Streaming in SQL Server using SQL CLR
The SQL Server engine execution operators are of two kinds: blocking and non-blocking. Blocking operators need to consume the complete dataset before returning an output. Think about the COUNT(*) operator: in order to tell you the result it has to go over all your rows. Another example of blocking operator is the Sort operator. Proper sorting requires the dataset to be completely sorted.
Non-blocking operators, on the contrary, can produce output before having processed all the input rows. Think about at this query:
SELECT a,b, a+b FROM Table
SQL Server can tell the exact result of a+b of each row as soon as it has read the row itself. In this case SQL Server will not wait for the whole table to be read from disk and will stream the data to the output as soon as it’s ready.
As you might have guessed by now non-blocking operators are generally better: the less bottlenecks your execution plan has the better.
The SQL Server optimizer, of course, knows when it’s best to use – and where – these operators on its own. You should however be mindful of the implications of a blocking function in your code, especially when dealing with slow-to-retrieve datasets. As a real example suppose we want to access the OpenData Lombardia and perform some statistical calculations. The data is available as an URL: https://www.dati.lombardia.it/api/views/sd8x-w4h3/rows.csv?accessType=DOWNLOAD (rows are available in other formats such as JSON and XML but for the purpose of this article we will work with CSV).
In order to show a real example I’ve created a much bigger version of the recordset (exactly 1,305,487,617 bytes) replicating the original dataset.
Using the CLR we can access the remote recordset and return as SQL NVARCHAR rows. A first blocking approach can be:
[SqlFunction(
DataAccess = DataAccessKind.None,
SystemDataAccess = SystemDataAccessKind.None,
FillRowMethodName = "_StreamLine",
IsDeterministic = false,
IsPrecise = true,
TableDefinition = (@"Line NVARCHAR(MAX)"))]
public static System.Collections.IEnumerable BlockingFileLine(
SqlString fileName)
{
List<string> lStreams = new List<string>();
using (System.IO.FileStream fs = new System.IO.FileStream(
fileName.Value,
System.IO.FileMode.Open,
System.IO.FileAccess.Read,
System.IO.FileShare.Read))
{
using (System.IO.StreamReader sr = new System.IO.StreamReader(fs))
{
string str;
while ((str = sr.ReadLine()) != null)
lStreams.Add(str);
}
}
return lStreams;
}
This undoubtedly works as expected generating a line-by-line TVF. However if we look at the memory footprint (I suppose a recently started instance for the sake of simplicity):
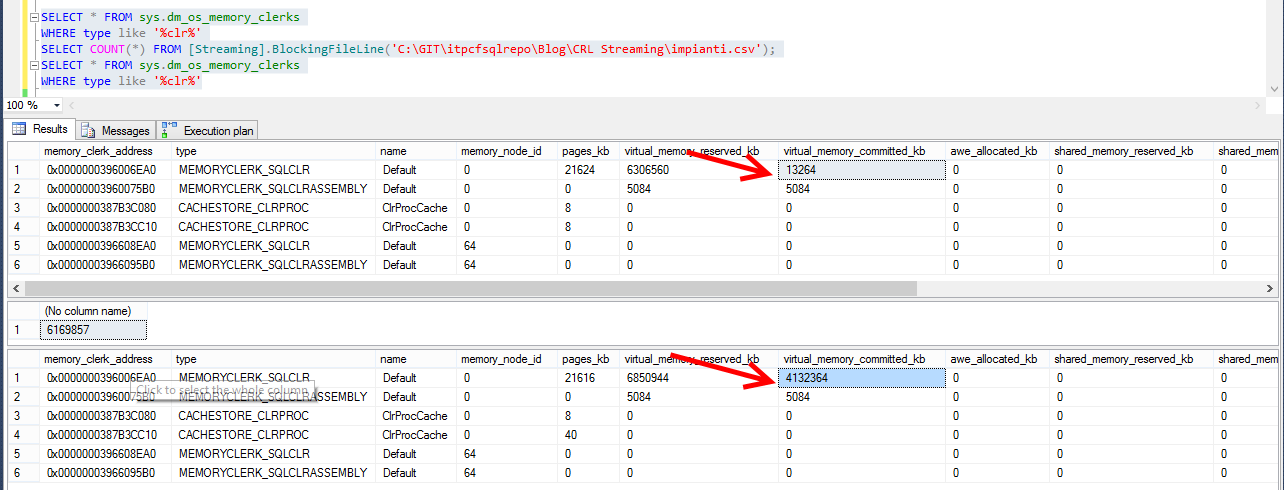
This is far from optimal. Look at the virtual_memory_committed_kb delta: it’s a LOT. SQL went from 13264 KB to 4132364 KB. It’s almost 4GB just for this function (~3.5 times the initial dataset)!
In SQL CLR functions we can – and should - use lazy evaluation instead: your main function is expected to return a System.Collections.IEnumerable instance. This is good: IEnumerable instances are not required to be able to tell the exact number of items in advance. This means that we can populate an IEnumerable while it’s being traversed. Using the streaming approach we don’t need to read all the file in advance. We can just read the relevant bits when requested.
