機械翻訳の概要

(この記事は Machine Translation の翻訳です。)
この記事では機械翻訳を支えるコア技術と、この領域でのマイクロソフトのソリューションの両方について説明します。
機械翻訳とは
機械翻訳システムは、アプリケーションや機械学習技術を使用して、大量のテキストから、サポートされている言語のいずれかに変換するオンラインサービスです。サービスは、ある言語の「ソース」のテキストを別の「ターゲット」言語に変換します。
2010年代初頭以来、新しい人工知能技術、ディープニューラルネットワーク (または深層学習) は、Microsoft Translator チームコアテキスト翻訳技術を使用し、新しい音声翻訳技術を起動して音声認識を結合する品質レベルに到達する音声認識の技術を可能にしています。
高い品質レベルに到達する音声認識の技術を提供できます。機械翻訳技術とそれを使用するインターフェイスの背後にある概念は比較的単純な科学とその背後にある非常に複雑な技術で成り立っています。深い学習(人工知能)、大きなデータ、言語学、クラウド・コンピューティング、webApiといった最先端技術を駆使しています。
歴史的に、機械業界で使用される技術を学習は、統計的機械翻訳(SMT)でした。SMTでは、高度な統計解析を使用していくつかの単語のコンテキストを与えられた単語の最高の可能な翻訳を推定します。SMTは、マイクロソフトを含むすべての主要な翻訳サービスプロバイダーによって2000年代半ば以来使用されています。
ディープ ニューラルネットワークに基づく翻訳の出現は、翻訳技術の急激な進化を引き起こし、翻訳品質が劇的に改善しました。この翻訳テクノロジユーザーと 2016年の後半部分で開発者を配置し始めた 両方のテクノロジーには2つの共通の要素があります。
- 大量(翻訳文の何百万)の人間によって行われた翻訳済みコンテンツがシステムを訓練するために事前に必要です。
- 二か国語辞書のように、潜在的な翻訳の一覧に基づいた単語の翻訳がされるわけではなく、文脈と翻訳文全体で使用されている単語に基づいて翻訳が進みます。
Microsoft Translatorとは
![]()
Microsoft TranslatorテキストおよびスピーチApiは、Apiの認知サービスコレクションの一部は、は、マイクロソフトからの機械翻訳サービスです。
Microsoft Translator テキスト API
APIは、Microsoftで使用されているMicrosoft Translator本文は2006年以来のグループ、2011年以来お客様のAPIとして利用できます。Microsoft TranslatorテキストAPIは、Microsoft社内で使用されています。製品のローカライズ、サポート、およびオンライン通信チーム(例えば、 Windowsのブログ) に組み込まれています。この同じサービスは、また、 Bing、 Cortana、Internet Explorer、 Lync、 Microsoft Edge、 Office、 SharePoint、 Skype、 Yammerなどよく知られたマイクロソフト製品で追加費用なしでアクセスできます。
Microsoft Translatorは、任意のハードウェアプラットフォーム上や任意のオペレーティングシステム上のウェブまたはクライアントアプリケーションで、言語翻訳を行ったり、言語検出やテキスト音声変換や辞書などその他の言語関連の操作を実行できます。
業界標準の残りの部分の技術を活用し、開発者送信ソーステキストサービスにターゲット言語を示すパラメーターを使用し、サービスを使用するクライアントまたはwebアプリの翻訳済みテキスト。
Microsoft Translator サービスは無限の可能性をもつマイクロソフトのデータセンター、セキュリティ、スケーラビリティ、信頼性、および他のMicrosoftクラウドサービスを駆使することにより可能となっています。
Microsoft Translatorの使い方を説明します。ページの一番上にある「このページを翻訳」というボタンを押してください。翻訳可能な 60の言語が表示されます。その言語を選択するとページが自動的に翻訳されます。
Microsoft Translator 音声 API
Microsoft Translator音声翻訳技術は 2014 年にSkype翻訳を開始後、2016 年前期以来お客様のオープンなAPIとして利用できるようになりました。翻訳統合が可能なのはAndroid、iOSとWindows用Skype、Skypeの会議のブロードキャスト、およびMicrosoft Translatorアプリです。
テキスト翻訳の仕組みとは
テキストの翻訳に使用される技術には主に2つあります。1つは従来の統計的機械翻訳(SMT)でもう一つの新しい技術はニューラルネットワーク(NN)翻訳です。
統計的機械翻訳
