Tutto quello che avreste dovuto sapere sul TEMPDB e che non avete mai osato chiedere
Salve, ero indeciso sul fatto di creare un “post” sull’argomento, dato che si tratta di argomento trattato e ritrattato fino alla noia, ma all’ennesima domanda di un cliente che chiedeva chiarimenti sul numero di file da fare (vi dice niente ? :-) ) ho deciso di mettermi a scrivere questa pagina, con la promessa, però, di raccogliere nella maniera più sintetica possibile tutto quello che riguarda eventuali ottimizzazioni di performance e cercando di fugare la ridda di informazioni parziali, non corrette e vecchie che si trovano in giro su Internet, e talvolta anche nella documentazione Microsoft.
Ma perché il TEMPDB è così importante ? Principalmente per due ordini di ragioni:
- E’ una risorsa al pari delle CPU, della RAM, dei dischi e della rete: ne esiste solo uno per istanza, a prescindere da quanti database utente avete, quindi un eventuale collo di bottiglia su questa importante risorsa può influenzare tutti i database e le relative applicazioni;
- Molte “features” di SQL Server utilizzano il TEMPDB, direttamente o indirettamente, oltre ovviamente ad eventuali oggetti temporanei costruiti ed utilizzati dal codice applicativo; tra le “features” più voraci di spazio in TEMPDB e/o più importanti abbiamo:
Versioning (utilizzo degli “Snapshot Isolation Levels”);
Online index operations (create, alter, rebuild);
DBCC;
Cursori;
Triggers;
MARS;
Multi-statement table-valued functions (TVFs);
Dunque, ecco la lista dei punti qualificanti che vorrei presentarVi, ho evidenziato in blu le frasi più significative per darVi una visione immediata delle semplici regole da utilizzare:
1) Numero di data file
a. Questo è il punto di maggior confusione, esistono in giro varie interpretazioni basate sul numero di CPU, sull’Hyper-Threading, sui Core, e via discorrendo, fino ad arrivare alla regola che molti conoscono la quale finisce con la frase “…. ma non più di 8…”;
b. Il concetto teorico che sta dietro ad un stima corretta è: quanti thread (i.e. = query) ci possono essere, nel caso peggiore, che accedano contemporaneamente ad oggetti nel TEMPDB ? Questo dovrebbe subito rivelarVi che non importa l’Hyper-Threading o i Core, importa alla fine solo il numero di “CPU Logiche” che alla fine SQL Server si ritrova, al netto ovviamente di una eventuale “Affinity Mask” con cui è possibile limitare i Core/CPU utilizzati da una istanza di SQL Server. Se non volete affaticarVi nel conteggio, è sufficiente eseguire la seguente query per ottenere il numero esatto:
select COUNT(*) from sys.dm_os_schedulers where [status] = 'VISIBLE ONLINE'
c. OK, ora che sappiamo quante “CPU Logiche” ha la nostra istanza di SQL Server, quanti data file creiamo per il TEMPDB ? La regola più completa, ma non necessariamente la più corretta, è: “Tanti data file quante sono le CPU Logiche in uso all’istanza di SQL Server”; perché ho detto che non è necessariamente la più corretta ? Perché la regola vera sarebbe “Tanti data file fin quando non c’è più “contention” sulle pagine di allocazione di sistema contenuti nei data file stessi del TEMPDB”, ma non è molto semplice da appurare per un non esperto DBA, quindi manteniamo per semplicità la regola precedente marcata in blu.
