Microsoft Azure Databricks
Lors de l'évènement Datavore 2018 à Montréal, j'ai participé à l'animation d'un atelier sur Azure Databricks. Cet article reprend les différentes étapes de l'atelier que j'ai délivré.
Présentation d'Azure Databricks
Azure Databricks est une plateforme collaborative de données massives et d'apprentissage automatique, qui s'adapte automatiquement à vos besoins. Ce nouveau service Azure consiste en une plateforme d'analyse basée sur Apache Spark et optimisée pour la plateforme de services infonuagiques Azure. Azure Databricks comprend l'ensemble des technologies et des fonctionnalités libres de mise en grappe d'Apache Spark. En outre, grâce à notre nouvelle solution, vous serez en mesure de gérer facilement et en toute sécurité des charges de travail telles que l'intelligence artificielle, l'analyse prédictive ou l'analyse en temps réel.
Atelier
Cet atelier est constitué de 2 grandes parties
Partie 1 : configuration de l'environnement Azure
Partie 2 : utilisation de Databricks
- Atelier : Data Engineering avec Databricks
Partie 1 : configuration de l'environnement Azure
Création d'un groupe de ressources
Un groupe de ressources est un groupement logique de vos ressources Azure afin d'en faciliter la gestion. Toutes les ressources Azure doivent appartenir à un groupe de ressources.
Portail Azure : https://portal.azure.com
Depuis le portail Azure, cliquez sur « Resource groups » puis sur le bouton « Add »
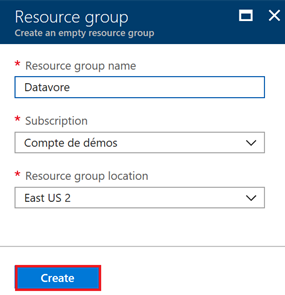
Renseignez les informations de votre groupe de ressources.
Pour ce laboratoire, choisissez la région « East US 2 ». Cliquez sur le bouton « Create »
Une fois le groupe de ressources créé, une notification apparait en haut à droite de l'écran. Cliquez sur « Go to resource group ».
Votre groupe de ressources est créé et prêt à être utilisé.
Création d'un compte de stockage
Un compte de stockage Azure est un service cloud qui fournit un stockage hautement disponible, sécurisé, durable, évolutif et redondant. Le stockage Azure se compose du stockage d'objets blob, du stockage de fichiers et du stockage de files d'attente. Pour notre laboratoire, nous allons utiliser le stockage d'objets blob. Pour plus d'informations sur le stockage Azure, vous pouvez consulter cet article : /fr-fr/azure/storage/
Pour comprendre un peu le concept, un compte de stockage peut contenir un ou plusieurs containeurs qui eux-mêmes vont contenir les blobs (dossiers et fichiers)
Le compte de stockage peut être crée de la même manière que le groupe de ressources, via le portail. Mais il est possible aussi d'utiliser le « Cloud shell » intégré au portail. C'est ce que nous allons faire ci-dessous.
En haut du portail Azure, cliquez sur l'icône « Cloud shell ».

Le « Cloud shell » va s'ouvrir en bas de l'écran. Cliquez sur « Bash (Linux) »
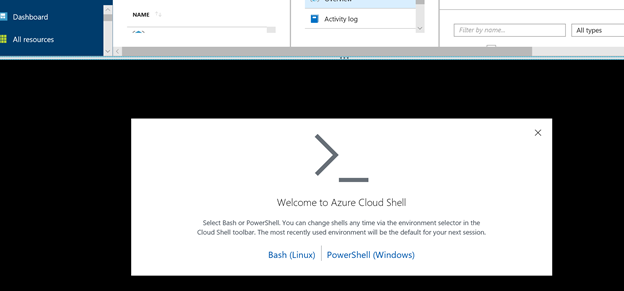
Si c'est la première fois que vous exécutez le « Cloud shell », la fenêtre suivante va apparaître. Choisissez votre abonnement Azure, puis cliquez sur « Create storage ».
Une fois paramétré, le « Cloud shell » est prêt à être utilisé.
