マイクロソフトの AI が「ミズ・パックマン」を完全攻略
[2017 年 6 月 14 日]
マイクロソフトの研究者が作った AI が、1980 年台のビデオゲームである Atari 2600バージョンの「ミズ・パックマン」で、過去に出たことがないパーフェクトスコアの 999,990 点を叩き出しました。(人間のハイスコアは 266,330 点といわれています)
これは、今年初めにマイクロソフトが買収したカナダの深層学習スタートアップ Maluuba が、AI の一種である強化学習 (Reinforced Learning) と呼ばれる手法 ("ハイブリッド報酬アーキテクチャ (Hybrid Reward Architecture, HRA) " と名付けた) を使い、分割統治法アルゴリズムを使って成し遂げたものです。分割統治法アルゴリズムは、 AI エージェントに人間の能力を真似た複雑なタスクの遂行を教えるにあたり広範囲にわたる影響を及ぼすといわれています。
AI が完全攻略した時の動画はこちら。
[embed]https://youtu.be/zQyWMHFjewU[/embed]
完全攻略のアルゴリズム「Hybrid Reward Architecture for Reinforced Learning」とは
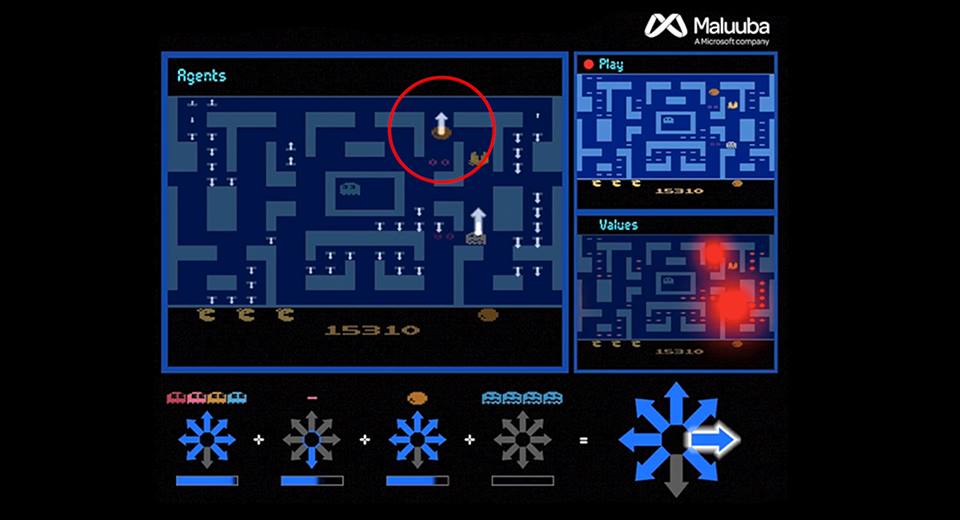
完全攻略の手法として使ったのは、 160 のエージェントを並行して動かし、それぞれにミズ・パックマンを研究させるものです。例えば、あるエージェントは特定のひとつのペレットを見つけたことに対し報酬を与え、次のエージェントにはフルーツを効率よく食べる手法に集中させ、ほかのエージェントはゴーストから逃げることに集中させます。そして、研究者は "エージェントの管理職"、会社でいうと部長にあたる人を作り出し、すべてのエージェントから意見を聞いてミズ・パックマンをどこに動かせばいいのかを決定します。
"エージェントの管理職" は、何人のエージェントがどういう意図で特定の方向に進めと言っているかを見ながら意思決定を行います。たとえば 100 人のエージェントがペレットを効率よく食べるには右に行ったほうが良い、と言っていて、3 人が右にはゴーストがいるから左に行きたいという場合には、ゴーストからの回避を優先して左に行く決定を下します。この手法が一番効果を発揮するのは、各エージェントがそれぞれとても自己中心的に動いた場合だといいます。それぞれのエージェントはひとつのタスクを極めることに集中し、管理職が彼らからの情報を元にどう動くのがベストなのかを判断する、という場合です。これはひょっとすると人間の組織の動き方にも当てはまるかもしれません。興味深いですね。このアルゴリズムは論文「Hybrid Reward Architecture for Reinforced Learning」として公開されています。
なぜ「ミズ・パックマン」を使ったのか
チェスや将棋、囲碁など AI が人間を超えるという話題には、ゲームを題材にしたものが多いのですが、なぜ 1980 年代の古いビデオゲームを使ったのかは不思議に思うかもしれません。しかし、この手のゲーム攻略は実は非常に複雑です。ゲームの中では状況のパターンがとても多く、人間ならではの考え方を必要とするシーンが多いのです。
