Testing Log Analytics HTTP Data Collector API limits with PowerShell
Recently we announced a new API for uploading quasi any data from anywhere to OMS (Log Analytics) as long it is presented to OMS in a non-nested JSON format.
See these excellent articles for more details:
https://blogs.technet.microsoft.com/msoms/2016/08/30/http-data-collector-api-send-us-data-from-space-or-anywhere/ https://azure.microsoft.com/de-de/documentation/articles/log-analytics-data-collector-api/
I was curious about the performance of this API and wanted to know:
- What’s the maximum data size to be uploaded?
- How is the upload speed?
- How fast is the OMS index engine working?
- Relation between raw (source) data size and data usage in OMS Log Analytics?
- How reliable is the API?
DISCLAIMER:
This is not an official test nor is it a correct scientific approach! All results are based on my own findings and only express my own personal thoughts!
Findings & Conclusion
I will start this post with my findings and conclusions. If you are curious to know how I came to these conclusions, please read the rest of the post.
- Data size and upload speed
- It is best to upload bulk data if possible. Prevent uploading records one by one! The smaller the uploaded chunks of data the bigger the overhead of creating the whole http request with its authenticated header! Using my test data, sending up data one element after another can take about 70ms per element, whereas sending data up in bulk can reduce the time down to a few Milliseconds (e.g. 3ms) per element.
- You can roughly upload up to 30 MB of data with one http request.
- You can upload thousands of JSON elements with one http request. The only thing that matters is the size of the http request!
- I did not notice any significant performance differences uploading CSV files with 20 or 50 columns and different column length. Even objects with 50 columns (= properties of an object) with a content length of up to 500 character per column poses no problem for the API or the OMS data ingestion process.
- I tested the upload over several network connections (symmetric WAN (100 Mbit/s), asymmetric cable based WAN (200 Mbit/s down, 20 Mbit/s up, LTE connection) and did not notice any significant change of values (except of the overall upload speed).
- Indexing time
The indexing time, that is the time between inserting the data into Log Analytics and beeing able to fully search the data in the portal, depends on whether it is a completely new data type or you are simply adding data to an existing type:- Inserting 10.000 elements of a new data type (aka a new CustomLog type like MyCustomLog_CL) can take up to 15 min for the data to be fully searchable.
- Appending 10.000 elements to an existing data type only takes only a few seconds to be fully searchable.
- Creating a completely new OMS workspace and then inserting 10.000 elements of a new data type takes between 15 and 25 min for the data to be fully searchable.
- Data usage in Log Analytics compared to raw data size
OMS Log Analytics adds no significant overhead to the uploaded data. On the contrary: Depending on the type of uploaded data I noticed even some data reduction of up to 10% between the uploaded file size, the content length of the http request and the resulting data usage in OMS! It looks like OMS handles the uploaded data quite efficiently. - Reliability
The http API is very reliable. All my uploaded data (and I did a lot of testing) appeared in Log Analytics completely after a while. Only the error handling (http status codes and descriptions) can be sometimes a bit misleading: E.g. if the body of the http request is too big, we get a 404 with the description “File not found” back in PowerShell.
IMHO the API does a very good job and can be used to reliably upload almost any kind of data (that can be converted to JSON)!
Preparation
RECOMMENDATION:
As I do not want to "spoil" my usual OMS workspaces with dummy data, I simply create new workspaces with a free tier (500 MB data limit is completely sufficient for these tests). For automatically creating such workspaces see my post here.
I started testing the API with some random CSV files found on the net, but soon figured out that I need more consistent, reliable data. So I created a short PowerShell function new-csvdata which allows me to create arbitrary CSV files with flexible row and column count as well as column width.