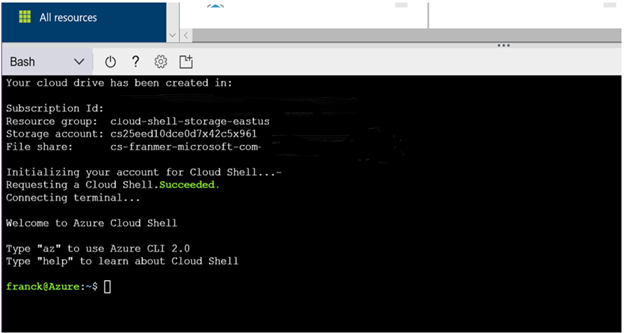
La création d'un compte de stockage peut se faire avec la commande suivante :
az storage account create --name <yourStorageAccount> --resource-group <yourResourceGroup> --location eastus2 --sku Standard_LRS
Dans le cas de cet exemple, voici la ligne de commande correspondante :
az storage account create --name datavorestorage --resource-group datavore --location eastus2 --sku Standard_LRS
Au bout de quelques secondes le compte de stockage est créé. Cliquez sur le bouton « refresh »de votre groupe de ressources. Votre compte de stockage doit alors apparaître.
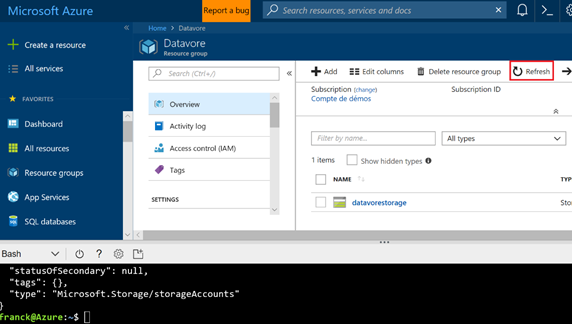
Si vous cliquez sur votre compte de stockage, vous accéderez alors aux différentes fonctions et propriétés du compte de stockage. Notamment pour retrouver les informations de connexions en cliquant sur « Access Key ».
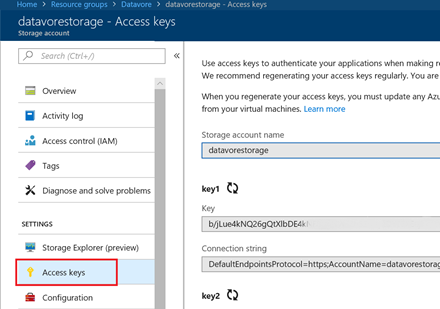
Maintenant que le compte de stockage est disponible, nous allons créer les containeurs pour y stocker nos différents fichiers.
Avant de pouvoir créer les containeurs, il faut pouvoir accéder au compte de stockage. Pour cela, il faut récupérer les clefs d'accès au compte. Ci-dessous une commande permettant de récupérer les clefs.
az storage account keys list --account-name <yourStorageAccount > --resource-group <yourResourceGroup> --output table
Dans notre exemple, voici la commande utilisée
az storage account keys list --account-name datavorestorage --resource-group datavore --output table
Copiez une des 2 clefs puis exportez les informations de votre compte de stockage
export AZURE_STORAGE_ACCOUNT="<YourStorageAccount>"
export AZURE_STORAGE_ACCESS_KEY="<YourKey>"
Voici les lignes de commande concernant notre laboratoire
export AZURE_STORAGE_ACCOUNT="datavorestorage"
export AZURE_STORAGE_ACCESS_KEY=" yqwBdGRgCW0LWdEuRwGdnxKPit+zXNrrVOxXQy57wq6oHmCSy2NnoA3Pr9E4pMgJPwcVeg8uQt1Uzk5YAWntiw=="
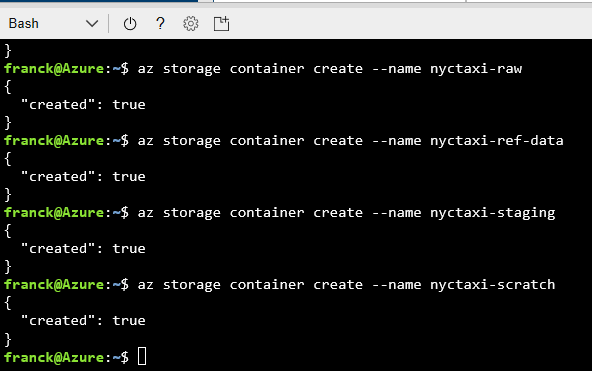
Création des containeurs
az storage container create --name nyctaxi-consumption
az storage container create --name nyctaxi-curated
az storage container create --name nyctaxi-demo
az storage container create --name nyctaxi-raw
az storage container create --name nyctaxi-ref-data
az storage container create --name nyctaxi-staging
az storage container create --name nyctaxi-scratch
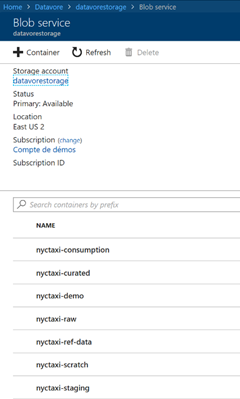
Pour vérifier la création de vos containers, depuis le portail Azure, cliquez sur votre stockage Azure
Dans la vue « Overview », cliquez sur « Blobs »
Vous devez retrouver les containeurs créés précédemment
Copie des fichiers pour le laboratoire
Données de références
Les fichiers sont stockés sur un de nos comptes de stockage. Ne modifiez surtout pas la clef ci-dessous.
