Implementing a Skip List in C
I'm dedicating this post to a new data structure. That is the SkipList. This is an intriguing data structure with many benefits. In addition, I've decided to implement this data structure in C. Before I go about explaining the data structure itself I want to explain what drove me to implement it in C. I've been programming for the majority of my career in C++. In this blog, I've written most of my posts in C++ and have praised the language as being the best tool for almost any task. However, I decided that in this instance I want to go back to the basics. I wanted to prove to myself that I can still design a C library with the proper abstractions while leveraging the best software engineering methodologies. I wanted also to remember how it feels to program without the comfort of the C++ type system, C++ Templates, Object Oriented Programming etc... Hence, this post is going to be divided into two parts: The first will discuss Skip Lists, and the second will dwell into how to design a library in C. I hope you enjoy this post as much as I enjoyed writing this code.
The entire code can be found on my Github: https://github.com/guyalster/SkipList
SKIP LIST, so what is it all about?
A skip list is a dynamic and randomized data structure that allows storing keys in a sorted fashion. The skip list is in essence, a linked list with multiple levels. Each level is itself a linked list and with pointers from the upper levels to the lower levels. The thing that is special about this data structure is that its expected runtime for all operations (insertion, deletion, searching) is O(Log(N)). So how is this runtime achieved? Well, that's a result of the randomness of the skip list and how it is built. But before we talk about how we achieve this runtime lets first answer a more fundamental question. Why do we even need it? We already have binary search trees which are great data structures for storing sorted keys (and values) and achieving a logarithmic runtime when they are balanced. In fact, they are deterministic in behavior and have a guaranteed logarithmic runtime (rather than an expected one). The answer to this question will motivate us to continue this quest.
First, implementing a balanced binary search tree can be a very tricky business. Anyone who has tried to implement an AVL/RB tree has seen the complications. On the other hand, as I'll show later in this post, implementing a skip list is much easier. But there is one more important advantage to skip lists over their tree counterparts. That is synchronization. Locking in skip lists can be done in a much more efficient way than in trees, but most importantly, synchronization in skip lists can be implemented without any locking at all while guaranteeing consistency. However, this is a subject that I will not get into in this post as it is also very complicated and requires much more insight and depth. However, mentioning this is crucial to justify why this data structure is so important.
How to build a skip list:
So now we come to the juicy part. How to build a skip list. Well, the best analogy to a skip list I've heard came from an MIT Data Structures & Algorithms class. There the lecturer explained skip lists in terms of the NYC subway system. The NYC subways have multiple lines which go in the same direction. However, one of them passes through every station on its way to the destination, while others pass through some of the stations. The express line passes through the least amount of stations. If you want to get from station A to M, the best strategy is to take the express train from station A directly to station F. Then take the next train from F to J that also stop at stations H and I. Then take the slowest train from I to M that stops at every station. This, of course, is a better strategy than taking the slowest train from A to M that stops in all stations on its way. This is the same idea of how a skip list works and where it derives its efficiency from. So let's examine how we build the skip list from the ground up. We start with the lowest level (that is the slowest train lane), we then toss a coin, and if its "heads" we insert the element in the next upper level. We continue to do this until we draw "tail". The actual way the skip list will be implemented is slightly different but in essence, is the same as I just described. The idea is that when we want to insert a new node to the skip list, we first generate a number between 0 to MAX_SKIP_LEVELS (which is a constant defined by the user). This number will determine in how many levels this new node will appear. Inserting the new node starts from the topmost level that is equal to the random level we generated (the express lane) and we move to the right in that lane until we reach a node that has a key that is greater than our new node. That will be our insertion point. From that point, we continuously insert our node while adjusting the "next" pointers until and including the last level (e.g. level 0). Searching of an existing key will be done in a similar fashion: We'll start from the topmost level of the skip list, going right (using the next pointer) until we hit a node with a key >= our key. We then go down to the next level until we reach the topmost level that contains our node. As you can see from these, the runtime of insertion, searching, and deletion is proportional to the number of nodes we have in each level. What is the expected number of nodes we have in the level i? It is easy to see based on the random process that it will be about half of the nodes that appear in the previous (bottom) layer. This should sound familiar at this point. We notice that in essence. a skip list resembles very much a balanced binary search tree. The main difference is that a key appears in the parent as well as in the child nodes all the way down to the leafs. Using this intuition, we can now see why those operations of the skip list are expected to be O(Log(N)) where N is the number of elements stored in the list.