NOTA: La famosa postilla che molti di Voi hanno sicuramente visto/sentito riguarda l’ipotetico massimo di 8 data file: intendiamoci, non è sbagliata a priori, il senso di questa regola è che se non sapete con certezza quanti data file fare per eliminare la “contention”, allora partite pure con la regola marcata in blu ma senza esagerare, un numero superiore di data file dovrebbe essere giustificato da una approfondita analisi delle performance del TEMPDB per capire se ha senso andare oltre;
d. E’ bene tener presente che fare un gran numero di data file per qualsiasi database, a maggior ragione per il TEMPDB, può avere effetti deleteri sul tempo necessario per portare “ONLINE” un database, dato che una delle fasi di “start” che opera in maniera rigorosamente seriale è appunto quella che analizza e poi apre (a livello NTFS) ogni singolo file.
e. IMPORTANTE: Vi prego di notare che ho sempre specificato “data file” e non “log file” o “transaction log file” (le definizioni sono equivalenti) dato che è assolutamente inutile fare “log file” aggiuntivi: a differenza dei “data file” che vengono usati in parallelo, i “log file” sono usati in seriale, solo al riempimento dell’uno SQL Server usa il successivo;
2) Dimensione iniziale
a. Questa è una delle più importanti ottimizzazioni, per qualche scellerato motivo, quando installate SQL Server, la dimensione iniziale dell’unico data file è di soli 8 MB, quella dell’unico transaction log file è di 1 MB, entrambi con “autogrowth“ del 10 %:
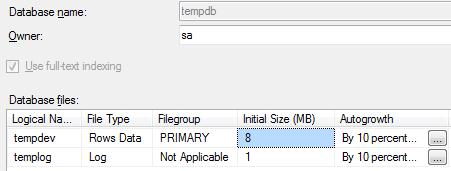
b. Se pensate che un TEMPDB può arrivare a svariati GB, se non decine o centinaia di GB, Vi immaginate quanti piccoli “pezzi” (fragment) sul file system dovranno essere allocati ? Migliaia se non milioni, e tutti di dimensioni ridicole, questo è il modo perfetto per distruggere le performance dell’NTFS anche sulle SAN più potenti !
c. La regola d’oro in questo caso è: “Immediatamente dopo l’installazione, rivedere le dimensioni iniziali del TEMPDB portando la dimensione dell’unico data file e del transaction log file ad almeno 1GB”.
NOTA: Non è detto che 1GB sia sufficiente, diciamo che l’NTFS sotto questa soglia ha performance non ottimali per i data file di SQL, su installazioni medie se non grosse consiglio almeno 4-8GB per i data file e 2-4GB per il transaction log file;
3) Autogrowth
a. Ad integrazione della precedente, aggiungo anche questa ulteriore regola: “Eliminare l’Autogrowth in percentuale ed impostare un valore fisso di incremento in MB per tutti i file, usando lo stesso valore”.
i. Che valore scegliere per l’ ”Autogrowth” ? Come raccomandazioni di massima direi almeno 1-2GB per i data file e tra 0.5 e 1.0GB per i transaction log file;
b. Nello scegliere la dimensione per l’autogrowth del transaction log file del TEMPDB, così come per ogni altro database utente considerate questa postilla aggiuntiva: “Evitate di usare il valore esattamente pari a 4GB per l’espansione del transaction log, altrimenti incorrerete in bug noto da 3 versioni di SQL Server”;
i. Il bug è descritto al seguente link:
Bug: log file growth broken for multiples of 4GB
http://www.sqlskills.com/BLOGS/PAUL/post/Bug-log-file-growth-broken-for-multiples-of-4GB.aspx
