OPTIMIZE FOR e calcolo delle statistiche
In questo articolo, esploreremo l’utilizzo dell’hint OPTIMIZE FOR e analizzeremo come questo impatta sulla lettura delle statistiche da parte dell’optimizer.
Quando una stored procedure viene eseguita la prima volta, i parametri con cui viene richiamata vengono salvati nella cache insieme al piano di esecuzione e utilizzati per il calcolo della cardinalità.
Questo comportamento è denominato “parameter sniffing”.
Nel caso in cui la distribuzione dei valori all’interno di una statistica sia poco uniforme, una stima errata della cardinalità, dovuta al parameter sniffing, può impattare negativamente sulle prestazioni in fase di esecuzione.
Facciamo un esempio:
USE tempdbGO SET NOCOUNT ON CREATE TABLE t1 (IdRow int identity(1,1) PRIMARY KEY, Valore char(3)) DECLARE @i int -- Inserisco 1000 righe con il valore AAASET @i = 0WHILE @i < 1000BEGIN INSERT INTO t1 (Valore) VALUES ('AAA') SET @i = @i + 1END -- Inserisco 500 righe con il valore BBBSET @i = 0WHILE @i < 500BEGIN INSERT INTO t1 (Valore) VALUES ('BBB') SET @i = @i + 1END -- Inserisco 1 riga con il valore CCCINSERT INTO t1 (Valore) VALUES ('CCC') CREATE INDEX IX1 ON t1 (Valore)GO -- Analizziamo le statisticheDBCC SHOW_STATISTICS (t1, IX1)GO |

Analizzando i piani di esecuzione possiamo constatare come le righe stimate vengano calcolate sulla base della cardinalità del parametro lanciato per primo dopo la compilazione (o ricompilazione) della stored procedure.

La figura evidenzia, ad esempio, la discrepanza tra righe stimate e quelle reali nel caso in cui la stored procedure venga richiamata con il parametro “AAA” essendo stata richiamata la prima volta con il parametro “CCC”.
Se guardiamo il piano di esecuzione in formato XML troveremo il dettaglio del parametro salvato:
<ParameterList> <ColumnReference Column="@Valore" ParameterCompiledValue="'CCC'"ParameterRuntimeValue="'CCC'" /> </ParameterList> |
In casi come quello appena descritto, possiamo utilizzare l’hint “OPTIMIZE FOR” per controllare la modalità con cui i parametri vengono salvati nel piano di esecuzione, in modo da migliorare la stima della cardinalità.
Ci sono due modi per utilizzare “OPTIMIZE FOR”:
- OPTIMIZE FOR Parametro: a prescindere dal parametro con cui la stored procedure viene chiamata per prima, il piano di esecuzione verrà ottimizzato e salvato nella cache con il valore specificato e, di conseguenza, le statistiche verranno sempre calcolate in base alla cardinalità di quel parametro
- OPTIMIZE FOR UNKNOWN: non verrà salvato alcun parametro nel piano di esecuzione in cache e le statistiche verranno calcolate in base alla densità
Esempio caso 1:
ALTER PROCEDURE p1 @Valore char(3)AS
SELECT IdRow, ValoreFROM t1WHERE Valore = @ValoreOPTION(OPTIMIZE FOR (@Valore = 'AAA')) GO -- Eseguiamola passandogli prima 'CCC' e poi 'BBB'EXEC p1 'CCC' --> 1 riga, stimate 1000EXEC p1 'BBB' --> 500 righe, stimate 1000 |

Come si vede, in entrambi i casi l’optimizer stima 1000 righe che è appunto la cardinalità del valore “AAA”
Esempio caso 2:
ALTER PROCEDURE p1 @Valore char(3)AS
SELECT IdRow, ValoreFROM t1WHERE Valore = @ValoreOPTION(OPTIMIZE FOR UNKNOWN) GO -- Eseguiamola passandogli i vari valoriEXEC p1 'CCC' --> 1 riga, stimate 500,333EXEC p1 'BBB' --> 500 righe, stimate 500,333EXEC p1 'AAA' --> 1000 righe, stimate 500,333 |

Come si vede, l’optimizer stima le righe in base alla densità, ovvero:
righe stimate = densità x numero righe totali = 0,3333333 x 1501 = 500,333 |
Ora vi faccio notare qualcosa di interessante :-)
Proviamo ad aggiungere un po’ di valori NULL per il campo “Valore”:
DECLARE @i intSET @i = 0WHILE @i < 2000BEGIN INSERT INTO t1 (Valore) VALUES (NULL) SET @i = @i + 1END -- Analizziamo le statisticheUPDATE STATISTICS t1 WITH FULLSCAN;DBCC SHOW_STATISTICS (t1, IX1)GO |
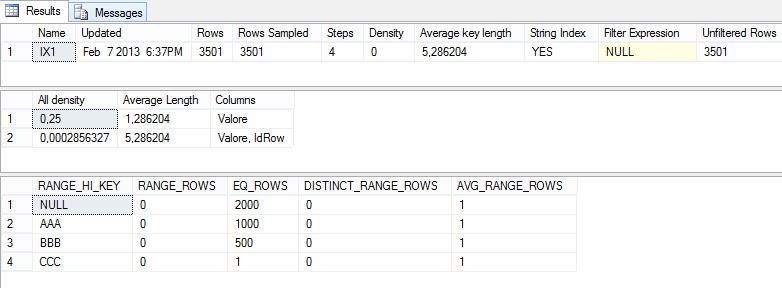
Dalle statistiche possiamo notare la presenza di 2000 valori NULL per il campo “Valore”. La densità è leggermente diminuita, passando da 0,333 a 0,25.
Ricompiliamo la stored e lanciamola con il parametro CCC:
EXEC sp_recompile p1 EXEC p1 'CCC' |
Secondo i calcoli fatti in precedenza ci aspetteremmo la seguente stima:
densità x numero righe totali = 0,25 x 3501 = 875,25 |
Se guardiamo però il piano di esecuzione notiamo che la stima non è cambiata:

Come mai ha ignorato i valori NULL?
La risposta è insita nel predicato della query:
WHERE Valore = @Valore |
Nel caso in cui @Valore sia NULL, la query non restituirà alcuna riga nonostante vi siano 2000 righe a NULL, perché il risultato del confronto "Valore = @Valore" è valutato come UNKNOWN.
È interessante il fatto che l’optimizer, conscio di questo fatto, non consideri la cardinalità dei valori NULL, migliorando la stima.
Il calcolo effettuato è
[densità dei valori NOT NULL] x [numero righe totali NOT NULL] |
dove densità dei valori NOT NULL si ottiene facendo l’inverso della somma di tutti i valori della colonna DISTINCT_RANGE_ROWS con l’aggiunta del numero di step – 1 (escludo la riga dei NULL).
Nel nostro caso il calcolo è [1/(0+0+0+0+4-1)] x 1501
Alla prossima!