Non-Recursive Postorder Tree Traversal Without Additional Data Structures.
I would like to show today code to a problem that seems to be trivial at first, but turns out to be not trivial at all. In fact, I haven't been able to find any equivalent solution anywhere yet (but I'm still looking). I would like to present code that prints the values of a binary tree in a postorder fashion, without recursion.... and most interestingly, without any additional data structures. If you look in the internet on solutions to this problem you will find that all the solutions use a stack to keep track of the visited nodes. However, in the solution I will present to you I won't use a stack at all.
Before we talk about how to do this, lets remind ourselves of what a postorder traversal is. A postorder traversal traverses the tree in the following fashion:
Left subtree -> Right subtree -> Root.
Now, before we go about devising the algorithm for a postorder traversal without recursion and without any data structures, lets think how we can solve a simpler problem. Lets try to do the same but with an inorder traversal (e.g. Left subtree->Root->Right subtree).
Since we can't use any additional data structures, we must use the tree's internal structure to keep track of where we are and how we visit each node. For this problem there is a very elegant solution that I will present now, and that you can easily find on the internet. Notice that once we are done traversing the Left subtree we need to jump back to the Root, but since we are not using any additional data structures we need to make sure that we have a way to get back to the Root node. I will first present the code, and then explain it.
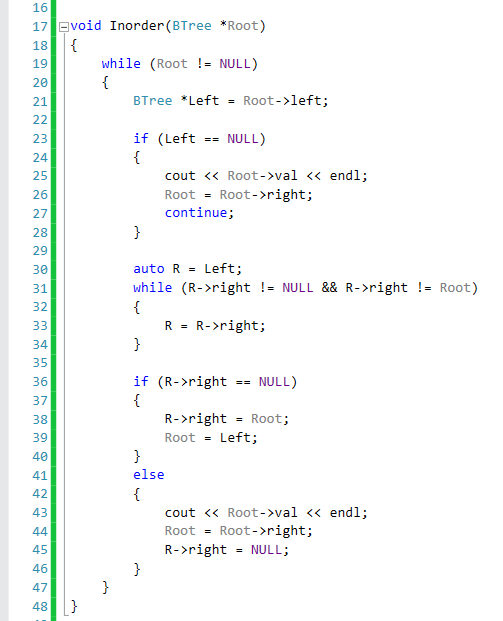
The algorithm runs in a loop so long as Root is not NULL. The first thing we do is get a pointer to the left child of Root. if that child is NULL, we need to print Root's value and move to the right child of Root (by making Root = Root->right). Left is the the left child of Root. Now comes the interesting part. We look at the right subtree of Left and we take the path all the way to the right. The node that will be used as the right most node of Left is R. In line 31 we run in a loop so long as R->right is not NULL (hence we need to go more to the right) or R is not equal to Root. At first the second part of this condition seems weird, but it will soon be all clear. At first, you may assume that R will not be equal to Root and so the loop in line 31 ends when R->right is equal to NULL. When that loops end, we check again to see on which of the conditions we stopped. The first time we stop because R->right is NULL. what we do is that we make R->right point back to Root. This is the most critical part of the algorithm, because this is how we are able to get back to Root after we finished traversing the left subtree. Once R->right is set to point to Root, we set Root to be equal to Left and continue the loop. Since we are going to be doing this continuously on every iteration, at some point we will reach back that node that was pointed to by R. Root will be equal to that node at that point. We will then realize that Root->left is NULL, print that node and then take the right path (as in line 26). Where will we end up when we take that right path ? well, obviously because we pre-set the right path of that node to point back up to the Root of the tree, we will end up there. Root will point once again to the original root of the tree. Now here is where things get interesting again. Left will again point to the left subtree of the original Root of the tree and R will now traverse the right subtree of Left as before. However, this time the condition in line 31 will stop due to the fact that R->right will be equal to Root. We will end up in else clause at line 41. In this case what do we know? We know that we have just completed traversing the left subtree of the original tree, and that we need to print the Root and move to the right subtree. That is exactly what lines 43 - 45 do. However, in addition, they also clean up the "mess" we created, by setting R->right to be NULL again. This is fine, because after this point we will no longer be traversing this subtree again. Root will be set to Root->right and we will do everything we did all over again, but this time to the right subtree. Notice that the algorithm will end after Root points to the right most node in the right most subtree. If you find this to be a little tricky, I suggest going over the code, and playing on a paper with a "tree" of your own, so that you can convince yourself that this works.