Exécutez ce script dans le « Cloud Shell »
export SRC_STORAGE_ACCOUNT="franmerstore"
export SRC_STORAGE_ACCESS_KEY="eSSFOUVLg4gB3iSxuFVh/lDVoMeQHCqVj67xHdaYcPYoMSUqFuD+E2OeDhY4wRZCEF97nCRGOV0i7WJDyoOd7g=="

Puis la commande suivante :
azcopy --source https://franmerstore.blob.core.windows.net/nyctaxi-staging/reference-data/ --destination https:// <YourStorageAccount>.blob.core.windows.net/nyctaxi-staging/reference-data/ --source-key $SRC_STORAGE_ACCESS_KEY --dest-key $AZURE_STORAGE_ACCESS_KEY --sync-copy ––recursive
Dans notre exemple, voici la commande à exécuter avec le compte de stockage utilisé dans cet exemple :
azcopy --source https://franmerstore.blob.core.windows.net/nyctaxi-staging/reference-data/ --destination https://datavorestorage.blob.core.windows.net/nyctaxi-staging/reference-data/ --source-key $SRC_STORAGE_ACCESS_KEY --dest-key $AZURE_STORAGE_ACCESS_KEY --sync-copy --recursive

Copie des données transactionnelles
Pour ce laboratoire, nous allons prendre juste un sous-ensemble des données. Si vous souhaitez récupérer l'ensemble des données référez-vous à l'index en fin de document (cela prendra au moins 2h).
Pour ce laboratoire, nous allons travailler uniquement sur l'année 2017, mais rien ne vous empêchera par la suite de réexécuter les scripts en changeant simplement l'année
Voici les scripts pour copier les données transactionnelles :
azcopy
--source https://franmerstore.blob.core.windows.net/nyctaxi-staging/transactional-data/year=2017/ --destination https://<YourStorageAccount>.blob.core.windows.net/nyctaxi-staging/transactional-data/year=2017/ --source-key $SRC_STORAGE_ACCESS_KEY --dest-key $AZURE_STORAGE_ACCESS_KEY --sync-copy
