Radix Sort - sorting has never been so fun
Today I'll discuss Radix Sort. The reason I chose to write about Radix Sort is that despite the fact that I learnt it in the past, unlike other sorting algorithms such as Merge Sort and Quick Sort I was never able to remember how it worked and what were its advantages. Recently I decided to relearn it, and after going over it, I realized that it was so intuitive that there is no reason not to be able to remember it and utilize it when needed.
So what is Radix Sort? Well, lets first define what Radix Sort isn't. Radix Sort isn't a comparison based algorithm. That means that in Radix Sort we don't compare elements of a set to other elements of the set to find their relative location compared to each other. This means, that the O(nlog(n)) lower bounds that has been proven for comparison based algorithms such as Merge Sort, Quick Sort ,and Heap Sort does not apply to Radix Sort. We will get to the run time analysis of Radix Sort later on, but first lets define the problem.
Let S be a set of numbers such that the maximum number of digits of any given number in S is K when representing the numbers in radix R. We need to return the numbers in S sorted.
Obviously we can default to sorting S using conventional sorting algorithms that we mentioned above. However, we would be missing out on the key property here which is that the maximum number of digits of any number is K. We will try to devise the sorting algorithm using the inductive approach that I showed in one of my previous posts. But what should we do the induction on ? We can always pick N - the number of elements in S. That is usually the way to go with inductions, except that using N as our main parameter will cause us again to miss out on the key property here. Hence, we will use K as our inductive parameter:
P(k < K) - (strong induction) Given a set S that holds the property above, we know how to order the numbers in S based on their k < K least significant digits.
Notice that I didn't use the word "sort" but rather order. The reason is, that the numbers are not going to necessarily be sorted. More specifically, the numbers with more than k digits are not going to be sorted.
P(1) - This is the simplest and trivial case. There is actually nothing to do here.
We need to find P(K) - which will order the numbers based on all the K least significant digits and hence return to us the numbers of the set sorted.
How do we reduce P(K) to P(k < K) ? We'll start by first ignoring the K'th most significant digit of the numbers.We can then apply our hypothesis to all the numbers looking only at their k < K least significant digits. Based on the inductive hypothesis, we know how to order them with respect to those digits. So what's next ? Lets stop for a second and observe what we have:
1. All the numbers that had originally less than K digits are now in their correct place compared to each other (from the hypothesis).
2. Some of the numbers that have K digits either share the same K'th MSD, in which case they are ordered correctly relative to each other (because their k < K MSD's have been used in the hypothesis) or have different K'th MDS's in which case they are not ordered correctly with respect to each other. However, for those that have different K'th MSDs, merely comparing their K'th digit can put them in their correct spot with respect to each other.
3. Since we are in radix R (for some R) we only have R choices for the K'th digit. For example for R = 10 the K'th digit can only be numbers 0 through 9.
After applying the hypothesis,the next step in our algorithms is to take the newly ordered set of numbers and order them based on the K'th digit. Based on our third observation, we can group the numbers into at most R buckets. We'll traverse the set and each number will be put in one of the R buckets. If multiple numbers fall into the same bucket (meaning that they share the same K'th MSD) we can put them in that bucket in the same order as they appear in the set. Based on our second observation, by doing so we are still maintaining their relative order. We then traverse the buckets from lowest to highest and output the numbers in the order they appear in each of these buckets. There we have it: Radix Sort!
Before we continue to look at the code, lets quickly analyze the run time of the algorithm: for each k <= K we traverse the set and split it into R buckets after which we recreate the set by traversing the buckets as mentioned above. Since each traversal is O(n), the entire algorithm runs in O(Kn). For K << n, we have O(n) - a linear time sorting algorithm.
Now lets code it up:
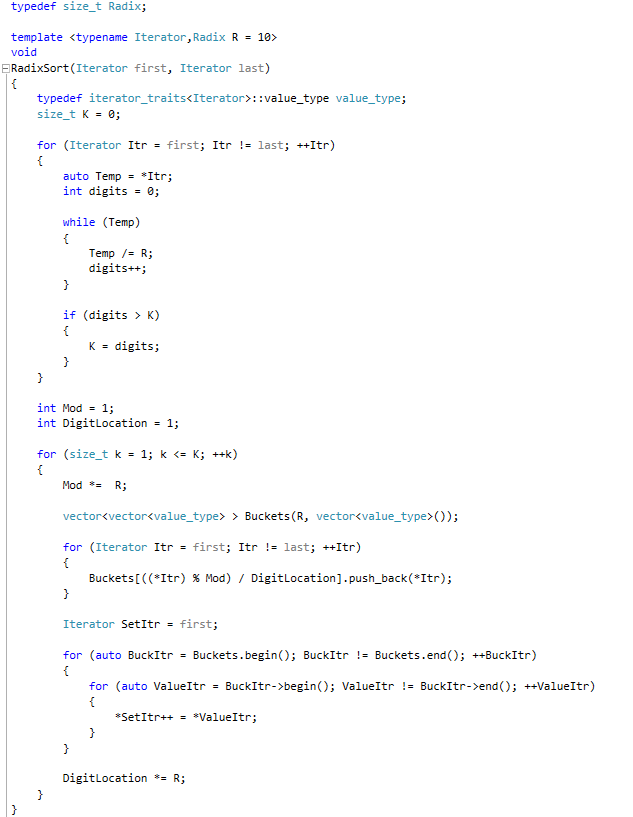
Lets examine the code. First, notice that the code uses generic programming best practices. That is, we use a generic iterator type to access the unsorted elements and modify the the data structure.We also pass the radix as a template parameter to the algorithm. One might ask, why not pass the Radix as an argument to the sorting procedure ? The difference is more of a statement. With the radix being a template argument rather than a procedure argument, we are encoding the radix in the sort procedure DNA if you will.In essence, for every radix there will be a new RadixSort procedure that will be created. Hence, when the procedure is invoked we already know what the radix is. The first portion of the code (the first loop) calculates K - the maximum number of digits in radix R. Next, as we discussed before we iterate over all k's <= K and bucketize the numbers using only the k'th least significant digit. The last two loops iterate over the buckets (and internally within each bucket) to recreate the Set in an ordered fashion (based on the k < K least significant digits). After the K'th iteration the numbers are ordered based on all their K digits making the set S sorted. That is Radix Sort. Simple and intuitive.