Usage looks like this:
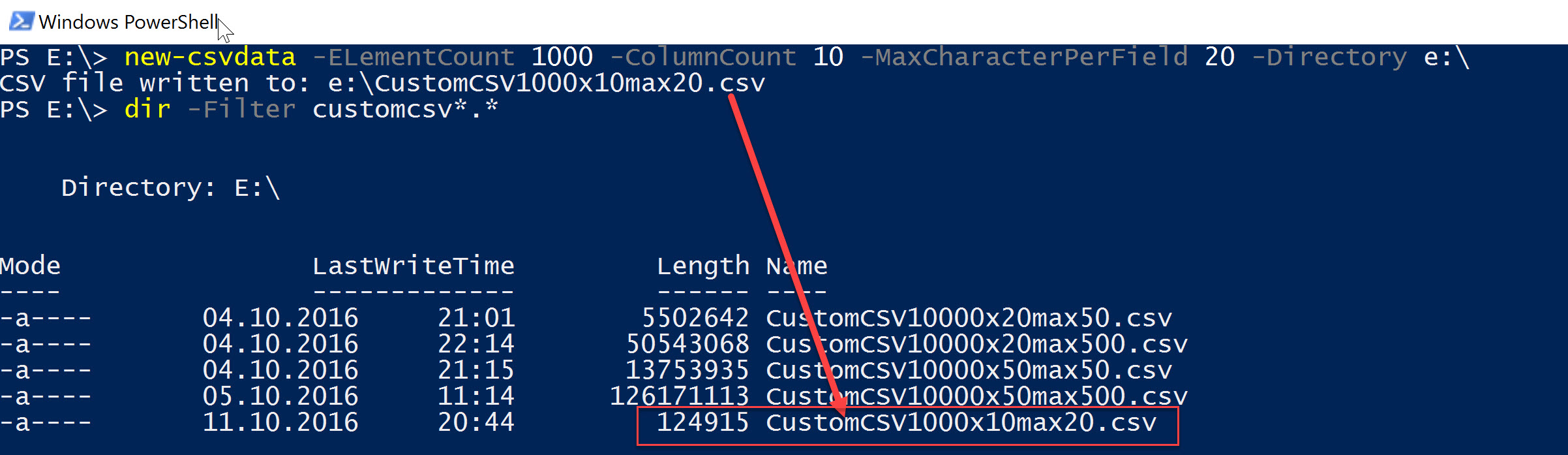
I created 4 files for my tests:
- CustomCSV10000x20max50.csv
10.000 rows, 20 columns with 1-50 random char width, total size approx. 5MB - CustomCSV10000x50max50.csv
10.000 rows, 50 columns with 1-50 random char width, total size approx. 13MB - CustomCSV10000x20max500.csv
10.000 rows, 50 columns with 1-500 random char width, total size approx. 49MB - CustomCSV10000x50max500.csv
10.000 rows, 50 columns with 1-500 random char width, total size approx. 123MB
And I created a small script Test-OMSDataUpload.ps1 which
- Converts any kind of CSV file into JSON
- Uploads the converted CSV file to OMS using a specific workspace
- allows to specify the number of CSV rows (elements) to be upload per http request
- Returns a detailed result after uploading the data
The script uses these params:
- OMSWorkspaceID
GUID of the OMS Workspace - OMSSharedKey
PrimaryKey, needed for authorizing and signing the upload request. - OMSLogTypeName
Name of the custom logtype created in OMS. Like “MyCustomData”, this will be visible in OMS as data type MyCustomData _CL - CSVFile
Path of the CSV file to be uploaded. - BulkObjectCount
Number of CSV elements to be uploaded per http request
The script returns an array where:
- $Result[0] contains an arry with these properties for each performed http request (= OMS data upload):
