Determining an Application's Impact when Assessing Risk
In my most recent blog (https://blogs.technet.microsoft.com/gladiatormsft/2018/02/14/leverage-a-risk-based-approach-to-application-compatibility-testing/) I discussed how successful shifts to managing application compatibility involve moving to a model that prioritizes testing according to risk factors. The model I usually recommend to customers is to apply a common two-dimensional graph based on two primary risk factors: Impact to business and the application's likelihood of breaking. Both risk factor topics involve their own separate discussions which for me, warrants an additional blog post discussing each more in depth.
For today’s discussion, I would like to dive further in how organizations determine an application’s impact to their business and ultimately, their bottom line. I do not necessarily advocate a one-size-fits-all prescriptive guidance approach as that would be very difficult to implement across different types of organizations due to degrees or variance including industry and cultural factors. The right way to assess an application’s impact to the business is the approach that 1.) Properly and accurately assesses the application’s impact while 2.) allowing the stakeholders responsible for ongoing application compatibility testing to rationalize the testing priority properly allowing 3.) the deployment and servicing schedules of Windows and its feature updates to continue unabated. In other words, ensures that you place the applications most critical in early testing rings well in advance of the broader deployments.
The “Functional Spec” Approach
The most common and simplest method of determining an applications impact is also not the always the most accurate assessment. However, it can still be used as a starting point for narrowing down the filed of applications that will need a more through assessment. It is nicknamed the “Functional Spec” approach because it follows a P0/P1/P2 ternary approach to grouping applications as if one were group features in a functional specification document. It is also simple to grasp. Is this particular application a:
- Must Have?
- Nice to Have?
- Don’t Care?
Again, getting all the applications that we either do not care about or even further, do not want, out of the priority list, is a great first step toward rationalization. This, however, as an end-all be-all approach is flawed in that it does not cover all variables that could apply to the overall risk factor of true impact. It can also fall prey to subjectivism much more easily – especially if not all the correct stakeholders are involved in the process.
The Approach that Ranks by Number of Deployments or Users
A variable that can never be ignored is the number of deployments of the application. Unfortunately, this type of data collection implies the number of users that use that application which is not always the case. For example, we’ve discovered internally through our own internal research within Microsoft that an application might be placed into a standard image but only actually be used by ¼ to 1/3 of the user base. A standard inventory of all end-user devices will return 100% deployment, but only deeper telemetry can attest to if the application is being used and how often.
