An inductive approach to algorithms design
I've recently bought the book: Introduction to Algorithms - a Creative approach by Udi Manber.
I've read many Algorithms books throughout the years including the famous "Introduction to Algorithms" aka CLRS, as well as other algorithm books that are more language oriented.
This book is by far one of the most mind changing books I've read.
I would actually encourage reading it after you read the other books, in order to gain the most out of it.
When you look at typical algorithms books and if you've taken undergrad/grad courses in algorithms and data structures,
the way they teach you to design an algorithm usually follows a template of the form:
1. Describe the problem to be solved.
2. Show several trivial instances of the problem.
3. Describe the algorithm that solves the problem.
4. Prove that the algorithm actually solves the problem.
If you're as impatient as I am, you most likely dedicated your time to understanding steps 1 through 3 and dedicated much less time to step 4.
Cause who really cares about the proof of correctness right ?
This author's approach to algorithm design as he conveys it in the book, is different.
His approach is:
1. Describe the problem.
2. Show some trivial instances of the problem.
3. Try to prove that the problem is solvable - through the usage of an analogy to mathematical induction.
4. Using the insights gained from step 3, devise the actual algorithm and describe it.
See the difference ? instead of spoon feeding the reader with the algorithm, he shows the reader how to devise it himself by applying mathematical logic and techniques to it.
The Algorithm details are less important here. What is important is the ability to convince yourself that you understand how the problem can be solved.
In this case, the author extensively uses mathematical induction as the means of breaking the problem into smaller problems and getting insights from them as to the solution to the main problem.
When you think about it, this is exactly the way we should all be solving problems in computer science.
We should describe the problem in a concise manner (e.g. using formal notations) and then try to think of it in terms of subsets of smaller instances of this problem,
building the solution in a bottom up fashion.
Of course, it is much easier said than done. Many of the problems that he shows are non trivial at all and require a lot of thinking to them. However, for me the major gain out of this book is the thought process which the author tries to convey:
1. Let P(N) be the problem to be solved in terms of say its input of size N.
2. Show how you can solve it for input of size 1 (e.g. P(1) )
3. Assume that you have a solution for P(N- 1) or perhaps for P(n <N) depending on the type of induction you want to use.
4. Show how you can solve P(N) in terms of P(N - 1) or P(n < N).
5. if you weren't able to show, strengthen your hypothesis in 3 by modifying or adding constrains and repeat 4.
6. Devise an algorithm that utilizes the concepts from 3 & 4.
I'll show how this can be done for several problems that are not necessarily mentioned in this book.
(See the details of this problem in the hyper-link).
Let P(N,W) be the problem of trying to make change for the amount W using denominations {D1,D2,... DN} for any N with minimum amount of coins.
1. the base case is when W = 0. In this case C(W) - the minimum coins to be used is 0. If there is no amount to make change for there is no cost.
2. Lets assume that we know how to solve P(N, w < W) for smaller values of w (notice that we are using strong induction here) and that we have a
corresponding associated C(w) for this.
3. How can we decrease our original problem to a smaller size ?
A. lets assume that we pick one of the denominations Di to be used in our solution. We are now left with W - Di amount to make change for. So we are left with solving P(W - Di) which based on our hypothesis returns to us it's corresponding C(W-Di) minimal cost.
B. all we have to do now is take that minimal cost and add to it 1 for the Di coin that we used.
4. However we need to find a global minimum and not a local one. Hence we need to go over all the coin denominations and for each one of them calculate C(W-Di).
In addition we maintain a global minimum over all C(W-Di).
5. our result will be the global minimum.
There you go! a simple, straightforward algorithm to solve the problem. Lets see the code:
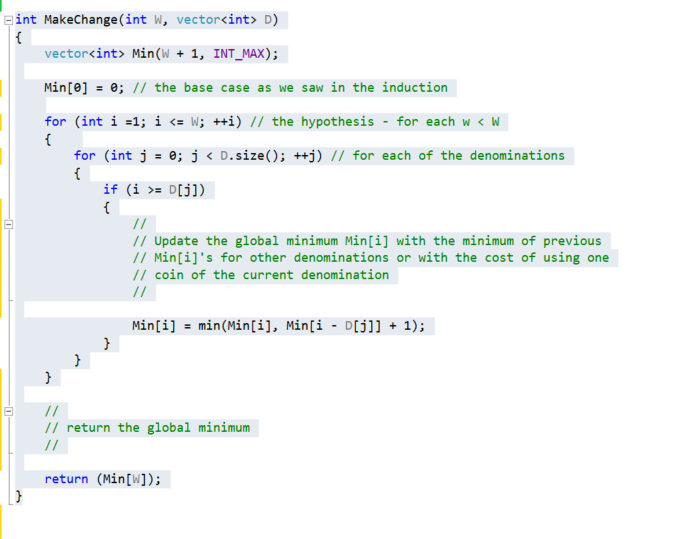
The runtime of this solution is O(N*W). For W << N we can say that it is O(N).