In the previous example we returned a List (that implements IEnumerable). The list was populated in advance (hence the heavy memory usage). To use a streaming approach we need to return a custom class that implements IEnumerable directly:
[SqlFunction(
DataAccess = DataAccessKind.None,
SystemDataAccess = SystemDataAccessKind.None,
FillRowMethodName = "_StreamLine",
IsDeterministic = false,
IsPrecise = true,
TableDefinition = (@"Line NVARCHAR(MAX)"))]
public static System.Collections.IEnumerable StreamFileLine(
SqlString fileName)
{
System.IO.FileStream fs = new System.IO.FileStream(
fileName.Value,
System.IO.FileMode.Open,
System.IO.FileAccess.Read,
System.IO.FileShare.Read);
return new LineStreamer(fs);
}
Here our LineStreamer class is just a wrapper around our real implementation:
public class LineStreamer : Streamer, System.Collections.IEnumerable
{
public LineStreamer(System.IO.Stream stream)
: base(stream)
{ }
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return new LineStreamerEnumerator(stream);
}
}
The real code is in LineStreamerEnumerator class. That class will implement System.Collections.IEnumerator allowing it to be traversed in a foreach loop. In order to achieve streaming we should produce a row only when explicitly requested. We should also discard any non essential information in order to minimize the memory footprint.
Here we go:
public class LineStreamerEnumerator : System.Collections.IEnumerator, IDisposable
{
protected System.IO.StreamReader sr = null;
protected string _CurrentLine = null;
public LineStreamerEnumerator(System.IO.Stream s)
{
sr = new System.IO.StreamReader(s);
}
object System.Collections.IEnumerator.Current
{
get { return _CurrentLine; }
}
bool System.Collections.IEnumerator.MoveNext()
{
_CurrentLine = sr.ReadLine();
return _CurrentLine != null;
}
void System.Collections.IEnumerator.Reset()
{
throw new NotImplementedException();
}
#region IDisposable / destructor
void IDisposable.Dispose()
{
if (sr != null)
{
sr.Dispose();
sr = null;
}
}
// Finalizers are not supported in SQL CLR
//~LineStreamerEnumerator()
//{
// if (sr != null)
// sr.Dispose();
//}
#endregion
}
Notice that I’ve implemented the IDisposable interface explicitly. SQL Server will call Dispose on our enumerator as soon as it’s done with it. This will give us a chance to cleanup any lingering streams. We cannot use finalizers in SQLCLR as the example above illustrated.
Let’s try streaming in action:
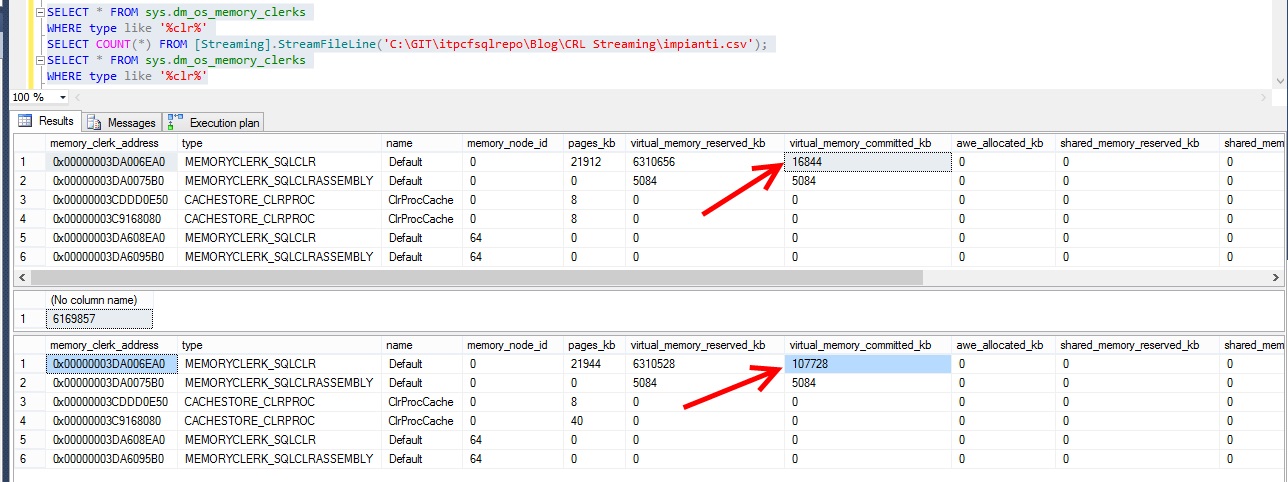
Here the memory delta is a LOT less (107728 – 16844 = 90884 kb). We lowered our memory footprint from 4GB to 100MB.
Impressive isn’t it?
Of course this is an ad-hoc example so you should not expect such big gains in real world. It is however a good practice to avoid blocking operators whenever possible.
More on the topic:
[MSDN] IEnumerable Interface (http://msdn.microsoft.com/library/system.collections.ienumerable(v=vs.110).aspx).
[MSDN] IEnumerator Interface (http://msdn.microsoft.com/library/system.collections.ienumerator(v=vs.110).aspx).
[MSDN] IDisposable Interface (http://msdn.microsoft.com/library/system.idisposable(v=vs.110).aspx).
Remember also that most .Net streams have automatic buffering so you don’t have to worry about it. This feature fits nicely in the streaming pattern; try it using the System.Net.WebRequest to understand why (or just look here if you’re lazy :)).
Happy Coding,