Barring deep analytics, deployment counts are the only thing most organizations must rely on when determining who uses what application as traditionally, much of the applications are still Win32 applications distributed and inventoried by device rather than by user. In most cases, even if the device is targeted implicitly (because a targeted user is logged on to that device) the application is installed and remains there upon that user logoff for other users. In addition, unless the devices are identified as being part of a specific business unit and the application is targeted specifically to those device groups, it is difficult to ascertain without deep analytics which business units use a specific application. Still, deployment counts matter. And should probably be included in how your organization determines the impact of an application. It just should be a variable and not the approach.
True Impact Factors
True impact factors are those applications that warrant automatic elevation to a high or critical risk pool. The types of factors often include and application’s:
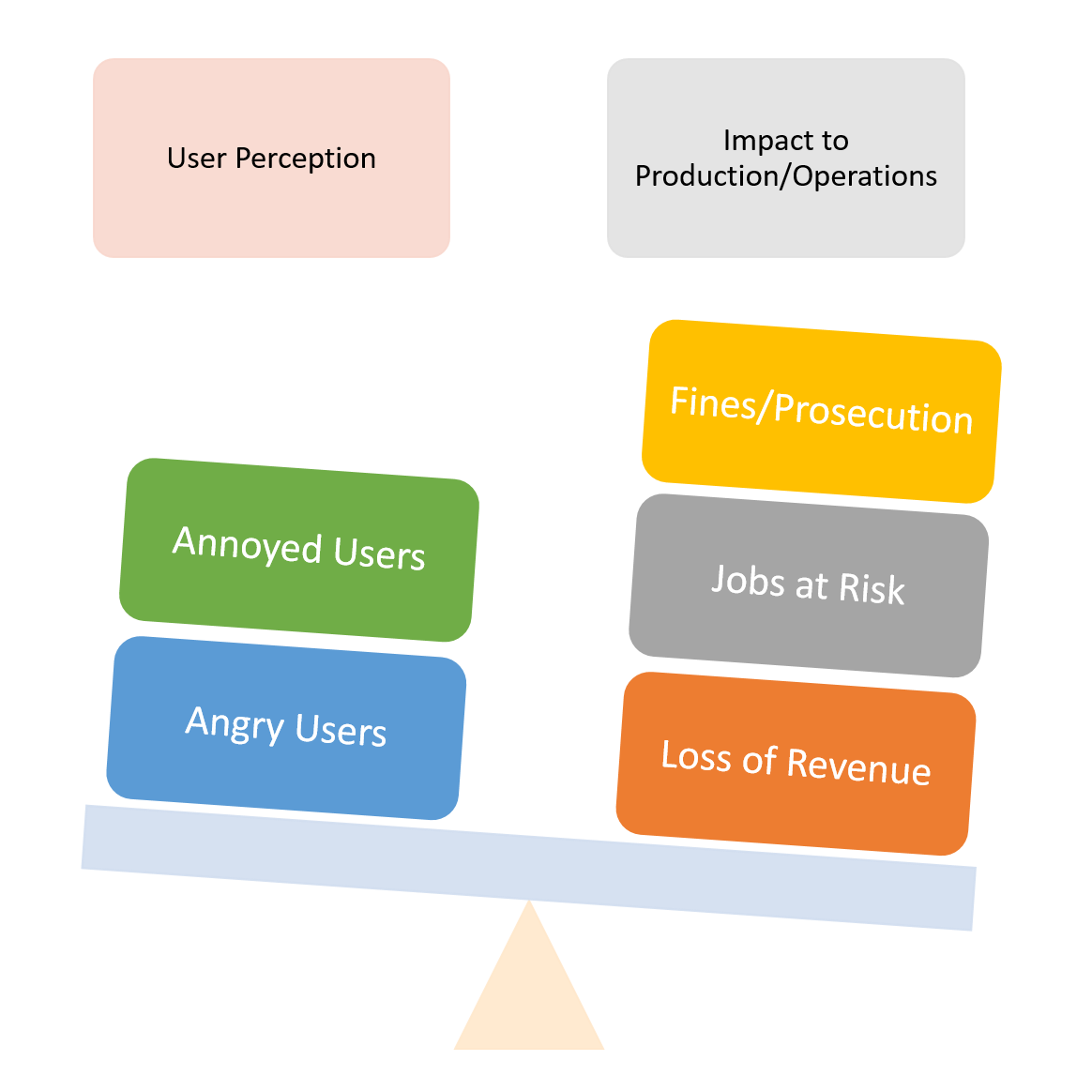
Alignment with Revenue: Does the application have a direct or indirect relationship to revenue? Is the application critical for production or operations of a critical business unit tied to production or revenue? Understand the concept of “production,” “operations,” and “revenue” will vary across industries. A point-of-sale application is more critical in retail organizations while an IT service application is more critical with a service provider that must meet specific SLAs (Service-Level-Agreements.) These applications are almost always elevated into a critical risk pool.
Alignment with Compliance or Regulation Requirements: Applications that are in place to maintain data, implement processes and procedures, or audit/measure factors to confirm to various requirements. Non-compliance or violations could lead to fines or other unthinkable results. These applications are almost always elevated to a high risk or critical risk pool.
Alignment with Political or Executive Factors: This might be a sensitive one to quantify as the risk varies according to internal tribal policies. For example, there might be an application that only 10 users use, but all those users have titles that are TLAs (three-letter-acronyms) that begin with C. Since any risk factor that could potentially involve someone losing their job is critical or high, sometimes these applications are elevated into a high or critical risk pool.
User (HelpDesk) Impact
This is more than just angry or annoyed users. Maintaining and training helpdesk staff can be a costly task for large organizations. This is why, in many cases, an application’s user impact weighs as significant importance as factors previously mentioned. For example, an application may encounter a regression where an annoying pop-up might interrupt the user when they click on a specific menu item. The message and outcome might be benign, and it boils down to being merely a cosmetic inconvenience as opposed to a true functional defect. However, if 85% of the user base uses this application and the issue creates a scenario where a significant percentage of them might not realize it is a benign error, work stoppages occur and help desk calls are generated create impact and additional costs to the organization’s bottom line.
Which is Best?
The simple answer is some or all the above. A slew of variables can be used to calculate an applications true impact, but remember, this needs to be a true assessment of impact to the overall business and emotions need not be a part of the process. I use an exercise with customers during workshops involving these variables as they might apply to a randomly selected subset of applications from an internal portfolio. It is a worthwhile exercise to go through as you discover how much time and resources may have been wasted on unnecessary testing in the past.
This, of course, is only part of the process. In my next blog post, we will discuss the other important risk vector – the likelihood of an application breaking when testing a new version (feature update) of Windows.