- HttpStatusCode
Should be 202 - HttpStatusDescription
Returned description if any - ContentLength
Content length of the http body - ContentLengthMB
Same in MB - RawDataContentLength
Raw size of CSV element converted to string - ElapsedMS
Millisenconds used for processing the request - UploadSpeedMBperSec
Content length / Elapsed Milliseconds - ElapsedMSTotal
Total time in Milliseconds - Start
Number of start element for the request - End
Number of end element for the request - PSError
PowerShell Error message per http request if any
- HttpStatusCode
- $Result[1] contains the total elapsed time in Milliseconds
A sample script call might look like this:
PS E:\> $result50x500x5000 = .\Test-OMSDataUpload.ps1 -OMSWorkspaceID $ws.CustomerId -OMSSharedKey $keys.PrimarySharedKey -CSVFile E:\CustomCSV10000x50max500.csv -OMSLogTypeName Oct1050x500 -BulkObjectCount 5000
Performing data insert tests
I called the script Test-OMSDataUpload.ps1 with multiple CSV files and different column sizes:
E.g. 20 columns with up to 50 characters per column:
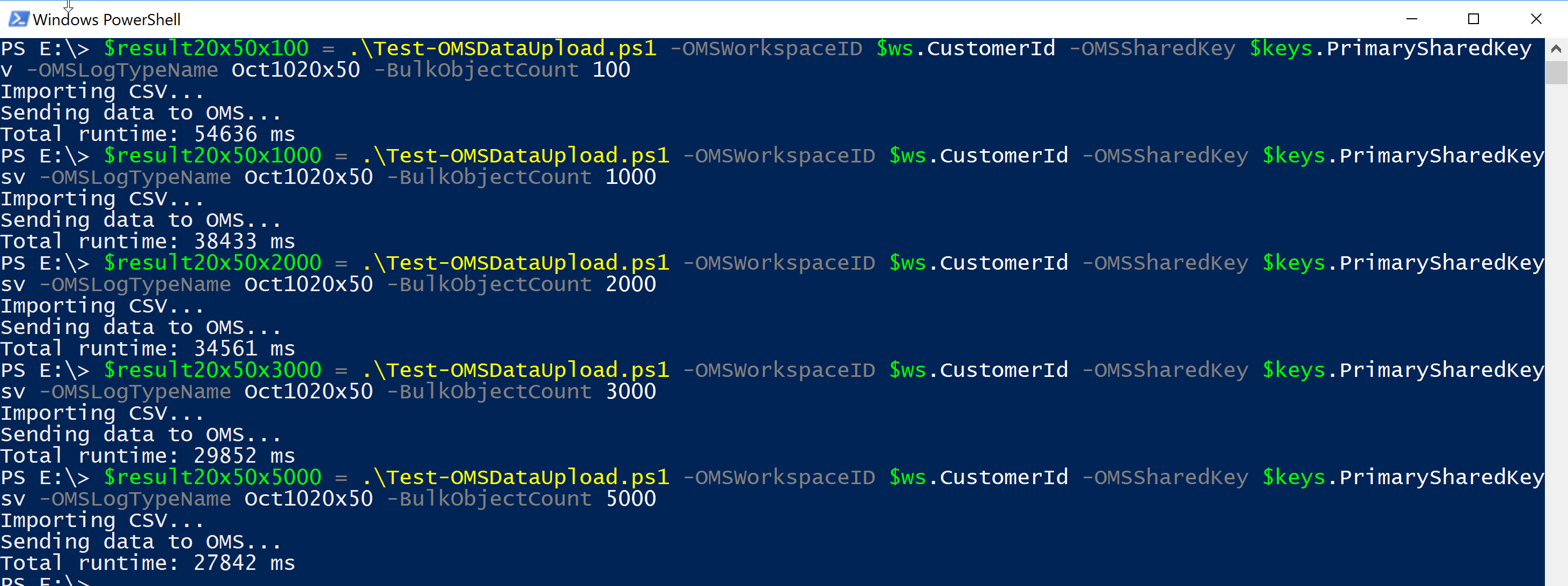
Note the decrease in total elapsed time when increasing the number of elements to be uploaded.
Or 50 columns with up to 500 characters per column:
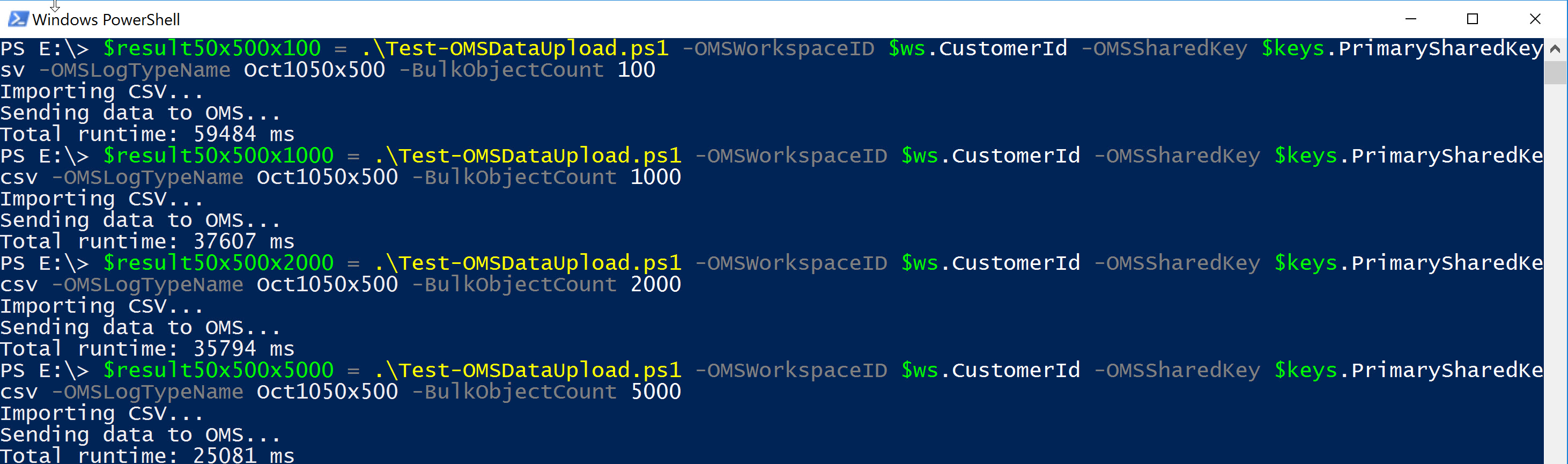
Note the decrease in total elapsed time when increasing the number of elements to be uploaded.