NOTA: Ho già verificato che nella CTP3 di Denali questo annoso, nel vero senso della parola, problema è stato finalmente risolto;
c. Lo scopo ultimo dovrebbe essere quello di evitare eventi di “Autogrowth” , dato che sono eventi bloccanti (per il workload di SQL Server) per l’intera durata dell’operazione di espansione, specialmente se:
i. Si tratta di transaction log file con incrementi cospicui, dato che non è possibile beneficiare dell’ “Instant File Initialization” (vedi punto[4] seguente);
ii. Si tratta di data file con incrementi cospicui e non si sta utilizando la feature “Instant File Initialization” (vedi punto[4] seguente);
d. Se volete sapere quali, quanti e di che durata sono stati gli eventi di “Autogrowth” sulla Vostra istanza SQL, è possibile utilizzare il report “Disk Usage” dalla console di SQL, tra gli “Standard Report” a livello di singolo database:
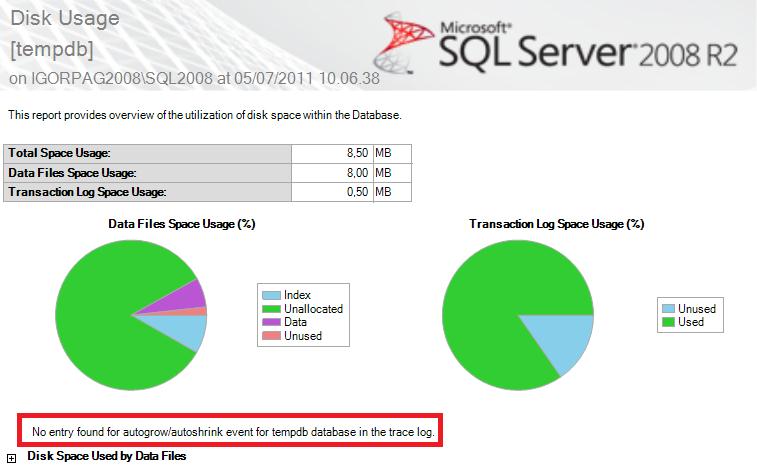
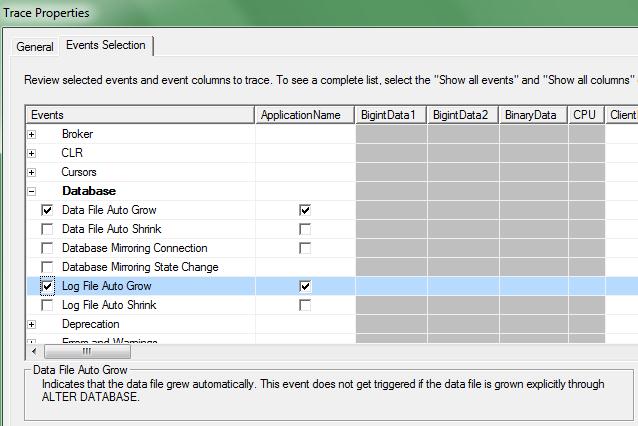
i. E’ anche possibile catturare uno specifico evento in una trace SQL con il SQL Profiler:
e. Utilizzando le informazioni dei punti precedenti, ecco una ulteriore regola a corollario della principale: “Dopo aver riconfigurato i valori di size ed autogrowth per i data/log file del TEMPDB, verificare periodicamente la numerosità e la durata degli eventi di autogrowth ed eventualmente ritoccarli ulteriormente per diminuirne frequenza e durata”.
4) Instant File Initialization
a. Si tratta di una importantissima “feature” dell’NTFS di Windows (>= 2003) che permette la creazione o l’espansione istantanea (1-2ms) dei data file di SQL Server, ma non dei transaction log files (quindi prestate attenzione!), anche di centinaia di Gigabyte (GB) o Terabyte (TB).
b. A meno che non abbiate interesse in una attività di “Security Hardening” molto spinta, consiglio caldamente l’abilitazione di questa funzionalità, come abilitarla è presto detto nella seguente frase che riassume questa raccomandazione: “Assicurarsi che il service account di SQL Server abbia lo user-right denominato [Perform Volume Maintenance Tasks] su tutte le macchine dove girerà il servizio”.
5) Posizionamento file
a. Dato che le performance del TEMPDB sono critiche, dovrebbe essere oggetto privilegiato per avere almeno una LUN dedicata, la regola più generale (e costosa !) possibile recita: “Il database TEMPDB dovrebbe avere una LUN dedicata per i data file ed una LUN dedicata per il transaction log file”;
b.Dare due LUN al TEMPDB potrebbe non essere sempre possibile per ragioni di costo, oppure potrebbe essere non necessario perché le altre LUN condivise potrebbero reggere il carico necessario;
c.In caso ci si debba ridurre ad una sola LUN per il TEMPDB, consiglio di dedicarla ai data file e di piazzare il transaction log file sulla stessa LUN utilizzata dai transaction log dei database utente;
6) RAID
a. Qui la storia è semplice, vale la regola generale per tutti i database, quindi la regola sommaria potrebbe recitare così: “Per la LUN del transaction log file del TEMPDB, scegliere un tipo di RAID che ottimizzi le scritture sequenziali (RAID-1 o RAID-10), mentre per i data file scegliere un tipo di RAID che ottimizzi letture/scritture random, pur garantendo il necessario grado di fault tollerance”.
