実行し、その後のトラフィックの分散対象から除外することができます。最終的には VM が稼動状態に戻り、稼動状態のエンドポイントのプールに追加されます。
参考資料
VM をロード バランサー プールに追加する: Add-AzureEndpoint (英語)
エンドポイントを検証する: Get-AzureEndpoint (英語)
ロード バランサー プールからエンドポイントを削除する: Remove-AzureEndpoint (英語)
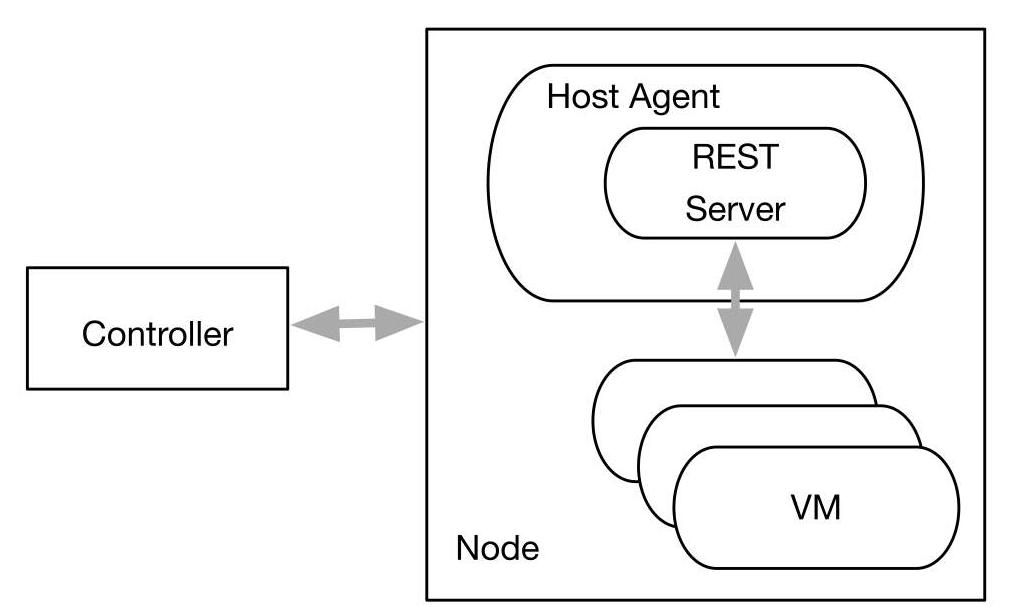
しくみ
インスタンスのメタデータ サーバーは HTTP サーバーで、メイン コントローラー コンポーネントからのコマンドを受信したホスト エージェント (ノード) からのデータを返します (図 3)。コントローラーがノードでコマンドの実行を開始すると、リポジトリに保存され、そのままアクティビティの実行中は有効な状態が保持されます (計画的なメンテナンスやサービス回復処理など)。
図 3 はここで示した通信フレームワークのしくみを単純に図解したものです。VM が通信可能な場所は REST サーバーのみで、インスタンスのメタデータ サーバーでは RFC3927 (英語) で割り当てられている 169.254/16 のような標準的なリンク ローカル アドレスを使用します。