This solution is of course a classic dynamic programming solution to this problem, and in fact problems that can easily be formulized in terms of induction lend
themselves neatly to dynamic programming solutions.
I would like to show yet another example now. One which is less trivial but also lends itself nicely into this old/new paradigm of thinking.
The Jump Game
In this problem we are given an array A of non negative integers each of which indicates the maximum steps that can be taken from the current index to other
indexes.
We are asked to answer if we can reach the last element of the array by a sequence of jumps starting at the first index.
For example: A[5] = {1,2,2,0,1} will return true, however A[5] = {1,2,0,0,1} will return false.
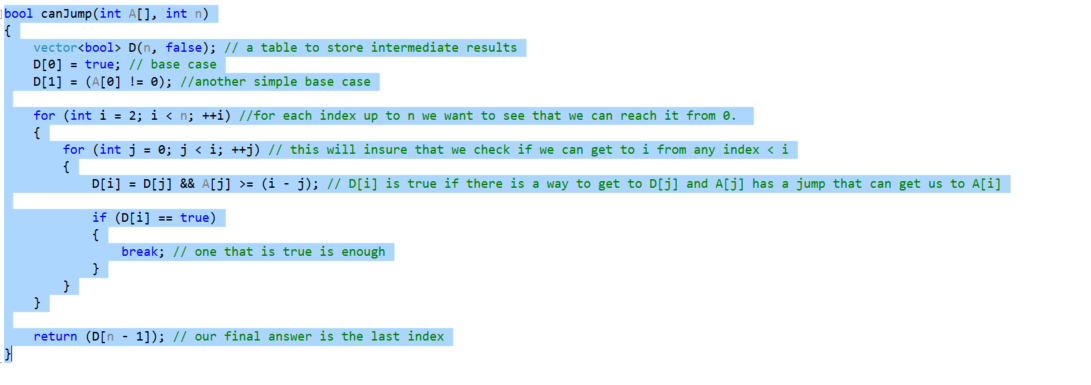
1. Let P(N) be the problem of determining if there exists a set of jumps from 0 to index N.
2. Base Case P(0) - we can solve this easily P(0) is always true for whatever value A[0] is.
3. P(n < N) lets assume that we can solve this problem for indices less than N.
assume J is such a sequence of jumps: J = { J0,Ji,Jk,...,Jn} of size n < N if we have J all we need to verify is that A[Jn] >= A[N]. If this holds we are done.
unfortunately we'll have to consider all sequences until we find one that meets our requirements or we can determine that non of them lead us to A[N].
This brings us to our algorithm:
bool canJump(int A[], int n)
{
vector<bool> D(n, false); // a table to store intermediate results
D[0] = true; // base case
D[1] = (A[0] != 0); //another simple base case
for (int i = 2; i < n; ++i) //for each index up to n we want to see that we can reach it from 0.
{
for (int j = 0; j < i; ++j) // this will insure that we check if we can get to i from any index < i
{
D[i] = D[j] && A[j] >= (i - j); // D[i] is true if there is a way to get to D[j] and A[j] has a jump that can get us to A[i]
if (D[i] == true)
{
break; // one that is true is enough
}
}
}
return (D[n - 1]); // our final answer is the last index
}
Finding the median of a stream of numbers at any given time
This is a problem that a certain company in Mountain View CA, particularly likes to ask its candidates during interviews.
The problem asks that given an infinite stream of numbers, we output at any given time the median of these numbers.
As a quick refresh: If we were to take the stream and sort it in non decreasing order, the median would be the number that is greater than floor(N/2) numbers
and smaller than floor(N/2) numbers. what this means is that for odd N - the median is the middle element in the sorted sequence, for even N it is the average of the
two middle elements.
As usual lets define our problem using formal notation:
1. P(N) - The problem of finding the median for a sequence of N numbers.
2. P(1) - base case: trivial. The median is just the number we encountered.
3. P(N - 1) - lets assume that we can find the median for a stream of N - 1 numbers.
What happens when we receive the N'th number ? Can we figure out the median based on it and the previous median ?
lets imagine the following stream of size 3: 9 1 5, The median here is 5. If Nth number = 10 then the median will be (5 + 9)/2 but if the Nth number = -4 the median
will be (1 + 5) /2.
So what we see is that our hypothesis is not strong enough. We need to strengthen it so that we can make the move from N - 1 to N smoothly.
What do we need to know in order to make that move ?
if N is larger than our current median, then our median increases and if N is smaller than our median decreases. But how can we determine it.
We can observe that what is really required is to know the numbers that precede the current median and the number that follow the current median such that at any
given time we can know the highest number out of the preceding ones and the lowest
number out of the following ones.
When the N'th number arrives we can use it to either update the list of preceding numbers or following numbers (based on whether it is smaller or larger than the
median) and then use the largest of those lists to find the new median, or if they are equal we
use both of them.