Skip List Data Structure and APIs:
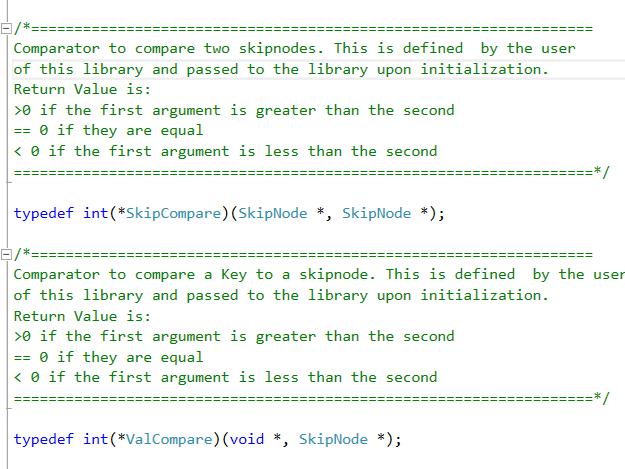
In GitHub all of the above are located in the SkipList.h
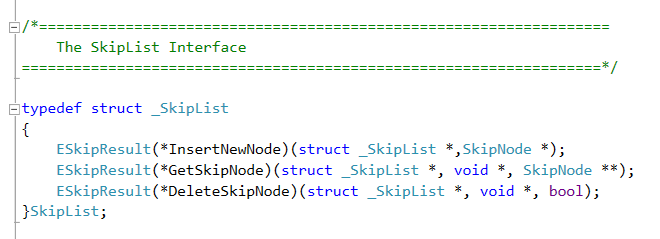
At the top, we have the definition of a SkipNode. The SkipNode has only two fields: the current level of that node and a pointer to pointers to other SkipNodes. The pointer to pointers can be viewed as a dynamic array of lists. This array represents all the levels that this node participates in. This seems strange at first. How many different pointers will the array contain? This of it like this: Image Node N1 with key K1, appears in 10 Levels. Imagine that Node N2 with key k2 is greater than k1 and appears in 5 levels while Node N3 with key k3 which is also greater than k1 appears in 11 levels. N1's array will have the first 5 pointers in its array pointing to N2 and the next 5 pointers pointing to N3.
Let's assume that we're looking for N2 in the SkipList. When we reach level 10 we'll get to N1 which is less than N2. we will see that at level 10 through 6 it points to N3 which is greater than N2, so we'll go down in the levels until we reach level 5, where we'll find N2 as the next pointer of N1 and return it.
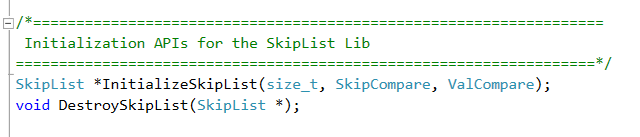
The next definition is of a SkipList structure. Notice that this structure contains only three function pointers. This structure is the C equivalent of a C++ interface with pure virtual functions. Who will implement this interface? That will be a structure that is defined in SkipList.c. The reason it is defined in the .c file rather than in the .h file is for encapsulation purposes. How does the user of the library get a pointer to the SkipList interface? This is done using the initialization function defined just below the structure. But there is something interesting about that function (InitializeSkipList). Notice that it accepts three parameters: size_t - This is the maximal number of levels. SkipCompare - This is a type of a function pointer defined above and which receives two skip lists and returns the larger of them. ValCompare - a function pointer which accepts a pointer to a key (void*) and a skipNode* and returns if that key is greater than the key in that SkipNode.
So, it is the responsibility of the user to tell the library how to compare the values in the SkipNode by providing the comparators to the library upon initialization. But wait a minute! that's weird! Shouldn't the library know itself how to compare these Nodes ? after all, the nodes are defined here. But if you'll take a closer look, you'll notice how none of the structures defined above contain keys and values. In fact, they are very stripped down. So where are the keys and the values that are supposed to be stored inside each SkipNode? That is the trick here. This is a design decision I made when I wrote this library. If I were to write this code in C++, I would use templates to define the SkipNode in a generic way that is independent of the key type it operates on. But in C I don't have that luxury. In C the only way for me to create generic types is by defining them as void *. Instead of doing that, I decided to take a different approach. I decided to adopt the approach that is often used in operating system kernels, which is to have the data structure be embedded inside the main user structure. That is, instead of having the SkipNode contain the user's types, the user will hold a SkipNode inside his/hers structures.
For example:

But how will this work? Since the library only operates on SkipNodes, how will we be able to get the containing structure?
This is a critical piece of the puzzle. in the SkipList.h file you will find a macro defined as:
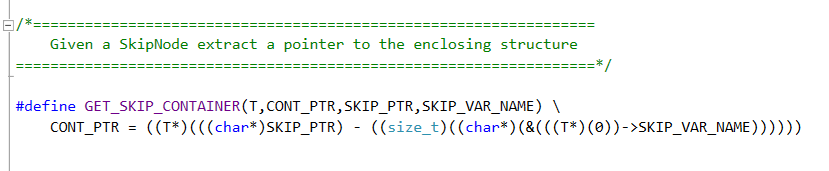 This Macro is not simple to understand so I suggest examining it carefully to see what it does. However, I will mention that it uses the relative location of the SkipNode variable inside the enclosing structure to get the address of the enclosing structure. This is a worthwhile trick to master by itself.
This Macro is not simple to understand so I suggest examining it carefully to see what it does. However, I will mention that it uses the relative location of the SkipNode variable inside the enclosing structure to get the address of the enclosing structure. This is a worthwhile trick to master by itself.
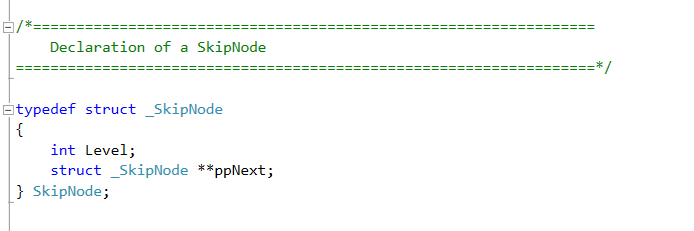
So far we have seen the structures that are exposed to the users of the library. But as you probably noticed none of them contain the metadata to manage the skiplist. Furthermore, ideally, we would like to have a sentinel node which does not contain any keys or values but is used to get access to the rest of the skip list. This sentinel structure is defined in the .C file (again for the purposes of encapsulation).