b.La suddetta regola si riferisce ad una situazione ottimale, è anche possibile utilizzare un tipo di RAID meno performante, ma anche meno costoso, a patto che il sottosistema di I/O sia in grado di reggere il carico necessario;
c.Per verificare le performance dell’ I/O a livello di singolo file, non è possibile fare uso dei Performance Counters di Windows, è però possibile usare la seguente query in SQL Server (specifica per tutti i file del TEMPDB):
SELECT * FROM sys.dm_io_virtual_file_stats(DB_ID(N'tempdb'),null)
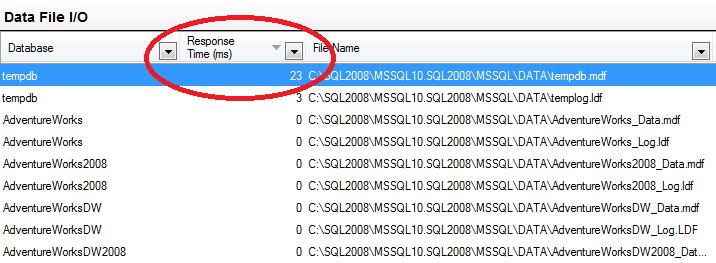
d.E’ anche possibile visualizzare in modalità “live” I tempi di accesso ad ogni file di ogni database, anche per il TEMPDB quindi, utilizzando l’Activity Monitor di SQL 2008 (e successive versioni) come da figura seguente:
b. Sebbene il TEMPDB sia un database con dati “a perdere” dato che tutti i suoi file vengono distrutti e ricreati ad ogni stop/start, “Per il TEMPDB è comunque sconsigliato utilizzare volumi di tipo RAID-0”: in caso di fallimento/corruzione del disco, l’intera istanza si fermerà se il TEMPDB non sarà in grado di funzionare correttamente.
7) Trace flags
a. I principali e più importanti “trace flags” con cui si può intervenire per ottimizzare le performance del TEMPDB sono due:
i. -T1118: Utilizzato moltissimo in SQL 2000 dove non erano presenti alcune importanti ottimizzazioni per il TEMPDB, è tutt’ora valido (e utile) anche in SQL 2005 e successive versioni: dopo aver abilitato tale trace flag, l’allocazione di spazio per gli oggetti temporanei avverrà solo utilizzando “extent” di tipo “uniform”, non più di tipo “mixed”, i particolari sono nel link seguente, questo serve a diminuire possibili colli di bottiglia sulle pagine di sistema di tipo SGAM in ogni data file del database:
Concurrency enhancements for the tempdb database
http://support.microsoft.com/kb/328551/en-us
SQL Server (2005 and 2008) Trace Flag 1118 (-T1118) Usage
http://blogs.msdn.com/b/psssql/archive/2008/12/17/sql-server-2005-and-2008-trace-flag-1118-t1118-usage.aspx
Misconceptions around TF 1118
http://www.sqlskills.com/BLOGS/PAUL/post/Misconceptions-around-TF-1118.aspx
ii. -T1117: Questo è molto meno noto del precedente, ma fornisce un’interessante funzionalità: nel caso il TEMPDB abbia più data file, quando un singolo file deve andare in “Autogrowth”, allora SQL Server espande tutti i data file comtemporaneamente; su alcune grosse installazioni di SQL Server, questo serve a mantenere perfettamente bilanciato lo spazio allocato tra tutti i data file presenti, migliorando la strategia di allocazione per il TEMPDB;
IMPORTANTE: Nel caso si decida di adottare il trace flag “-T1117” e/o si abbiano numerosi data file e/o le dimensioni di “Autogrowth” siano non trascurabili, assicurarsi di aver abilitato la feature “Instant File Initialization” altrimenti le operazioni di espansione si prolungheranno per un tempo potenzialmente lungo.