After performing the uploads let's have a look at the resulting objects:
For 20x50:
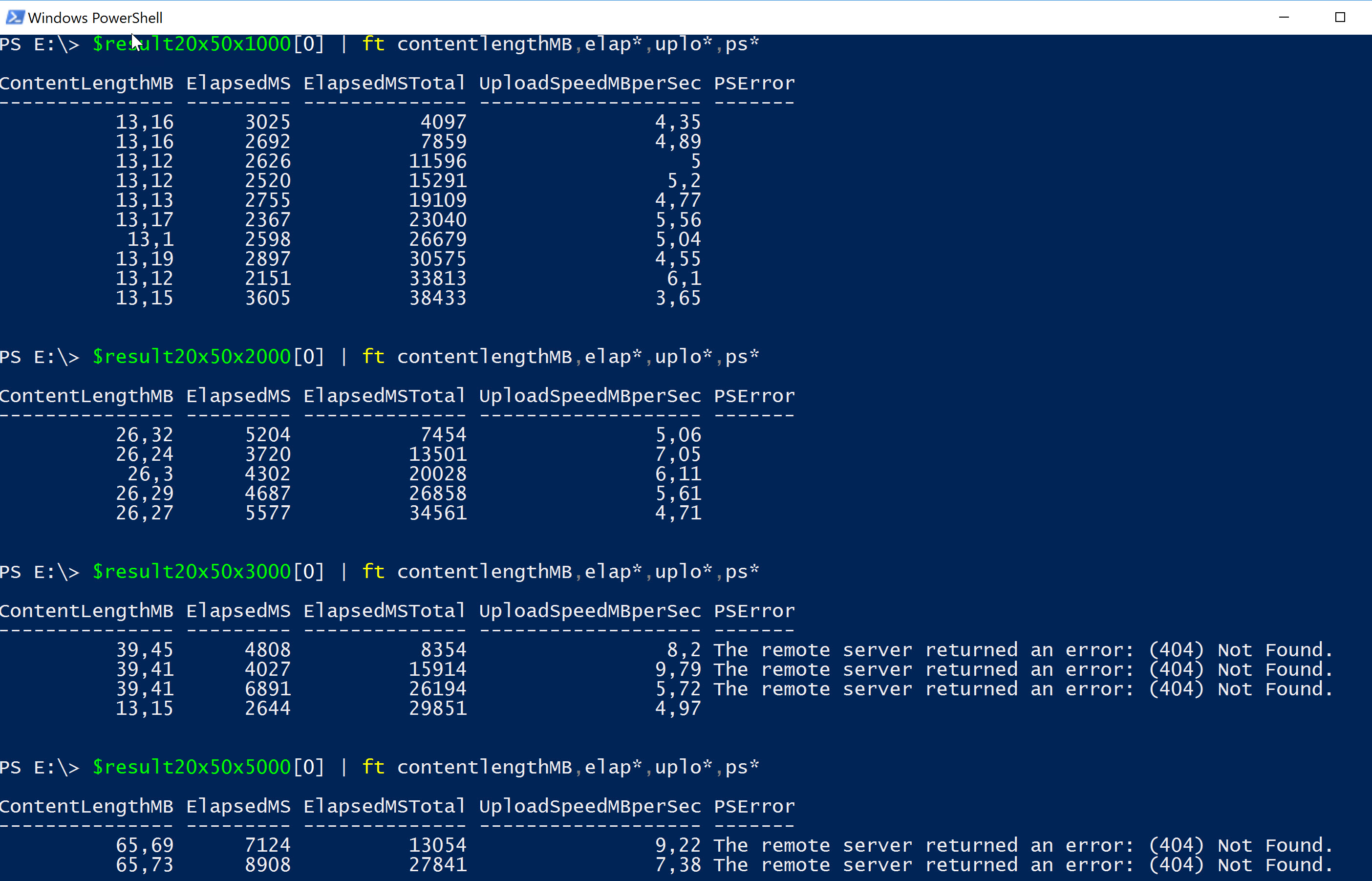
There is a slight improvement increasing the number of elements from 1000 to 2000. But as soon as we reach the 30MB request body size (3000 elements in this case), our request will fail!