--recursive
Dans notre exemple, nous aurons donc :
azcopy
--source https://franmerstore.blob.core.windows.net/nyctaxi-staging/transactional-data/year=2017/ --destination https://datavorestorage.blob.core.windows.net/nyctaxi-staging/transactional-data/year=2017/ --source-key $SRC_STORAGE_ACCESS_KEY --dest-key $AZURE_STORAGE_ACCESS_KEY --sync-copy
--recursive 
Pour vérifier les données, vous pouvez exécuter la commande suivante :
az storage blob list
--container-name nyctaxi-staging --output table 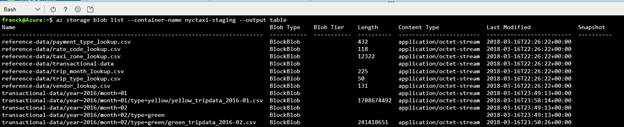
Création d'une base Azure SQL Database
Depuis le portail Azure, cliquez sur « + Create a resource », « Database » puis sur « SQL database »
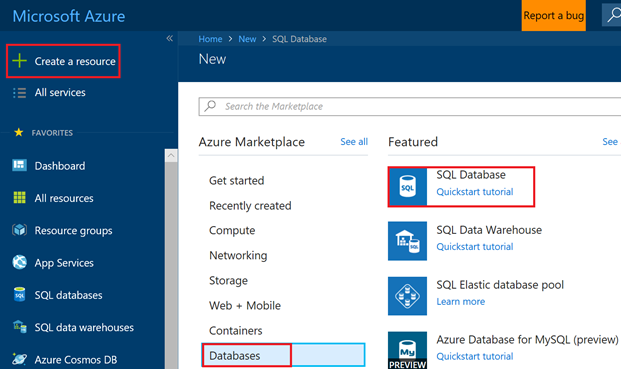
Puis renseignez les valeurs pour votre base de données
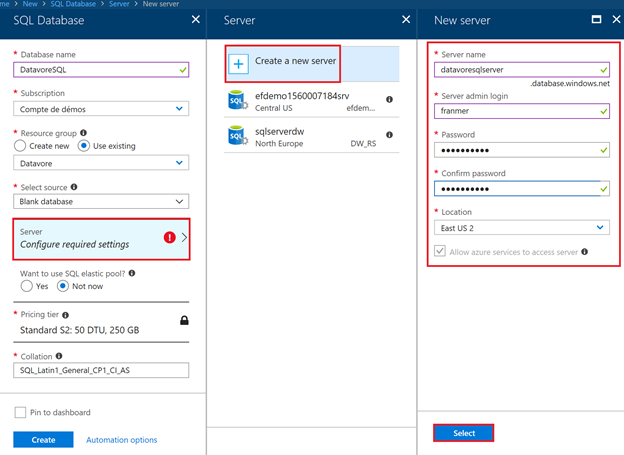
Il se peut que vous soyez obligé de créer un serveur SQL.
Cliquez sur « Configure required settings », « Create a new server ».
Renseignez les informations du server SQL. Souvenez-vous bien du mot de passe !
Cliquez sur « Select ».
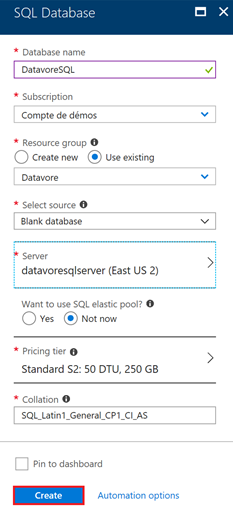
Continuez à renseigner les informations de votre de base de données puis cliquez sur « Create »
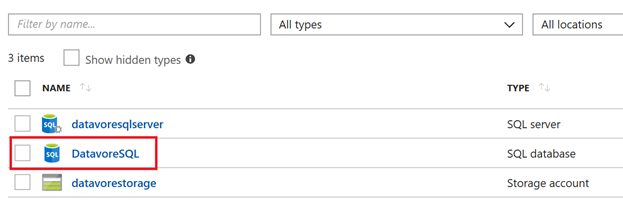
Création des tables SQL
Depuis le portail Azure, cliquez sur votre base de données fraichement créée.
Cliquez sur « Query editor », puis sur « Login »
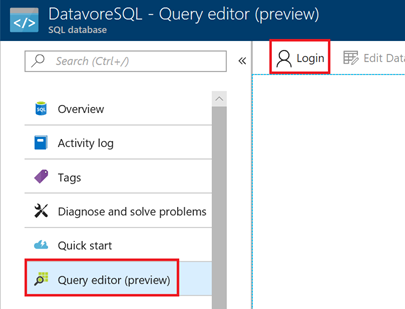
Entrez vos informations de connexion, puis cliquez sur « Ok ».