b. Questi trace flag devono essere aggiunti, eventualmente, agli “startup parameters” dell’istanza SQL Server mediante il tool “SQL Configuration Manager”, separati da “;” e facendo molta attenzione ad aggiungerli alla fine di quanto già presente senza sovrascrivere i parametri esistenti, e senza spazi tra “-T” ed il valore numerico (1117 o 1118):
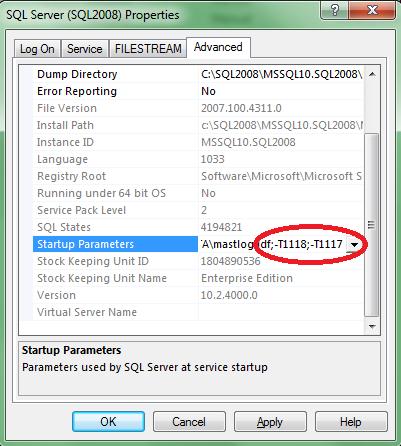
c. Per finire, ecco la regola sommaria: “Utilizzando il tool SQL Configuration Manager, aggiungere il trace flag –T1118, ed eventualmente anche –T1117, agli startup parameters dell’istanza SQL.
d. I parametri avranno effetto al successivo riavvio dell’istanza SQL, verificate che nell’ERRORLOG compaia una situazione del genere (deve comparire uno spazio tra –T ed il relativo valore numerico, altrimenti avete sbagliato qualcosa !):
Registry startup parameters:
-d C:\SQL2008\MSSQL10.SQL2008\MSSQL\DATA\master.mdf
-e C:\SQL2008\MSSQL10.SQL2008\MSSQL\Log\ERRORLOG
-l C:\SQL2008\MSSQL10.SQL2008\MSSQL\DATA\mastlog.ldf
-T 1118
-T 1117
8) Frammentazione esterna NTFS
a. Altro effetto sgradevole delle “Autogrowth” frequenti e/o di piccole dimensioni, è la frammentazione a livello NTFS dei data/log file non solo del TEMPDB, in questo caso, ma di tutti i database in generale, ovviamente è preferibile che tutti i data/log file di un database siano preallocati in maniera contigua evitando, per quanto possibile, susseguenti espansioni;
b. Se volete analizzare lo stato di frammentazione a livello di file system potete usare il seguente utilissimo tool dalla suite di SysInternals:
Contig v1.6 (by Mark Russinovich)
http://technet.microsoft.com/en-us/sysinternals/bb897428.aspx
c. Dato che ho già formulato, nei paragrafi precedenti, le regole relative alle dimensioni raccomandate per la size iniziale e per l’”Autogrowth”, qui non mi rimane che aggiungere la seguente regola accessoria: “E’ consigliato controllare periodicamente la frammentazione a livello di file system dei data/log file che compongono il TEMPDB, utilizzando il tool Contig di SysInternals ”; nel caso che uno o più dei suddetti file sia composto da più di una decina di “fragments” è consigliato rigenerare i file del TEMPDB con i seguenti macro passi:
i. Fermare il servizio SQL Server;
ii. Eseguire un backup “offline” di tutti i data/log file che compongono tutti i database (di sistema e utente) dell’istanza, ad eccezione del TEMPDB;
iii. Utilizzare un tool di deframmentazione disco ed attivarlo sulla/e LUN in oggetto per ricompattare lo spazio libero su disco.
