港湾の水際対策! 人工知能でヒアリを防げ!

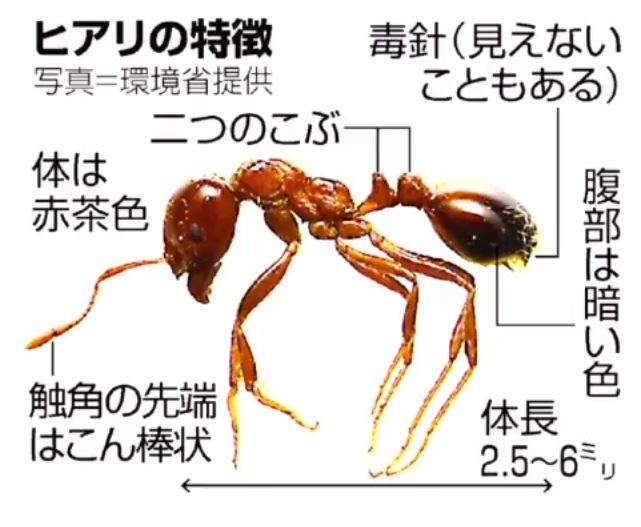
今年、日本上陸が話題になっている危険外来生物のヒアリ (火蟻、fire ant) ですが、国内外において陸海空で莫大な量の貨物が毎日運搬されているため、日本国内のあらゆる場所でヒアリに遭遇する可能性があります。もしアリと遭遇した場合、みなさんはヒアリと普通のアリを見分けられますか? 環境省から以下の図のようなヒアリの特徴が公開されています。全体が赤茶色で「腰」の部分に二つのこぶがあり、腹部は黒っぽい色、となっていますが、アカカミアリなど類似のアリとの判別など、いろいろな写真をよくよく見ておかないと専門家でも判別が難しいケースが存在します。
そのため、ヒアリの専門家事態も全国の各自治体で数がそんなに多くないにもかかわらず、今後、保健所などに問い合わせが殺到する可能性があります。そうすると、深刻なヒアリ専門家不足に陥ることが予想されます。これを人工知能 (AI) の力で解決してしまおう、つまりヒアリの写真を撮って、その画像からヒアリかそうでないかを判定する「ヒアリチェッカー」を作ってしまおうという実験を、日本マイクロソフトにて行いました。
尚、実際に AI のプロジェクトを回そうとする場合、どのような技術を使ってどういう実装を行うかについて、いくつかのレベルの選択肢が存在します。また、AI のテクノロジーを利用するにあたっては、前提として学習用データが十分存在している必要があります。これらの課題や選択肢への取り組み方次第でプロジェクトが前に進まない、とん挫するといったことが多くあります。以下の解説の中では、プロジェクトをなるべく早く前に進めるためのポイントになるところも盛り込みながら解説していきます。
レベル1. 出来合いの SaaS アプリで学習させてヒアリ判定
ヒアリかどうかの判定は画像認識の分野で、AI が得意とする分野です。ヒアリ、ヒアリではない、それぞれの写真をたくさん集めて AI に学習させる必要があります。いくつかのサンプルで結果を出すには各 20~30 程度の画像データがあればよいですが、本番で使える精度を出すには、画像はそれぞれ数百から数千程度必要になってきます。(手法によってはヒアリである画像のみの準備でよい場合もあります) 画像は必ずしもアリの全身を同じ方向から撮影したものではなく、現実に即した撮影角度、大きさ、背景の有無、単体/複数/集団、などさまざまなパターンの画像が含まれていることが望ましいです。このように、AI プロジェクトを始めるにあたっては、まず様々なパターンの学習データを数千の規模で用意しておくことが求められます。

レベル 1 として、Microsoft Cognitive Services の Custom Vision API を試すことができる SaaS アプリである customvision.ai (Customer Vision Service) を使って、ヒアリである、ヒアリでない画像データをそれぞれ学習させます。結果は以下の画像のように、ヒアリである確率、ヒアリでない確率がそれぞれ表示されます。

レベル2. 学習済みの出来合いの API でヒアリ判定
学習をさせた Custom Vision API は、外部のアプリケーションから呼ぶことができます。レベル 2 としては、ユーザーインターフェイスなどを作りこんだ外部アプリから API を呼び出すことで、フロントエンドの画面を作りこむことができます。たとえば Twitter/LINE と連携して、Bot に画像を送信すると結果を返してくるようなアプリを作成することもできます。
レベル3. 深層学習で API をスクラッチから作成
出来合いの API に学習をさせるよりも高い精度を出したい、もしくは 3 種類以上のアリを判別してくれる API を作りたいなど、出来合いの API でこたえきれないリクエストがある場合は、API をゼロから構築することになります。AI/機械学習の分野では様々なアルゴリズムが存在しますが、最近はやっている画像認識の精度が高い方法は、ニューラルネットワークを使った深層学習モデルです。必要な画像認識の条件に合うモデルを選択し、学習を進めることになります。この方法はパソコンでいえば「CPU自身を作る」ようなもので、深い知識と計算パワー (そして費用と時間) が要求されます。マザーボードに既成部品を組み合わせて作ることができないか、この方法をとる前によくよく検討する必要があります。
デモの様子をビデオでもご覧ください。(1:52:43 付近より)
[embed]https://www.youtube.com/watch?v=6JrvskMaIiI&t=6763s[/embed]
まとめ: AI プロジェクトを問題なく前に進めるために
以上のことから、画像認識に代表される AI プロジェクトをスムーズに進めるためのポイントを箇条書きにしてみましたので、参考になさってください。
- 学習データをあらかじめ大量に用意しておく。現実に即したさまざまなパターンのデータを数千保持していることが望ましい。
- 既製品を組み合わせるのか、ゼロからモデルを作るのかを判断する必要がある。そのためには、学習データを使った実証実験を早めに行い、どの方法が最適なのか目利きを行う必要がある。
- 費用対効果を何と比べるのかをあらかじめ考えておく。効率の向上なのか、人件費削減なのか、機会損失の挽回なのか。