We are now ready to see how to do a postorder traversal in a similar fashion. However, I must warn you that the postorder traversal, although similar in principle, is still more complicated. We'll understand why soon. Before that, lets ask ourselves what was it about the above solution that helped us reach our goal ? The answer is that by setting the rightmost node of the left subtree to point to the Root we achieved a way to get back to the root of the original tree. This also served as a "marker" for us that we completed traversing the left subtree and that it is time to print Root's value and move on to the right subtree. A key observation is that once we set Root to point to Root->right we no longer need to traverse Root again and we only focus on the right subtree. In other words, we forget about Root and move on.
When we do postorder traversal however, things are much more complicated. This is because Root gets printed last. We can't just forget about it and move to another subtree. Once we are done traversing the left subtree we need to traverse the right subtree and only at the end we print Roots value. This fact is what causes the solution above to break if we try to apply it in similar fashion to the postorder case. However, let's not despair. We can still use the above solution, with some modifications. But, the devil is in the details, so pay close attention. Again, I will present first the code, and explain it in detail afterward.
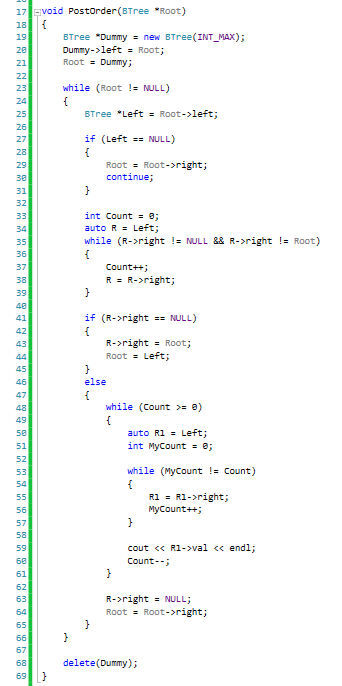
Ok, this code is much longer. But the structure should look familiar. You will immediately notice that in the first lines I create a dummy node named "Dummy" and make Root be its left subtree. The reason I do this is because without it I will not have a way to get back to Root (the original root of the tree) after I complete traversing the right subtree. By adding this dummy node, I'm turning Root into a left subtree of another tree, and based on our previous solution we already saw that getting from a left subtree back to the root of a tree is simple, by using a back pointer. Once we have set Root to be the left subtree of the dummy node, we set Root to point to the dummy node (in line 21). At this point we start our loop. We have Left point again to the left subtree of Root. If Left is NULL, we need to move to the right subtree (without printing Root). Otherwise, we do the traversal of the right subtree of Left in lines 35 - 39 just as we did in the inorder traversal. Notice that we also count the levels we traverse on the right path. This count will be used later on when we revisit this subtree again. On the first time and just as in the inorder case R->right will be NULL at some point (no back pointer). We will end up in lines 43-44. In those lines we will set the back pointer up to Root and set Root to be Left. So far, nothing fancy at all. The fun part comes after we complete traversing the entire left subtree and we end up with Root pointing to what was pointed to by R (with the back pointer). Root->left will be NULL and so we'll set Root to be Root->right. However, Root->right is our back pointer that will lead us back to our original Root of the original tree (in this case it will be the dummy node). So now, we have Root pointing to the dummy node again. Again, we have Left pointing to the left subtree (which is in this case the original tree we were supposed to traverse) and we start taking the right path using R in lines 35-39. However, this time the loop will terminate because R->right will be equal to Root (or Dummy if you will). Lets stop for a second and think what does it mean ? what it means is that we completed traversing the Left subtree (of the left subtree of Dummy) and we still haven't completed the right subtree (of the left subtree of dummy). But this is where things really get tricky. We have to print the right subtree in a bottom-up fashion, starting from R going up all the way to Left. This is where "Count" from lines 33 and 37 comes to play. When we reach the point that we realize that R->right is equal to Root (line 46) we loop so long as Count >= 0. For each Count we continuously go down the right path from Left but each time stopping one level above the level we were in the previous loop. When we stop we print the value of that node and continue looping. Once we are done with this loop we can clean up the "mess" just as we did in the inorder case, and move to the right. Notice that since Dummy has only a left subtree, moving to the right means we essentially end the traversal and break from the main loop in line 23. The last thing we do just before exiting is to delete Dummy.
That's it. A little long, and slightly tedious, but hopefully you were able to keep up and get the gist of it.