iv. Riavviare l’istanza SQL: al riavvio il database TEMPDB sarà ricreato in ogni suo file, stavolta con dimensioni iniziali congrue in modo da evitare ulteriori frammentazioni dovute a valori iniziali troppo piccoli e/o autogrowth troppo frequenti;
9) Frammentazione interna VLF
a. Il transaction log di ogni database ha una sua struttura interna complessa, cercando di condensare quanto più possibile, esso è diviso in un numero variabile di unità contigue di spazio disco denominate Virtual Log Files (VLFs): quanti VLF, e di che dimensione lo decide SQL Server autonomamente senza possibilità di intervento diretto, l’unico modo di influenzarlo è stabilire la dimensione iniziale del transaction log e la dimensione delle eventuali autogrowth, in base a questi SQL Server farà le sue scelte; I particolari li potete trovare a questo link:
Transaction Log Physical Architecture
http://technet.microsoft.com/en-us/library/ms179355.aspx
b. Il problema nasce se il numero di VLF diventa elevato, questo infatti può impattare, in generale su ogni database ed in parte anche sul TEMPDB, pesantemente su attività come la recovery di un database (alla partenza di SQL), i tempi di backup/restore, le autogrowth del transaction log ed addirittura le classiche operazioni di manipolazioni dati (DML);
c. In base alle considerazioni dei due punti precedenti, ecco la regola sintetica di questo paragrafo: “Periodicamente, è necessario monitorare il numero di VLF per il database TEMPDB e se ne risultano più di 100 è necessario intraprendere azioni correttive”;
i. Per controllare il numero di VLF per tutti i database, anche per il TEMPDB, è possibile utilizzare lo script che trovate al seguente link, gentilmente fornito dal nostro buon amico Paul Randal (http://www.sqlskills.com):
http://www.sqlskills.com/BLOGS/PAUL/file.axd?file=2010%2f4%2fSQLSkillsLogInfo.zip
d. Le azioni correttive per abbassare il numero dei VLF nel database TEMPDB sono le seguenti:
i. Aumentare la dimensione iniziale del transaction log in maniera congrua, seguendo le raccomandazioni di questo documento;
ii. Aumentare la dimensione della eventuale autogrowth in maneria congrua, seguendo le raccomandazioni di questo documento;
iii. Riavviare l’istanza SQL Server per rigenerare il database TEMPDB;
10) Formattazione LUN
a. Se avete ancora la sfortuna di dover ancora installare (o gestire) SQL Server su Windows Server 2003 (o precedenti) fate molta attenzione all “Partition Alignment”, dato che tali versioni di Windows, by default, creano le partizioni “disallineate” con offset a 31.5 KB; la perdita di performance, sul sottosistema di I/O, può arrivare anche al 50%, è caldamente consigliato crearle, quindi, con offset a 1MB come da default per Windows Server 2008 e successive:
Disk Partition Alignment Best Practices for SQL Server
http://msdn.microsoft.com/en-us/library/dd758814.aspx
NOTA: In genere l’offset a 1MB è ottimale per tutte le “stripe unit” delle SAN attualmente in commercio, in ogni modo è consigliato verificare con il Vendor per eventuali differenti raccomandazioni in tale senso.
b. A meno che il Vendor della Vostra SAN non abbia differenti e specifiche raccomandazioni in materia, formattare la partizione per il TEMPDB con “allocation unit” a 64KB;
NOTA: entrambe queste raccomandazioni si applicano in generale alle LUN utilizzate per tutti i database, non solo per il TEMPDB.
In aggiunta a questa lunga lista, ecco alcune importanti informazioni e peculiarità sul TEMPDB:
- Da SQL 2008 è possibile abilitare l’algoritmo di tipo “CHECKSUM” (default in SQL 2008 e seguenti) anche sul TEMPDB;
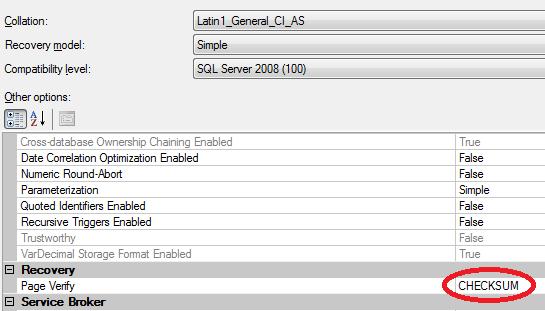
- Il “Recovery Model” di default del TEMPDB è SIMPLE (vedi figura precedente) e decisamente non vedo ragioni per cambiarlo;
- Aspetto teorico, ma anche “capacitivo”, molto interessante del TEMPDB: al contrario dei “normali” database utente, dove sia le informazioni di “redo” (roll-forward) che di “undo” (roll-back) delle transazioni vengono inserite nel transaction log, nel TEMPDB solo le informazioni di “undo” vengono considerate in modo da poter supportare eventuali “rollback” delle transazioni utente che contengono tabelle temporanee; non è necessario avere le informazioni di “redo”, necessarie eventualmente solo nella procedura di “crash recovery” (di qualsiasi altro database), quando esso viene messo/portato “online”, perché il TEMPDB viene ricreato da zero e non passa attraverso tale procedura.
