Endpoints, firewalls and other annoyances
When you deploy a HPC cluster on Azure, you typically want to run some application in it besides those provided in the azure samples. Those applications may require their own ports to be opened on the internal network and endpoints to be established for both internal and external communication. There is no hpc cluster manager gui in a pure azure implementation, so you'll have to perform such configuration manually.
1. Enabling endpoints
Endpoints must be configured prior to deployment, in the Azure service definition file. For instance, if you want to allow file sharing between nodes, you'll need SMB endpoints.
<Endpoints>
<InternalEndpoint name="SMB" protocol="tcp" port="445" />
<InternalEndpoint name="Netbios" protocol="tcp" port="139" />
</Endpoints>
Note that the default configuration for azure hpc samples enables port 445 but not 139. That can be corrected via Visual Studio or by manually editing the .csdef file.
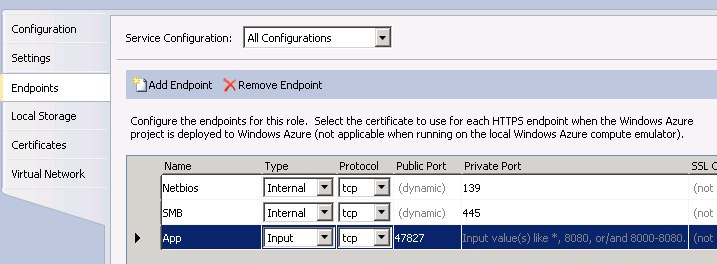
If you define a public endpoint too (as in the picture), remember that it will be subject to the azure load balancers and no "sticky" sessions are supported.
After deployment, you'll be able to share files and directories as usual. If you use a directory on an azure drive mounted as per my previous post, you will have a form of shared permanent storage for computation inputs and results that will persist between deployments.
2. Opening ports on the nodes
Establishing endpoints may not be sufficient. You will also need to open the relevant ports on the o/s firewalls of the nodes in question. For instance, the command line below will open ports 55000-55500:
clusrun /all netsh advfirewall firewall add rule name="myapp" dir=in protocol=tcp localport=55000-55500 action=allow
You may also need to register an exception with the windows firewall for the executables that you plan to run and any other executables that they may invoke in turn:
clusrun /all hpcfwutil register myapp.exe "d:\Program Files\myapp\myapp.exe"
At this point you can submit jobs via the portal or the command line, e.g.
job submit /numcores:16 /stdout:\\headnode1\share\myapp.out /stderr:\\headnode1\share\myapp.err mpiexec myapp.exe -<parameters>
The command line above submits an mpi job requiring 16 cores to run myapp.exe (assuming it is installed on the nodes), redirects outputs and errors to files on a share on the headnode.
3. Observations
Note that in the azure hpc sample deployment, the headnode is always called headnode1 and the compute nodes computenode1, 2, 3, etc... This has no relationship with the actual host names, which are assigned randomly by the azure fabric controller at deployment and can change. Also, computenode1 is not necessarily the first instance of the computenode role listed on the azure portal.

A list of aliases is maintained automatically in %WINDIR%\system32\drivers\etc\hosts
I have noticed however that for all mpi jobs I have submitted, mpi rank 0 was always on computenode1. That may be a sheer coincidence, as there is no reason for it to be there that I can think of. I'd be curious to know whether you find the same situation or not.
This may be useful anyway, because certain applications may require a connection to rank 0 for their GUI, in order to display the status of the running computation.
Powered by Qumana