Application Insights のパフォーマンス バケット
このポストは、9 月 21 日に投稿された Performance Buckets in Application Insights の翻訳です。
この記事では、Application Insights を使用して、検出にかかる平均所要時間 (MTTD) を最小化する方法について説明します。具体的には、トリアージ (優先順位付け) の方法、問題の影響の評価方法、問題の診断方法を取り上げます。また、このシナリオの中で、「検出-トリアージ-診断」プロセスを効率化させる新機能「パフォーマンス バケット」を紹介します。
Applications Insights は、アプリケーションのパフォーマンス、可用性、使用状況の監視を行うサービスであり、アプリケーション ライフサイクル (英語) において特に重視されています。今回は Web アプリケーションのパフォーマンスに関する検出-トリアージ-診断のプロセスを詳しく説明します。

検出: サーバーの応答が遅い
Application Insights の [Service Overview] ブレードでは、アプリケーションのステータスを大まかに把握できます。このブレードの主なグラフの 1 つに、サーバーの平均応答時間があります。また、よく使うアプリケーションをスタート ページにピン留めしたり、毎日チェックするメトリックのビューを作成することが可能で、遠隔測定データにすばやくアクセスすることができるようになっています。
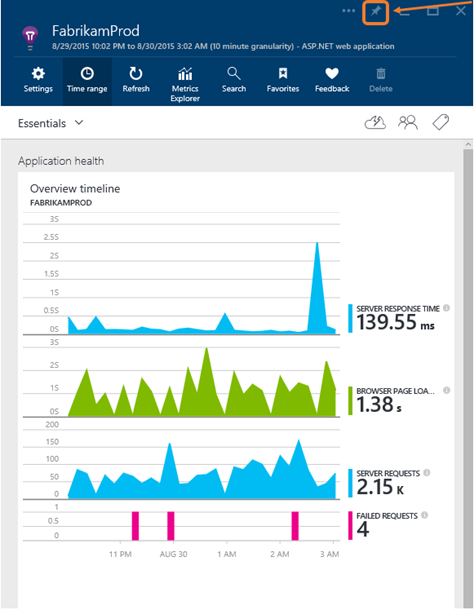
Application Insights を実行すると、毎朝、主なサービスの正常性を手軽に確認することができます。また、ダッシュボードを確認すれば、何らかの異常があった場合にすぐに気が付き、対応することができます。メトリックには応答時間が含まれています。皆さんのチームでも似たようなプロセスを採用しているのではないでしょうか?
同期処理を毎日実行していただければマイクロソフト側で異常を発見することはできますが、パフォーマンス問題の検出にかかる平均時間をできるだけ短くするには、サーバーの応答時間にアラートを設定することをお勧めします。Application Insights にはアラート機能があり、サーバーの平均応答時間が異常な値になるとそれを知らせてくれるようになっています。
アラートを設定する
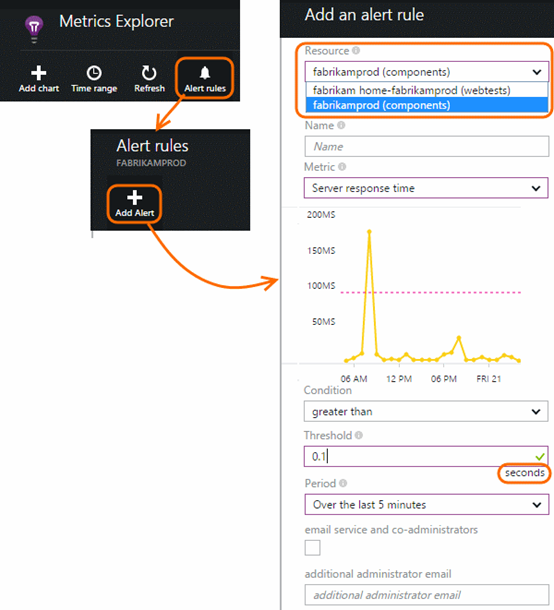
では、平均応答時間が長すぎる場合のアラートの設定方法をご説明します。
メトリックで異常な値が記録された場合にメール通知されるようにアラートを追加します。宛先には、アカウント管理者の他に特定のメール アドレスも設定できます。アラート ルールを追加するには、[Alert rules]、[Add Alert] の順にクリックします。
トリアージ: 問題の深刻度を判断する
