SQL 2012 - discontinuità nella generazione dei valori associati alla proprietà IDENTITY
Recentemente mi è capitato di lavorare presso due differenti clienti che avevano un problema simile. Tale problema consisteva nel fatto che in alcune situazioni, i valori generati tramite l’attributo IDENTITY presentavano delle discontinuità. Questo fenomeno è dovuto ad una differente modalità di generazione dei valori da SQL Server 2012 in poi.
Nelle versioni precedenti, ad ogni nuovo valore di IDENTITY corrispondeva una scrittura sul transaction log. Dalla versione 2012 il valori IDENTITY vengono generati attraverso un batch, per cui, sul transaction log viene scritto soltanto il valore massimo dell’intervallo generato, il resto dei valori sono contenuti in una in-memory cache. Questa differente gestione permette di ridurre il numero e la frequenza di scritture sul transaction log, migliorando la scalabilità delle operazioni di inserimento.
I gap si possono generare in una delle seguenti situazioni:
- Il servizio SQL Server viene “stoppato” con il comando: NET STOP
- Il servizio SQL Server viene “stoppato” tramite SSMS
- Il servizio SQL Server è clustered e si verifica un failover automatico o manuale
- In tutte le condizioni in cui il servizio SQL Server viene “stoppato” senza che prima venga effettuata un operazione di CHECKPOINT
Tale comportamento è documentato nei books online:
http://msdn.microsoft.com/library/ms186775(v=sql.110).aspx
“The identity property on a column does not guarantee the following:
- Uniqueness of the value – Uniqueness must be enforced by using a PRIMARY KEY or UNIQUE constraint or UNIQUE index.
- Consecutive values within a transaction – A transaction inserting multiple rows is not guaranteed to get consecutive values for the rows because other concurrent inserts might occur on the table. If values must be consecutive then the transaction should use an exclusive lock on the table or use the SERIALIZABLE isolation level.
- Consecutive values after server restart or other failures –SQL Server might cache identity values for performance reasons and some of the assigned values can be lost during a database failure or server restart. This can result in gaps in the identity value upon insert. If gaps are not acceptable then the application should use a sequence generator with the NOCACHE option or use their own mechanism to generate key values.
- Reuse of values – For a given identity property with specific seed/increment, the identity values are not reused by the engine. If a particular insert statement fails or if the insert statement is rolled back then the consumed identity values are lost and will not be generated again. This can result in gaps when the subsequent identity values are generated.
These restrictions are part of the design in order to improve performance, and because they are acceptable in many common situations. If you cannot use identity values because of these restrictions, create a separate table holding a current value and manage access to the table and number assignment with your application.”
Il seguente script riproduce la problematica:
CREATE TABLE [TestTable] ([C1] INT IDENTITY, [C2] CHAR (100));
GO
INSERT INTO [TestTable] VALUES ('Transaction 1');
INSERT INTO [TestTable] VALUES ('Transaction 2');
aprire un command prompt con privilegi elevati (run as administrator)
net stop MSSQLSERVER
net start MSSQLSERVER
INSERT INTO [TestTable] VALUES ('Transaction 3');
INSERT INTO [TestTable] VALUES ('Transaction 4');
SELECT * FROM [TestTable]
Il risultato che si ottiene è il seguente:
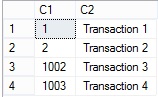
Generalmente la discontinuità nei valori dei campi IDENTITY non crea problemi applicativi, a patto che tali campi vengano utilizzati come chiavi surrogate, cioè i valori non devono avere un significato di bussiness:
http://en.wikipedia.org/wiki/Surrogate_key
al contrario di quello che succede per le chiavi naturali:
http://en.wikipedia.org/wiki/Natural_key un tipico esempio di una chiave naturale in letteratura è il SSN simile al, molto più nostrano, Codice Fiscale.
Ad essere sinceri anche a me, sull’istanza del mio portatile, si sono verificati numerosi gap sugli IDENTITY, probabilmente in corrispondenza di alcuni shutdown non proprio da manuale, che ogni tanto mi capita di fare. Nella figura che segue un esempio:

Nel mio caso la discontinuità dei valori non mi ha creato nessun problema perché ho usato il campo IDENTITY come chiave surrogata, non mi ero accorto del gap se non dopo parecchio tempo, quando sono andato a modificare dei record direttamente sul DB, perché non ho avuto ancora il tempo di implementare la modifica di un determinato valore dalla mia applicazione.
Se al contrario si è scelto di dare un significato di bussiness, ai valori generati tramite attributo IDENTITY, e un eventuale gap crea un problema, si può utilizzare uno dei seguenti workaround.
Workaround 1 (retrocompatibilità)
Utilizzare il trace flag 272 tra gli startup parameters dell’istanza. Da notare che la stringa da aggiungere è –T272 (la “T” deve essere uppercase).
Questo trace flag forza il SQL Engine a generare gli IDENTITY emulando le versioni pre 2012, cioè verrà effettuata una scrittura sul transaction log per ogni valore.
L’attivazione di questo trace flag potrebbe creare un impatto sulle performances.
Il trace flag è deprecato e nelle prossime versioni potrebbe essere rimosso.