And for the 50x500:
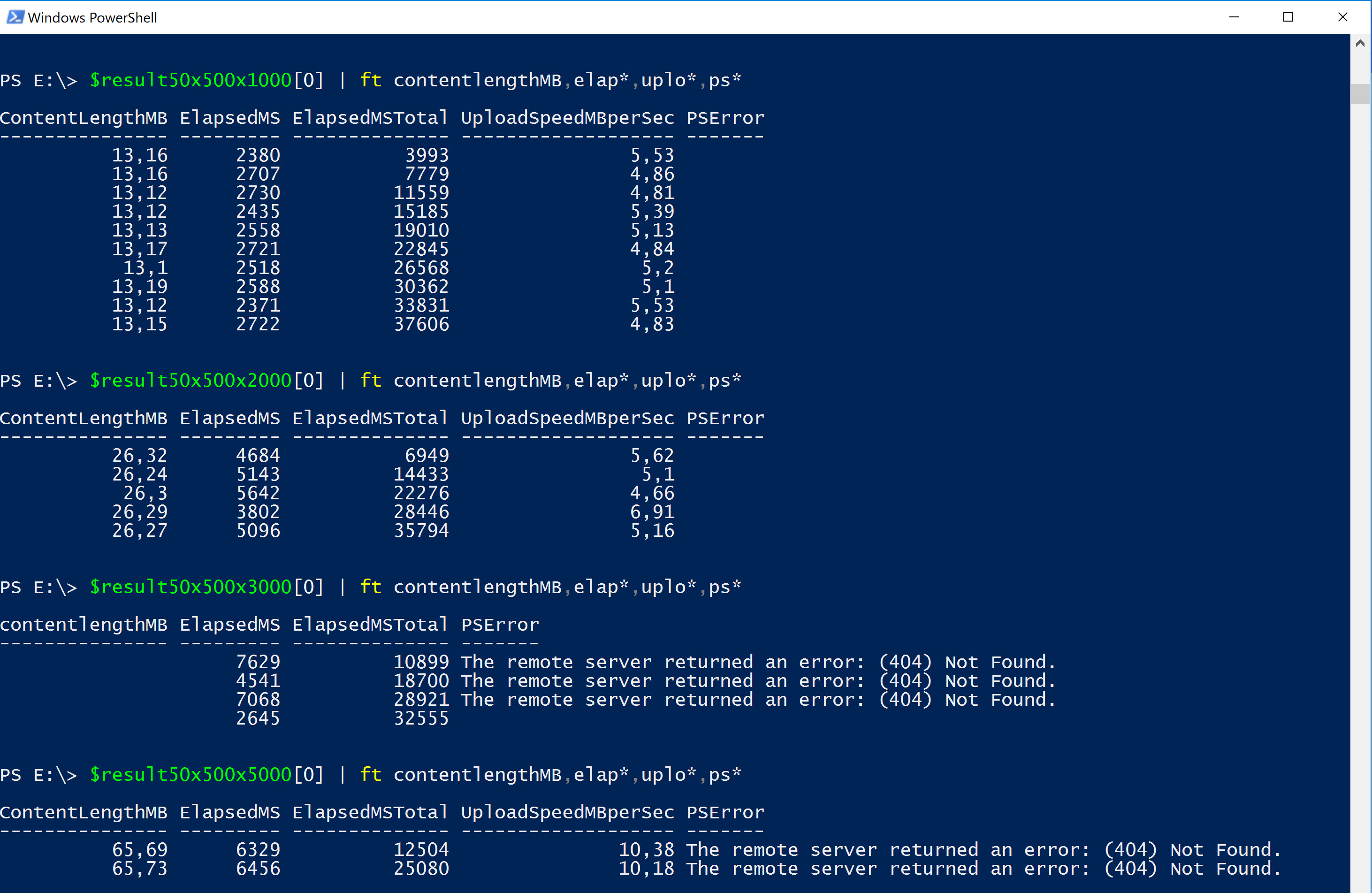
Same result here...
Testing the indexing time
How long does it take from sending the data to OMS until beeing able to fully search it via a query? To answer this question you can use the builtin Log Analytics "Usage" data type and its property AvgLatencyInSeconds. If you multiply the Batch count by AvgLatencyInSeconds you get the total index time for the ingested data. But this record gets only calculated once per hour and does not include the time it takes to generate new data types.
Sitting in front of the portal and checking it manually is obviously also no option, so I wrote another small script CheckOMSIndexPerformance.ps1 which:
- Connects to my workspace
- Executes a search query equal to this:
Type=MYDATATYPE_CL TimeGenerated > NOW-NMINUTES| measure count() as ElementCount by Type - Parse the result property ElementCount if it contains the previously inserted amount of elements (in my tests usually 10.000)
- Measure the time it takes to show up the right amount of elements
The next example shows two scenarios:
Uploading data as a new data type and uploading data using the same data type:
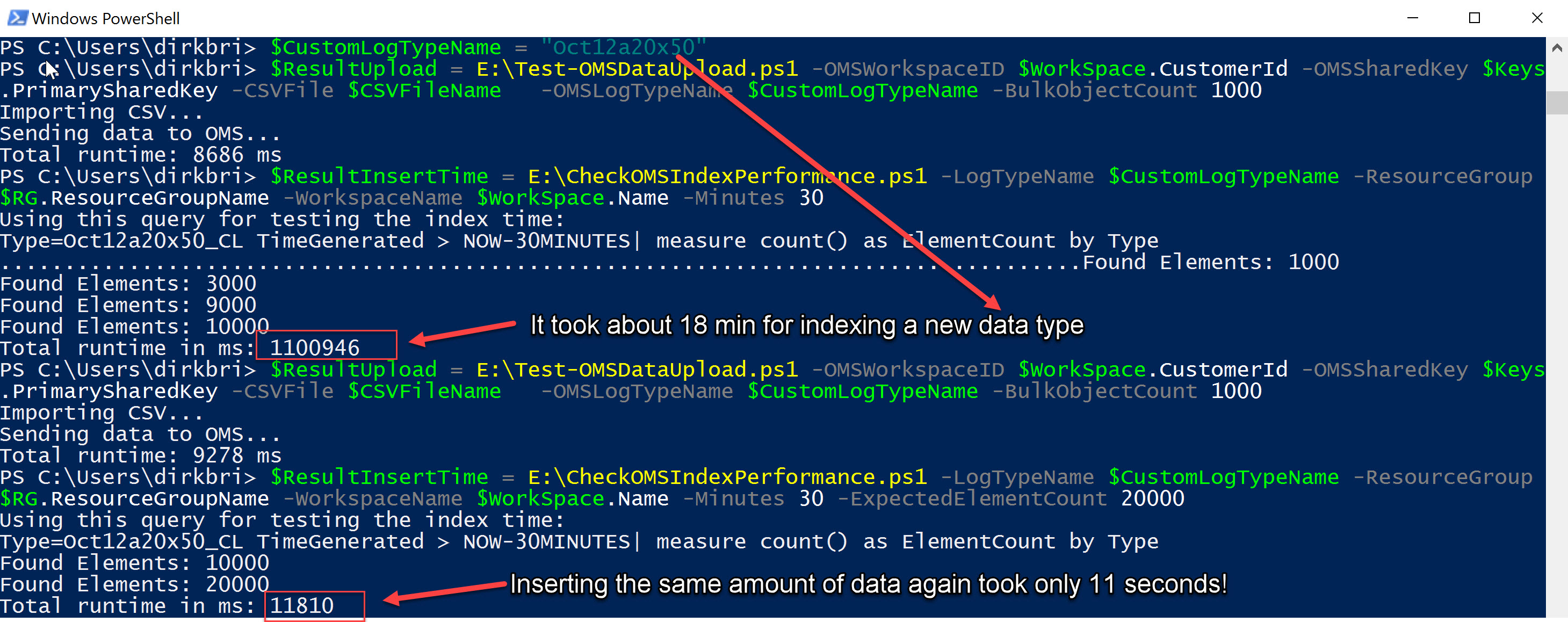
As you can see, OMS needs some time to index a new data type. As soon as the new data type is known to OMS indexing works much faster.
The last picture shows all previous steps tied together:
- Creating a new ResourceGroup
- Creating a new OMS workspace via JSON template
- Uploading CSV files to the newly created OMS workspace in bulk (1000 elements per request)