アラートを受信したら、次はその問題がどのくらい深刻なものであるかを判断する必要があります。すべてのユーザーやページに影響があるのか、一部のみなのか、ブラウザーの種類やユーザーの所在地によって影響が異なるのかなどを細かく知ることが重要です。Application Insights では URL やブラウザー、都市などのプロパティごとにメトリックが分類されるので、その相関関係を確認することができます。プロパティごとの平均応答時間を確認するには、[Server responses] ブレードにグラフを追加します。
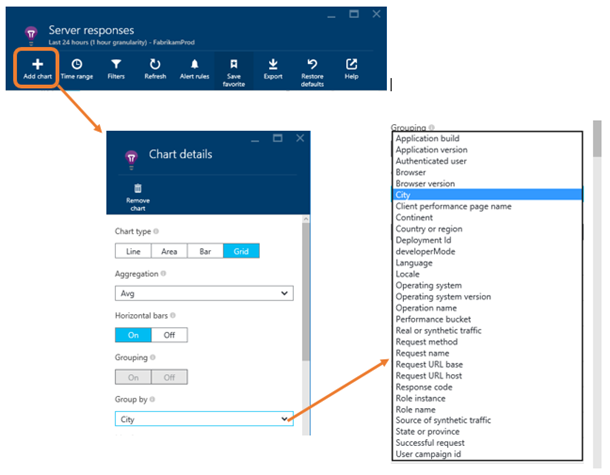
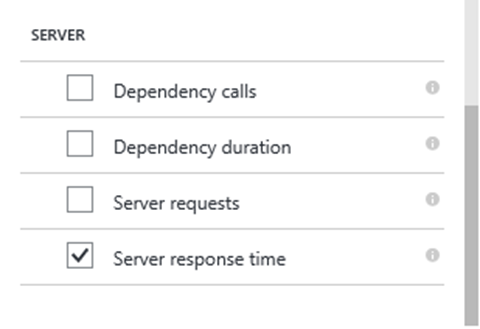
グループ化するプロパティを選択したら、スクロールして [SERVER] を表示し、[Server response time] を選択します。
これで、選択したプロパティに関するサーバーの平均応答時間が表示されるようになります。以下は [City] を選択した場合の例です。
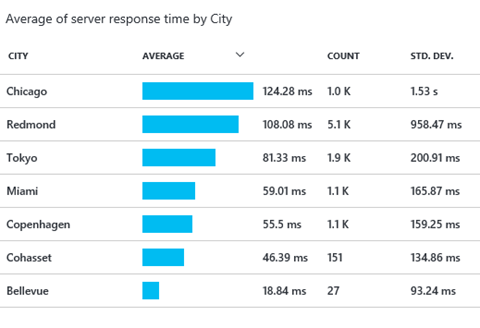
パフォーマンスへの影響が最も大きいプロパティを特定したら、そのプロパティに関するすべての要求にフィルターを適用できます。
トリアージでの目標の 1 つは、適切なサーバー応答時間を超えるページ要求を特定し、問題の根本原因を判断できるようにすることです。問題のページ要求を特定できたら、診断に進めます。
これまでは、すべてのサーバー要求のリストを 1 つずつ検索しなければ個々の要求を確認することはできず、応答時間に問題があるものをすばやく見つけることはできませんでした。こうした一方向の検索は非効率であるだけでなく、一般的なインスタンスで膨大な数の要求を確認するのはきわめて面倒でした。マイクロソフトはこの問題を解消するために、パフォーマンス バケットという新機能を導入しました。
パフォーマンス バケット
パフォーマンス バケットを使用すると、特定の時間範囲 (バケット) 内のサーバー応答時間の合計を表示することができます。
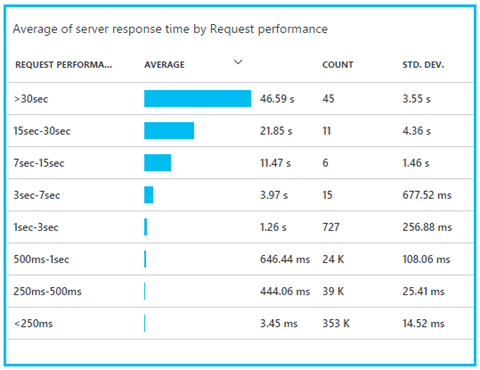
ここでは、応答時間の分布がひと目でわかるだけでなく、応答時間をバケット順に並び替えることができます。またここから、適切な応答時間を超えた要求に直接アクセスすることができます (応答時間に問題のない要求をスクロールしていく手間が省けます)。
また、パフォーマンス バケット内でフィルターを適用することもできます。バケットを選択すると、該当する応答時間の範囲内の要求がすべて表示されます。特定のプロパティを持つ要求のみを表示する場合は [Filters] からフィルターを選択します。下の図は、サーバーの応答時間が 250 ~ 500 ミリ秒の要求のうち、都市が「Redmond」のもののみを表示するようにフィルターを適用するプロセスを示したものです。
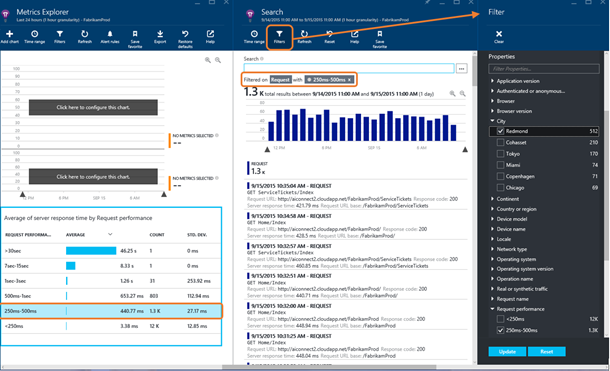
フィルターを適用したら [Update] をクリックします。下の図は、応答時間が 250 ~ 500 ミリ秒の範囲の要求のうち、都市が「Redmond」のリストを表示した状態です。