Per verificare questo workaround possiamo modificare lo script presentato prima come segue:
DBCC TRACEON(272, -1)
GO
CREATE TABLE [TestTable] ([C1] INT IDENTITY, [C2] CHAR (100));
GO
INSERT INTO [TestTable] VALUES ('Transaction 1');
INSERT INTO [TestTable] VALUES ('Transaction 2');
aprire un command prompt con privilegi elevati (run as administrator)
net stop MSSQLSERVER
net start MSSQLSERVER
INSERT INTO [TestTable] VALUES ('Transaction 3');
INSERT INTO [TestTable] VALUES ('Transaction 4');
SELECT * FROM [TestTable]
Il risultato che si ottiene è il seguente:
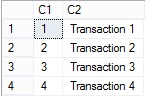
Workaround 2
Effettuare manualmente il commando CHECKPOINT prima di riavviare l’istanza o di effettuare un failover.
Tale soluzione è praticabile solo durante le operazioni programmate.
Per verificare questo workaround possiamo modificare lo script presentato prima come segue:
CREATE TABLE [TestTable] ([C1] INT IDENTITY, [C2] CHAR (100));
GO
INSERT INTO [TestTable] VALUES ('Transaction 1');
INSERT INTO [TestTable] VALUES ('Transaction 2');
CHECKPOINT
apriere un command prompt con privileggi elevati (run as administrator)
net stop MSSQLSERVER
net start MSSQLSERVER
INSERT INTO [TestTable] VALUES ('Transaction 3');
INSERT INTO [TestTable] VALUES ('Transaction 4');
SELECT * FROM [TestTable]
Il risultato che si ottiene è il seguente:
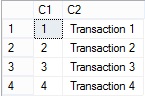
Workaround 3 (Sequence)
Sostituire l’uso dell’IDENTITY con una SEQUENCE con l’argomento NO CACHE, come descritto nei books online http://msdn.microsoft.com/en-us/library/ff878091.aspx:
CREATE SEQUENCE s1 AS INT
START WITH 1
NO CACHE;
l’uso del NO CACHE avrà l’effetto, come nel caso dell’IDENTITY nelle versioni antecedenti a 2012, di produrre una scrittura di un record sul transaction log per ogni valore generato. Questo chiaramente annulla l’incremento di performance guadagnato con la generazione “a batch” delle sequenze di valori.
A seguire due esempi di utilizzo della SEQUANECE che emulare l’IDENTITY:
CREATE TABLE t
(
Id INT PRIMARY KEY DEFAULT NEXT VALUE FOR s1,
val INT NOT NULL
);
INSERT INTO t (val) VALUES (2)
oppure:
CREATE TABLE t
(
Id INT PRIMARY KEY,
val INT NOT NULL
);
INSERT INTO t (id, val) VALUES (NEXT VALUE FOR s1, 2)
Per testare anche questo workaround possiamo modificare il solito script per utilizzare la SEQUENCE:
CREATE SEQUENCE s1 AS INT
START WITH 1
NO CACHE;
CREATE TABLE [TestTable] ([C1] INT, [C2] CHAR (100));
GO
INSERT INTO [TestTable] ([C1], [C2]) VALUES (NEXT VALUE FOR s1, 'Transaction 1')
INSERT INTO [TestTable] ([C1], [C2]) VALUES (NEXT VALUE FOR s1, 'Transaction 2')
apriere un command prompt con privileggi elevati (run as administrator)
net stop MSSQLSERVER
net start MSSQLSERVER
INSERT INTO [TestTable] ([C1], [C2]) VALUES (NEXT VALUE FOR s1, 'Transaction 3')
INSERT INTO [TestTable] ([C1], [C2]) VALUES (NEXT VALUE FOR s1, 'Transaction 4')
SELECT * FROM [TestTable]
Il risultato ottenuto è quello corretto:

Come controprova, se per caso, avessimo dimenticato il NO CACHE, avremmo ottenuto un gap (provate a eseguire nuovamente lo script commentando il NO CACHE):
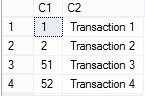
Nota: nel caso degli IDENTITY e della SEQUENCE otteniamo dei gap di valori differenti, ciò è dovuto alle diverse dimensioni del buffer che contengono i valori generati in modalità batch.
Conclusione
A causa della struttura degli indici di SQL Server:
http://technet.microsoft.com/en-us/library/ms177443(v=sql.105).aspx
http://technet.microsoft.com/en-us/library/ms177484(v=sql.105).aspx
le SEQUENCE o di campi con attributo IDENTITY, sono ottimi candidati per essere usati come primary key clustered questo perché permetteranno di avere:
- row locator sugli indici nonclustered compatti
- datatype performanti per le operazioni di join tra tabelle (la join tra tabelle con clausola di ON su campi int o è molto più performante della stessa operazione su campi ad esempio varchar(255)).
Si suggerisce quindi di progettare le basi dati in modo tale che i valori delle primary key, prodotti con SEQUENCE o tramite l’attributo IDENTITY, siano delle chiavi surrogate.
Se non fosse possibile cambiare la logica implementata all’interno del database si consiglia di utilizzare il workaround 3.
Se non fosse possibile nemmeno modificare il codice è possibile usare il workaround 1.
Marco Giordani