Lets take a look at an example:
Sn - 1 = {5,1,2,9,-1,7} the median is 3.5 the preceding list consists of {-1,1,2} and the following list {5,7,9}. when 10 arrives, since it is larger than the median we put
it in the following list {5,7,9,10}. the new median is 5.
what happens if we get 12. well the list becomes {5,7,9,10,12}. Notice that in this case our lists are not balanced (the preceding is of size 3 and the following list is
of size 5).
What does that mean ? in essence it means that our median is moving to the right.
we should rebalance the lists such that the absolute value of the difference in their sizes is <= 1. So, for this case we'll get - {-1,1,2,5} {7,9,10,12} and the new
median is 6.
One key observation here is that we'd like to access to the two lists such that 5 and 7 are the easiest to access so that we can calculate the median quickly and not
have to go through the lists each time.
So now lets strengthen our hypothesis:
P(N - 1) = We can get the median of N - 1 numbers as well as two sorted lists representing the values preceding that median and following that median such that the lists sizes differ from each other by at most 1.
Brilliant! our P(N) will only have to do the steps that we described before and return the new median as well as the two balanced lists including the N'th number.
Now its time for the algorithm itself. All we have to do is follow our hypothesis and the extra move to P(N). The only detail left to figure out is how to represent the
two lists in an efficient manner.
The best Data structure that comes to mind is a binary heap. We can use two binary heaps to store the two lists. One will be a max heap for the preceding list and
one a min heap for the following list.
This way, the root of the max heap will be the number immediately preceding the median and the root of the min heap will be the number immediately following the
median.
Lets see the code:
struct MinComp
{
bool operator()(const int & i1, const int &i2)
{
return (i1 > i2);
}
};
void PrintLongestMedian(vector<int>& Stream)
{
vector<int> MaxHeap;
vector<int> MinHeap;
int CurrMedian = INT_MIN;
for (auto N : Stream)
{
if (N > CurrMedian)
{
MinHeap.push_back(N);
push_heap(MinHeap.begin(), MinHeap.end(), MinComp());
}
else
{
MaxHeap.push_back(N);
push_heap(MaxHeap.begin(), MaxHeap.end());
}
if (MinHeap.size() > MaxHeap.size() && MinHeap.size() - MaxHeap.size() > 1)
{
int move = MinHeap[0];
pop_heap(MinHeap.begin(), MinHeap.end(), MinComp());
MinHeap.pop_back();
MaxHeap.push_back(move);
push_heap(MaxHeap.begin(), MaxHeap.end());
}
else if (MaxHeap.size() > MinHeap.size() && MaxHeap.size() - MinHeap.size() > 1)
{
int move = MaxHeap[0];
pop_heap(MaxHeap.begin(), MaxHeap.end());
MaxHeap.pop_back();
MinHeap.push_back(move);
push_heap(MinHeap.begin(), MinHeap.end(),MinComp());
}
if (MinHeap.empty() == false && MinHeap.size() == MaxHeap.size())
{
CurrMedian = (MinHeap[0] + MaxHeap[0]) / 2;
}
else if (MinHeap.size() > MaxHeap.size())
{
CurrMedian = MinHeap[0];
}
else
{
CurrMedian = MaxHeap[0];
}
cout << "N: " << N << " The Current median is: " << CurrMedian << endl;}
}
}
int main()
{
vector<int> Stream = { 10, 4, 12, 20, 15, 3, -9, 10, 2, -8, 13 };
PrintLongestMedian(Stream);
}
We have seen thus far three different problems that use induction as the means of finding the algorithm to solve them.
This technique not only produces an algorithm, but we also get the proof of correctness for free.
Some might claim that the three examples here are only toy problems, and this technique might not be suitable for more complicated, industry oriented problems.
As the last example, I'd like to tell you my own experience with this.
I recently had to present to my team a relatively complicated algorithm that I created for a feature I was working on.
I didn't have a lot of time to prepare the presentation, and so I decided to adopt the technique I presented here as a way to show my peers what the algorithm does.
From my point of view, it was a great success for the following reasons:
1. I was able to create a cohesive and concise presentation in a relatively short time.
2. Through this I was able to verify that my initial assumptions of my design were correct and I was handling all the cases properly.
3. I was able to articulate things in a way that removed any ambiguities: My peers all understood what I was talking about, and I could hear through their questions that things were clear to them.
For me this was a proof that you can use this technique in a broader sense than what I thought of initially.
By continuously practicing solving problems in this way, you force your brain to start thinking like this on every problem you encounter.
By no means am I saying that every problem is suitable for this technique, and it is left to your own judgment to decide when it can be applied and when not.
So to conclude, I would urge everyone to read this book. I would also urge anyone who's interested to practice this technique by solving toy problems and seeing
how it varies from problem to problem.
If anyone reads a book that they feel is mind changing, in the same way that I felt about this book, please leave me a comment here and I'll surely read it.
{kind=link}