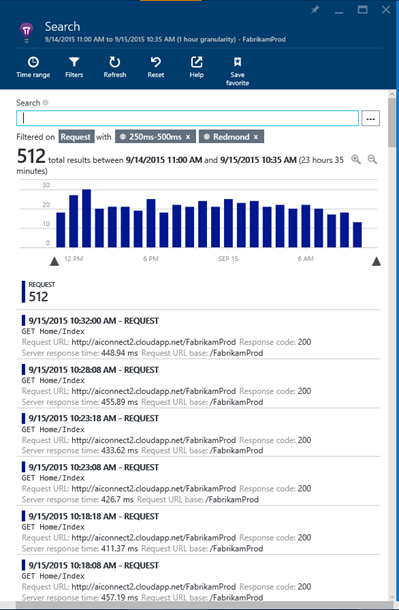
パフォーマンス バケットごとにグループ化しフィルターを適用することで、応答が遅いページと速いページの平均パフォーマンスがわかるようになります。ここで、応答が速いページの数が減少した、キャッシュ ミスの回数が増加した、応答が遅いページの呼び出しが増えた、応答が遅いページを実行しているユーザーが増えたなどのさまざまな可能性を調査できます。サーバーの応答時間の問題を修正する際にこのパフォーマンス バケットを使用すると、応答が遅い要求をすばやく特定できます。これで、サーバーの応答が異常に遅い要求を特定できたので、最後の段階である診断に進めます。
診断: 応答が遅い理由を調べる
これまでの作業で、サーバーの応答が遅いインスタンスを特定することができました。ここからはその理由を調査します。問題をどのように修正するかを見極めるには、サーバーの応答がなぜ遅いのかを突きとめることが重要です。さまざまなテレメトリを使用して、原因を正確につかみます。
場合によっては、新しい SQL クエリや HTTP 要求/サービスの呼び出しがサーバーの平均応答時間に影響していることがあります。問題のクエリを特定するには、依存関係の監視を強化するようにします。依存関係の監視によって、外部サービスへの呼び出し (データベースや REST サービスなど) の数を把握し、それぞれの呼び出しの成否と応答時間をログに記録します。たとえば、サービスへの要求にかかる時間が 4.2 秒で、そのうちウェアハウス サーバーでかかる時間が 4 秒である場合は、それが問題であると考えられます。
また、サーバーの応答が遅くなる他の理由として、キャッシュ ミスの回数が増加していることが考えられます。その場合、トレース イベントまたはメトリックのログ記録を使用すると、キャッシュ ミスが増加しているかどうかがわかります。トレース イベントのログは、プロセスの主要なポイントを記録する場合と内部インターフェイスでの問題をトレースする場合の両方で重要です。また、トレース イベントのログは、問題がバックエンドとフロントエンドのどちらで発生しているかを判断する場合にも便利です。
診断の目的は、できる限りすばやい修正、テスト、リリースが要求されるコードの欠陥なのか、スケール アップすることで解決されるリソースの問題なのか、あるいは外部サービス関連の問題なのかなど、問題の原因を特定することです。
診断に関するさらに詳しい情報については、Victor Mushkatin のブログ記事 (英語) を参照してください。
まとめ
パフォーマンス バケットを活用することで、トリアージから診断に進むプロセスが格段にスムーズになります。パフォーマンス バケットのビューでサーバーの応答時間の概要と分布を手軽に確認し、問題の検出、トリアージ、診断をすばやく終えて、問題を修正することができます。これで実際に問題が起きても、自信を持って修正プロセスに対応することができるはずです。