マイクロソフトの音声認識技術、人間と同等の認識率を達成
[2016 年 10 月 18 日]

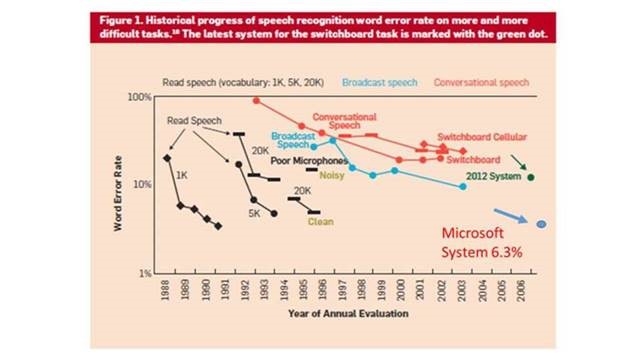
Microsoft Artificial Intelligence and Research の研究チームは、文字起こしの専門家よりも誤認識率が低い音声認識システムを開発したと発表しました。業界標準のベンチマークテスト Switchboard 会話認識タスクにおける WER(Word Error Rate:単語誤認識率)は5.9% で、先月同チームにより報告されたばかりの6.3%よりもさらに向上しています。5.9%という誤認識率は、同じ会話の文字起こしを行なった人間と同等であり最高記録です。研究チームが1年前に設定した目標を上回り、同時にあらゆる人の予測をも越えました。
9 月に行われたカンファレンスで、IBM は 6.6% の誤認識率を達成したと発表したばかりでした。20 年前には最善の結果は 43% より悪い誤認識率でした。この研究のマイルストーンは、1970年代に国防目的での革新的テクノロジ開発を行なう政府機関である DARPA (国防高等研究計画局)において始まった過去数十年にわたる音声認識の研究の結果であり、誤認識率は指数関数的に改善してきています。
今回の研究成果は、Xbox、Skype、コルタナなどの音声認識技術に組み込まれていくことになるでしょう。
研究成果を得るのに不可欠だったもの
深層学習技術の発達
この研究分野では、脳の生物学的処理を模倣して最近急激に進化しているディープニューラルネットワークを活用しています。このテクノロジーの発達が音声認識システムの発達には不可欠でした。それまではコンピューター科学者たちは別の方法で画像や音声を学習させようとしていましたが、何十年もの間、不正確な成果しか出せていませんでした。
ディープニューラルネットワークは多層 (狭義には 4 層以上) のニューラルネットワークとして構築されています。この手法は 2010 年代から急速に研究が進み、物体や音声の認識などに利用されるようになりました。マイクロソフトでも研究者が、スタンフォード大学の研究者によって開発された世界最大級の画像データベース " ImageNet" の大規模画像認識競技会 (ILSVRC) に対して、新しいモデルで競争に勝利するなど、モデルの精度を磨いてきました。
CNTK の採用
ディープニューラルネットワークは、コンピューターシステムに画像や音声などの入力からパターンを認識させるために、トレーニングセットと呼ばれる大量のデータを使用します。チームはマイクロソフトのディープラーニング用自社開発システムである Computational Network Toolkit (CNTK) を活用しました。GPU (Graphics Processing Unit) という専用チップを搭載した複数のコンピューター上でディープラーニングのモデルを高速に処理できるCNTKにより研究のスピードを大幅に加速し、最終的に目標を達成することができました。
GPU はコンピューターグラフィック処理を行うために設計されていますが、研究者は最近、音声認識などの複雑なモデルの処理に向いていることに気づきました。GPU の活用により、計算速度が 10 倍以上に向上します。
音声の認識から内容の理解へ
より長期的には、研究者は、人々が発する音声を文字化するだけではなく、実際に話していることを理解する方向でも研究を進めていきます。これにより、コンピューターが質問に回答したり、言われたことに従って行動したりすることが可能になります。コンピューターが聴いたことや見た物の真の意味を理解できるようになるまでには相当な期間を要し、やるべきことも数多くあります。
この文章は以下の原文を要約したものです:
- 2016/9/13: Microsoft researchers achieve speech recognition milestone (The AI Blog)
- 2016/10/18: Historic Achievement: Microsoft researchers reach human parity in conversational speech recognition (The AI Blog)
- 2016/10/24: 歴史的成果: マイクロソフトの研究者が対話型音声認識において人間と同等の成績を達成 (The Official Microsoft Japan Blog)