- Querying the workspace for the newly inserted data and measuring the time it takes to come up
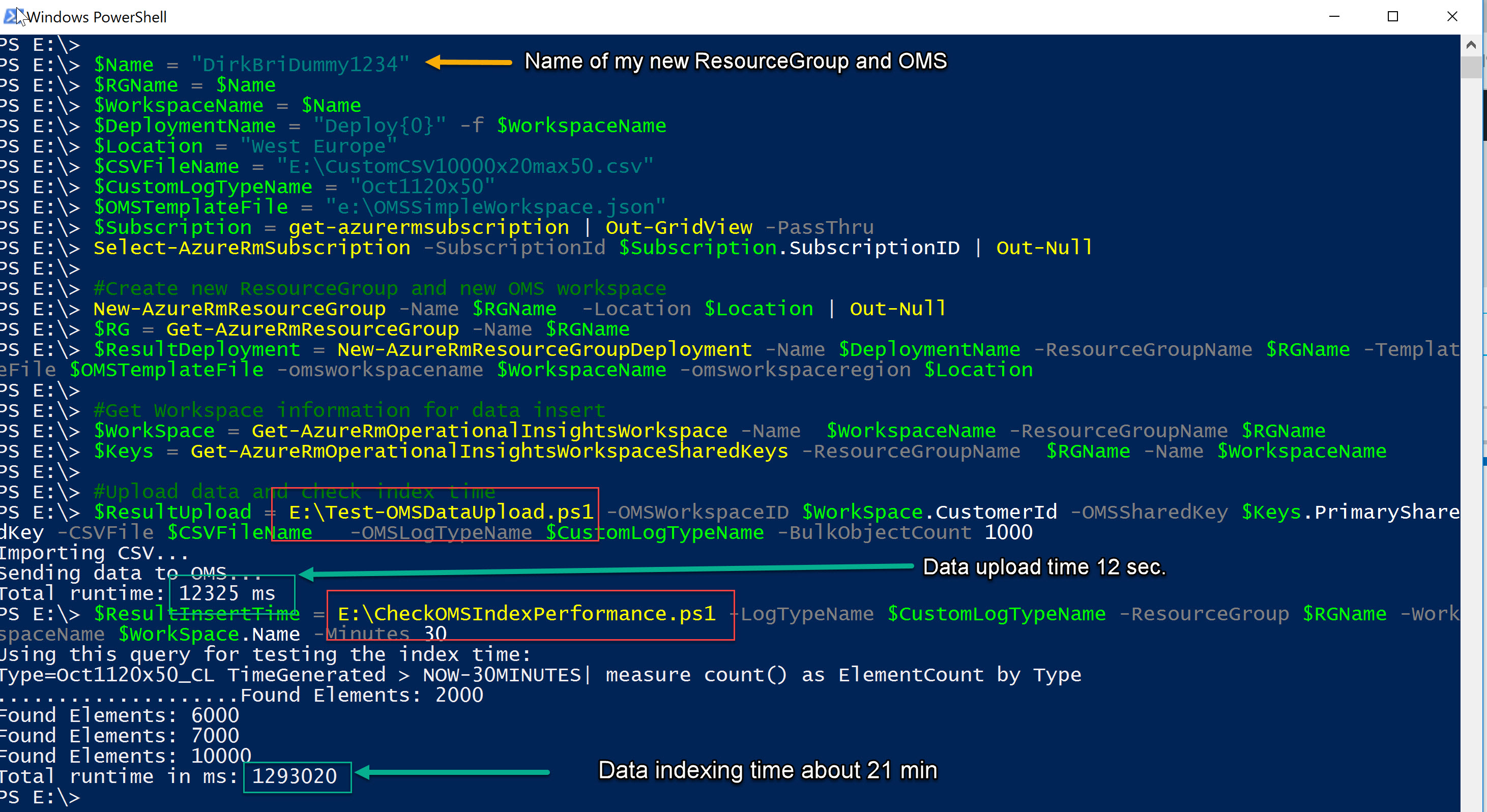
It took about 21 minutes to have the complete data fully indexed and searchable in OMS.
In case you don't trust my PowerShell screenshots :) here is the final check directly in the OMS portal if there are really 10.000 custom log elements available:
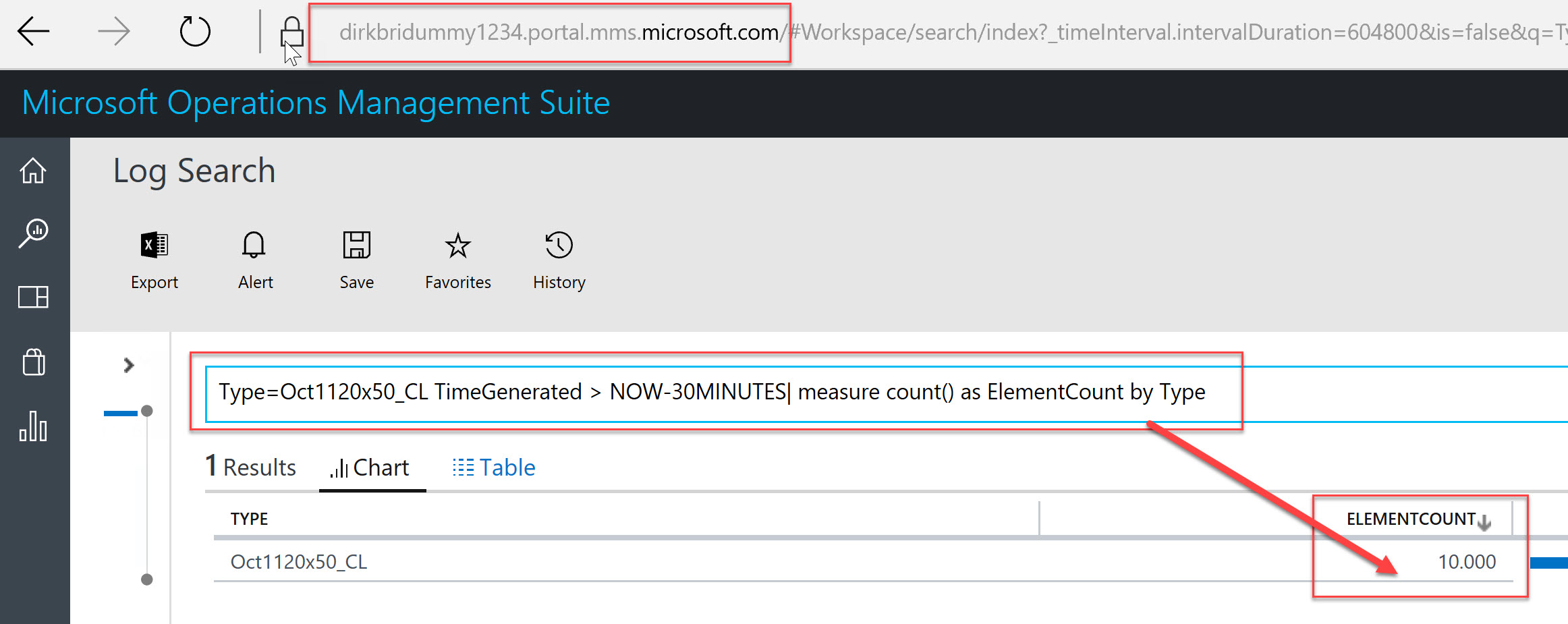
Verifying data usage
To verify how much space the uploaded data will consume in Log Analytics (and therfore of course get billed to our account), we can take advantage of the "Usage" type records in OMS (thank's to my colleague Daniel Müller for pointing me to that). These records are getting created hourly per ingested data type and can be quite useful:
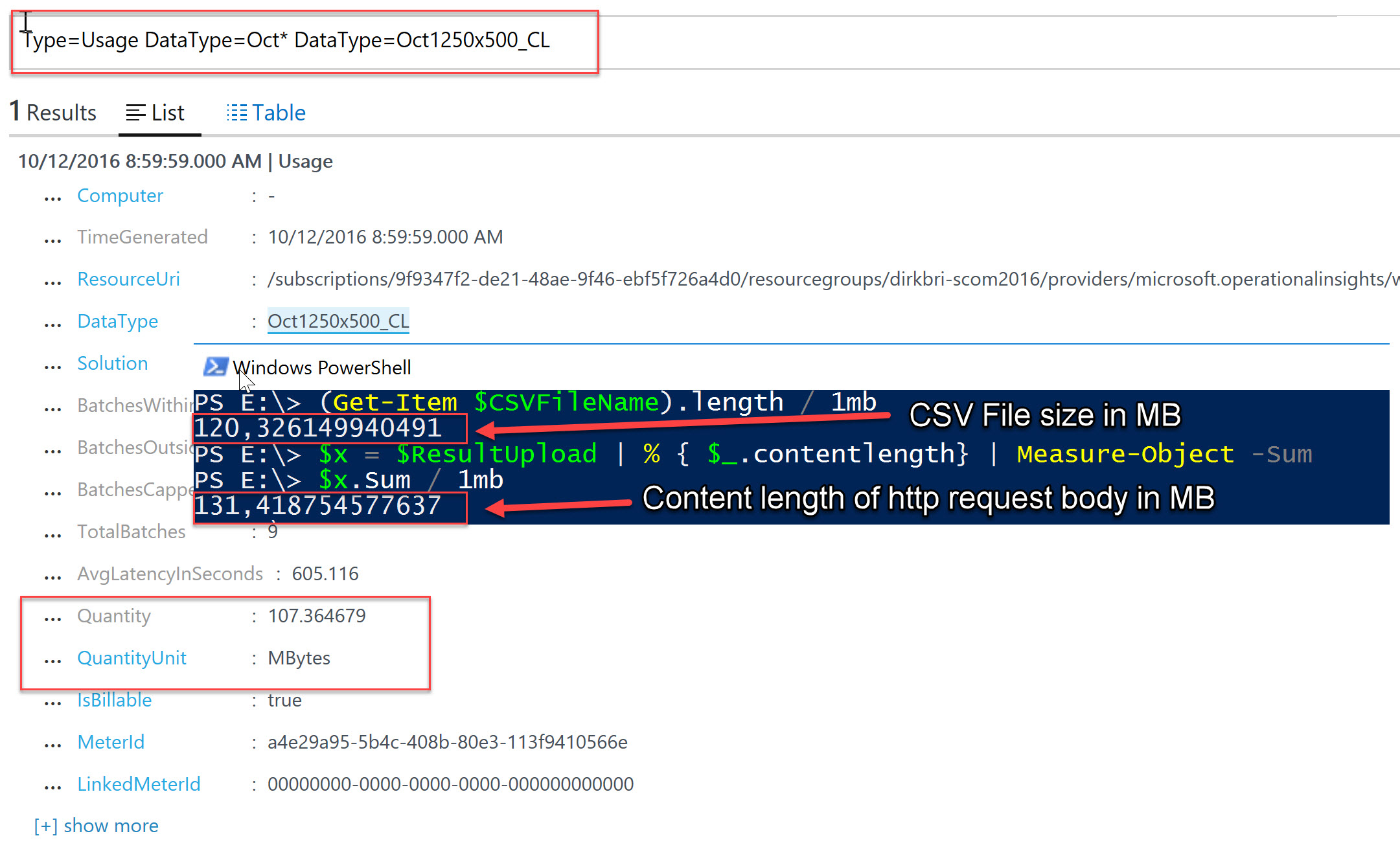
In this example you can see, that uploading the ~ 120MB CSV file caused ~ 107MB of used data space in OMS. That means not only no kind of overhead but in fact a data size reduction when uploading data to OMS!
Test on your own
You can test and play with the http data upload API on your own. My sample scripts are not production ready and rather quick and dirty but might give you some valuable ideas to create your own solutions.
You can download the scripts here: OMSDataUploadTest
- new-csvdata
This function creates custom csv data files with any amount of elements, columns and column width - Test-OMSDataUpload.ps1
This script will upload any CSV files to OMS by using the http API. - CheckOMSIndexPerformance.ps1
This script will query and OMS workspace for a certain amount of custom log data.