「ミズ・パックマン」は、ゴーストを避けながらペレットやフルーツを食べていくゲームです。特別なパワーペレットを食べると、少しの間だけゴーストがブルーになり、ゴーストを食べてより点数を稼ぐことができます。また、ボーナスフルーツを食べると点数が稼げます。マップの種類は 4 通り、フルーツは 7 種類あります。
また、「ミズ・パックマン」は通常のパックマンと比べて予測性が低くランダムな作りになっており、より攻略が難しくなっています。通常のパックマンは特定の場所からスタートして、スタート直後は敵が動かない静かな時間がありますが、「ミズ・パックマン」はランダムな場所からスタートします。
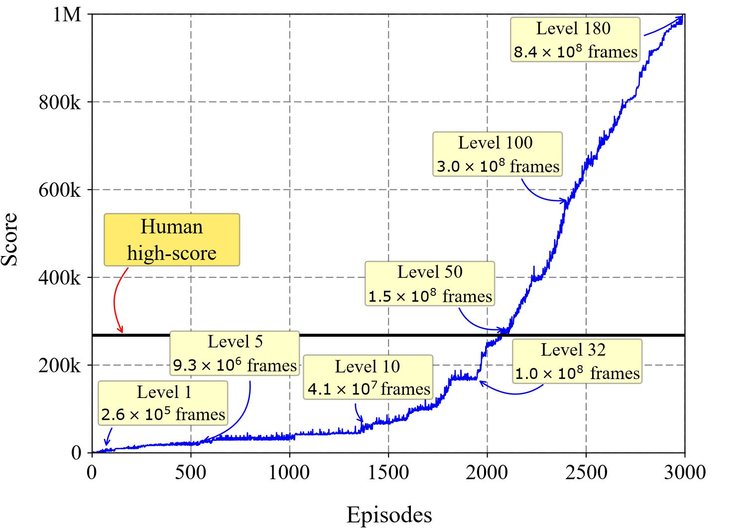
今回の題材は、無限のリソースがあるのであれば通常の強化学習アルゴリズムでも解けなくはないのですが、学習効率が課題でした。ミズ・パックマンで考え得る行動パターンは 10 の 77 乗通りですが、従来のアルゴリズムでは 4,000 時間のゲームプレイ時間に相当するリソースが必要でした。
今回の HRA を使ったチャレンジでは、2,000 回 (エピソード) のプレイを超えたところで人間のハイスコアを超え、その後は学習速度を速めて約 3,000 回のプレイでパーフェクトスコアを叩き出しました。
今回使われた「強化学習」という手法
「ミズ・パックマン」のゲーム要素にあるような予測不能性は強化学習を進化させようとしている研究者にとって特に価値があります。AI の研究の中で強化学習は「教師あり学習 (Supervised Learning)」と呼ばれる手法と対極にあります。教師あり学習は、良い振る舞いの例をたくさん与えられる題材でよりパフォーマンスが良いシステムを作ることがで、より一般的に使われる AI の手法です。
強化学習では各エージェントは試行の結果から正解、不正解の反応を得て、トライ & エラーをしながら正解の反応を最大化するよう学習します。
AI 研究者は、強化学習を使えば、エージェントがいまよりもさらに自己決定や複雑な仕事をこなせるようになり、人類はより高付加価値の仕事に専念できるようになると信じています。
「ミズ・パックマン」で使われたアルゴリズムは、たとえば企業でも営業組織の売り上げ予測をより正確に行い、どう動けばいいのかを知るために使うことができます。各エージェントをそれぞれの顧客に割り当て、契約更新をするのがいいのか、新規でどこにアプローチするのがいいのか、といった具合です。それにより、人間は予測の資料作りに時間を取られず、より営業活動に専念できるようになるわけです。
また、この手法は自然言語処理などほかのAI領域でも有望なアルゴリズムであると期待されています。
この文章は以下の原文を要約したものです:
- 2017/6/14: Divide and conquer: How Microsoft researchers used AI to master Ms. Pac-Man (The AI Blog)
- 2017/6/14: Hybrid Reward Architecture (HRA) Achieving super-human performance on Ms. Pac-Man (Maluuba blog)