- Il processo di “Checkpoint” interno di SQL Server, è attivo anche sul TEMPDB ma si comporta in maniera leggermente differente: generalmente (esiste un’eccezione), le “dirty pages” in memoria relative al TEMPDB non vengono scaricate (flush) su disco proprio perché il TEMPDB non passa attraverso la procedura di “crash recovery” quando và online; l’eccezione è la regola per i database in SIMPLE recovery model, e cioè quando lo spazio effettivamente usato arriva al 70% della dimensione totale.
- In SQL Server 2005 è stato introdotto un meccanismo di “caching” specializzato per il TEMPDB in modo da eliminare gli storici colli di bottiglia sulle mappe di allocazione: quando si distrugge un oggetto temporaneo in TEMPDB, non tutto viene deallocato, una pagina di tipo “IAM” (index allocation map) ed un data page rimangono, in modo da poter essere eventualmente riutilizzate senza dover passar da alcune tabelle di sistema (di allocazione) di SQL Server;
- In aggiunta ai normali performance counters utilizzati per ogni database utente, il TEMPDB ne ha alcuni specializzati che è bene tenere sotto controllo:
• General Statistics -> Active Temp Tables;
• General Statistics -> Temp Tables Creation Rate;
• General Statistics -> Temp Tables for Destruction;
• Transactions -> Free Space in tempdb (KB);
• Transactions -> tutti i counters che iniziano con "Version";
- Credenza popolare assolutamente sbagliata: le variabili di tipo tabelle temporanee stanno in memoria e non in tempdb, ovviamente non è vero !
- Anche per il TEMPDB è possibile eseguire il controllo per la presenza di eventuali corruzioni con il comando “DBCC CHECKDB”, cosa per altro consigliata;
- Anche per le tabelle temporanee create in TEMPDB, è possibile creare indici e statistiche, inoltre le funzionalità a livello di database denominate “AutoCreate Statistics” e “AutoUpdate Statistics” sono attive ed è consigliato lasciarle in questo stato.
- Il “database ID” del TEMPDB è sempre (2), ricordavelo, specialmente quando analizzate eventuali blocchi, deadlock, o report di corruzione;
- Attenzione quando abilitate la “Transparent Database Encryption” (TDE) di SQL 2008 su un qualsiasi database utente perché anche il TEMPDB sarà totalmente criptato, sia nella parte relativa ai data file che transaction log files.
- Attenzione ad eventuali operazioni di “shrink” manuale sul TEMPDB, potreste causare una corruzione dello stesso database, leggete bene il seguente articolo, in particolare la sezione "Effects of Execution of DBCC SHRINKDATABASE or DBCCSHRINKFILE While Tempdb Is In Use":
How to shrink the tempdb database in SQL Server
http://support.microsoft.com/kb/307487/en-us
- La “Collation” con cui il TEMPDB viene creato è quella di sistema che Voi avete specificato all’atto dell’installazione, fate attenzione ad usare database con tale differente impostazione perchè, nel caso le Vostre query facciano un confronto tra stringhe e/o tipi di dato strutturati (money, datetime, etc.) potrebbero esserci dei problemi o degli errori perché il confronto è tra “Collation” differenti e potrebbe essere necessario inserire delle conversioni forzate (“collate” query hint option) per rendere consistente il risultato.
Spero di avere inserito tutto, nel caso mi fossi dimenticato qualcosa non esitate a farmelo sapere.
Al prossimo post !
--Igor Pagliai--