Microsoft Translator実装統計的機械翻訳(SMT)は10年以上もマイクロソフトの自然言語研究に組み込まれています。手作りのルールベースの言語間の翻訳を書くのではなく、翻訳システムは翻訳に対し、既存の人間の翻訳から言語間のテキストの変換を学習の問題としてとらえ、応用統計学や機械学習の最近の進歩を活用しています。
いわゆる「コーパス」は、文脈上で、単語、フレーズ、および慣用的な翻訳を多くの言語ペアとドメインの面において提供し、大量の規模で現代のロゼッタ石として機能しています。統計的モデリング技術と効率的なアルゴリズムで解読(トレーニングデータでのソース言語とターゲット言語の対応関係の検出)の問題や復号化(新しい入力文の最高の翻訳を見つけること)の問題を見極めています。Microsoft Translatorは、統計手法と言語情報を組み合わせ、より一般化した、より理解しやすい翻訳につながるモデルを作り出そうとしています。
このアプローチにより、辞書や文法規則に依存しない、1つの単語の翻訳を実行することによって特定の単語の前後使用できるフレーズに最高の翻訳を提供します。1つの単語の翻訳には対訳辞書を開発し、これはwww.bing.com/translatorを介してアクセス可能です
ニューラルネットワーク翻訳
翻訳の質を更に向上させるためにこの技術が用いられるようになりました。ただし、パフォーマンスの向上は、2010年代半ば以来SMT技術で頭打ちしています。スケールとマイクロソフトのAIのスーパーコンピューターのパワーを活かし、特にマイクロソフト認知ツールキット、Microsoft Translator今をニューラルネットワーク(LSTM)による翻訳により、翻訳品質向上の新たな10年を提供しています。
これらのニューラルネットワークモデルの試みでMicrosoft TranslatorSpeechAPIを介してすべての音声言語が翻訳可能です。'generalnn'カテゴリーIDを使ってテキストAPを介してサイト https://translator.microsoft.comを比較してください。
ニューラルネットワーク翻訳は根本的に彼らの伝統的なSMTのものに比べて実行方法が異なります。
次のアニメーションでは、ニューラルネットワーク翻訳で文章を翻訳する通過様々な手順を示しています。このアプローチにより数単語をスライディングさせるSMT技術を使用するのではなく、文脈や文全体を考慮させ 人間の脳の中で行われる翻訳と似たメカニズムを利用してより流暢な翻訳になります。
ニューラルネットワークのトレーニングをもとに、各単語は500-寸法(、)を表すベクトル(英語、中国語など)は、特定の言語ペア内でユニークな特性に沿ってコーディングされています。トレーニングに使用言語の組み合わせに基づいて、ニューラルネットワーク自己これらの寸法がどうあるべきかを定義します。そして性別(男性、女性、中性)、敬語、礼儀のレベル(俗語、カジュアル、書面、正式な等)、単語(動詞、名詞等)の種類がトレーニングデータ、派生としてもその他の非明白な特性のような単純な概念をエンコードしています。
- 各単語は、500次元ベクトルで エンコードされています。そして最初の層のニューロンを通過するとその単語は1000次元ベクトル(b)に入ります。
- 各単語はこれら1000次元ベクトルのエンコードを数回繰り返し、文脈や他の単語との関係を考慮しながら調整されます。(比較としてSMT技術では3から5単語のウィンドウのみ考慮されます。)
- 最終的な出力のマトリックスは、単語をどのように変換するかを定義するのに使われます。この最終的な出力行列と以前に翻訳された単語の出力の両方を使用する注意層(すなわちソフトウェアアルゴリズム)が使用されます。それはまた目標言語で不要な言葉を削除するのにこれらの計算を使用します。
- デコーダー(翻訳)レイヤーは、ターゲット言語の最も適切な等価で選択した単語を変換します。この最後の層(c)の出力、ソース文から、次の単語を変換するか計算する注目層にフィードバックします。

アニメーションで描かれている例では、「コンテキスト・アウェアの1000次元モデルは名詞(家)はフランス語(ラメゾン)でフェミニンな単語をエンコードします。これは"the"デコーダー(翻訳)層に達すれば「la」とない「le」(単数形、男性)または「レ」(複数)するための適切な翻訳をできるようになります。
注目のアルゴリズムも、以前(この場合"the")に翻訳された単語に基づいて計算されます。次の単語を翻訳することは、件名(「家」)およびない形容詞(「青」)にはする必要があります。することができますこれを達成するシステムを学んだ英語とフランス語が文中にこれらの単語の順序を反転します。その形容詞が「大きな」色の代わりにするなら、それ反転するはずないそれらこれも計算があるだろう(「大きな家」=>「ラ・グランド・メゾン」).
この方法のおかげでは、最終的な出力は、ほとんどの場合、より流暢かつSMTベースの翻訳がこれまで行った翻訳よりも人間の認知に従った適切な翻訳になりました。
音声翻訳の仕組みとは
Microsoft Translatorは音声の翻訳も可能です。最初はSkypeTranslator機能とMicrosoft TranslatorアプリiOSとAndroid上で利用可能でしたが、この機能は最新バージョンのAPIで開発者が利用できます。
一見簡単なプロセスのように見えるかもしれませんが、単に既存のテキストの翻訳に既存の「伝統的な」人間から機械への音声認識エンジンを差し込むというよりも、もっと多くの努力が必要でした。
「ソース」音声を1つの言語から別の「ターゲット」の言語を正しく変換するには、システムは、4段階のプロセスを通過します。
- 音声認識: 音声をテキストに変換する
- TrueText:Microsoftのテクノロジーを使い、テキストを正規化し、翻訳を適切なものにする
- 上記のテキスト翻訳エンジンで翻訳し、実際の会話用には特別に開発された翻訳のモデルを使い翻訳する
- 必要があれば、音声合成で翻訳を音声で生成する

自動音声認識 (ASR)
自動音声認識(ASR)は、着信オーディオ音声の数千時間を分析の訓練を受けてDNNシステムを使用して実行されます。このモデルは、通常会話に最適化された音声認識を目指し、人間から機械へのコマンドより、むしろ人間と人間の相互作用において学習されています。これを達成するために、伝統的な人間から機械へのASRよりもっと大きいDNNと同様に、いっそう多くのデータが必要です。
TrueText
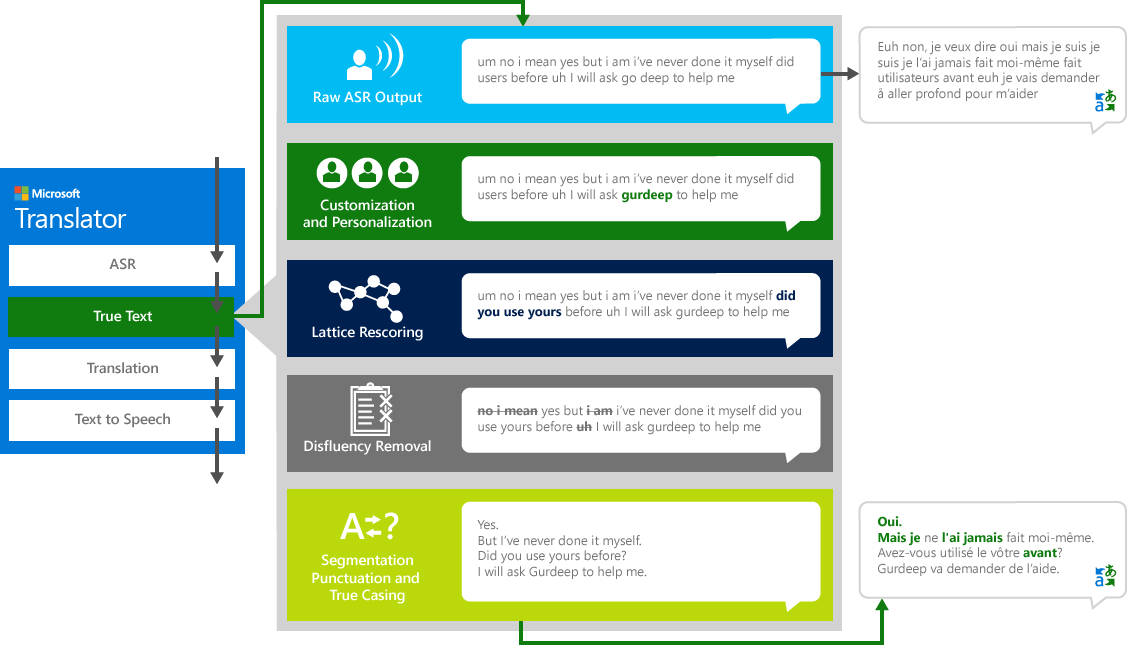
人間は他人と会話しているとき、思っているより完璧にはっきりと適切に話しているわけではありません。TrueTextテクノロジーにより、「うーん」や「ああ」や「それから」や「えーと」などの会話の間投詞(フィラー)、吃音や繰り返しを削除することによって、本来のテキストがより密接にユーザーの意図を反映するように変換します。テキストは、文の区切れ、適切な句読点と大文字と小文字を追加することで、より読みやすく、翻訳しやすくなります。これらの結果を達成するために、Translatorを基に言語技術の開発に数十年を費やし、TrueTextを作ります。次の図は、実際の例を通して、この本来のテキストをTrueTextがどのように変更されていくかを示しています。
翻訳
テキストは、Microsoft Translatorがサポートする 60を超える言語のいずれかに変換されます。
(開発者)として音声翻訳APIを使用しての翻訳または音声翻訳アプリ、サービスで、すべての音声入力のサポートされている言語の最新のニューラルネットワークベース翻訳で電源が切れて(を参照してくださいここで完全なリストのため)。これらのモデルは、翻訳の音声会話型のより良いモデルを構築するより多くの話されているテキストコーパスで、現在、主に書かれたテキストの訓練を受けた翻訳モデルを展開することによってまた造られました。これらのモデルは、伝統的なテキストの翻訳APIの「音声標準カテゴリでもご利用頂けます。
特に明記しない限り、その他の非音声言語のいずれか、伝統的なSMT変換が実行されますここで.
テキストを音声に変換
ターゲット言語は、サポートされている18の音声言語のうちのひとつで、使用事例に音声出力が必要である場合、テキストは音声合成で音声出力に変換されます。この段階は音声からテキストへの翻訳では省かれます。