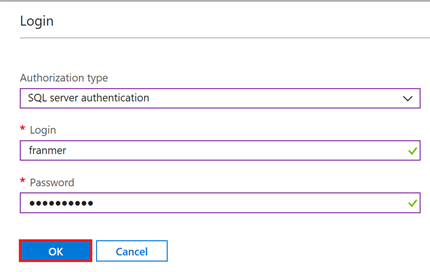
Création des tables
Depuis le portail Azure, copier le script T-SQL ci-dessous dans l'éditeur, puis cliquez sur « Run »
DROP TABLE IF EXISTS TRIPS_BY_YEAR;
CREATE TABLE TRIPS_BY_YEAR (
TAXI_TYPE VARCHAR(10),
TRIP_YEAR INT,
TRIP_COUNT BIGINT
);
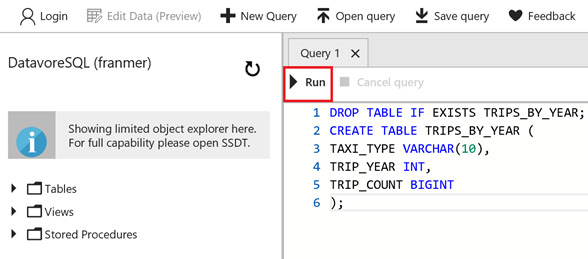
Répétez l'opération pour les 2 tables suivantes
DROP TABLE IF EXISTS TRIPS_BY_HOUR;
CREATE TABLE TRIPS_BY_HOUR (
TAXI_TYPE VARCHAR(10),
TRIP_YEAR INT,
TRIP_HOUR INT,
TRIP_COUNT BIGINT
);
DROP TABLE IF EXISTS BATCH_JOB_HISTORY;
CREATE TABLE BATCH_JOB_HISTORY
(
batch_id int,
batch_step_id int,
batch_step_description varchar(50),
batch_step_status varchar(10),
batch_step_time varchar(25)
);
ALTER TABLE BATCH_JOB_HISTORY
ADD CONSTRAINT batch_step_time_def
DEFAULT CURRENT_TIMESTAMP FOR batch_step_time;
Vous devez voir vos tables depuis le portail Azure
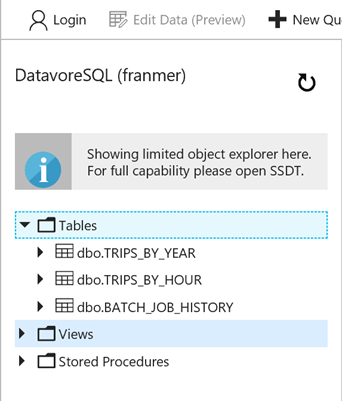
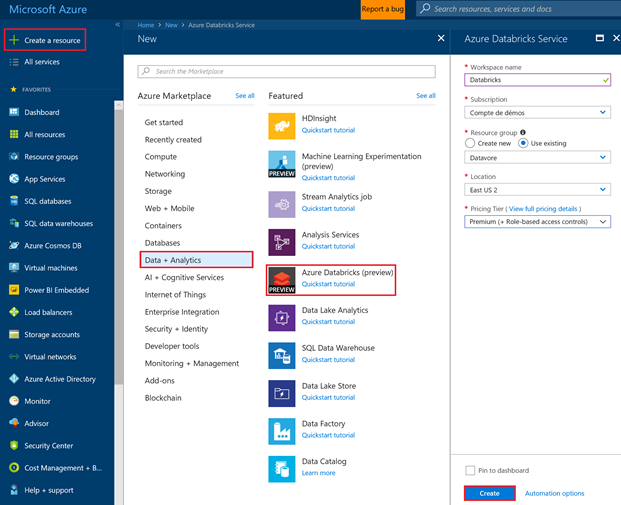
Création d'une ressource Azure Databricks
Depuis le portail Azure, cliquez sur « + Create a resource », « Data + Analytics » puis « Azure Databricks ».
Renseignez les informations de votre « workspace » . Placez le bien dans votre ressource groupe. Sélectionnez la région « East US 2 ».
Cliquez sur « Create ».
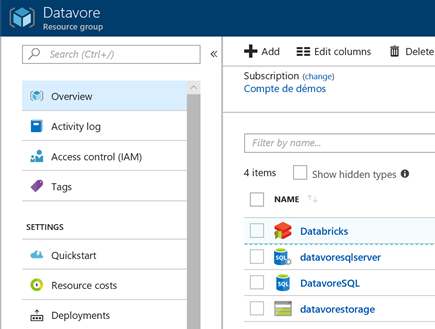
Après la création de votre espace de travail Databricks, votre groupe de ressources doit contenir les ressources suivantes :
Provisionnez un cluster et commencez les analyses
Cliquez sur votre ressource Databricks
Puis sur le bouton « Launch Workspace ».
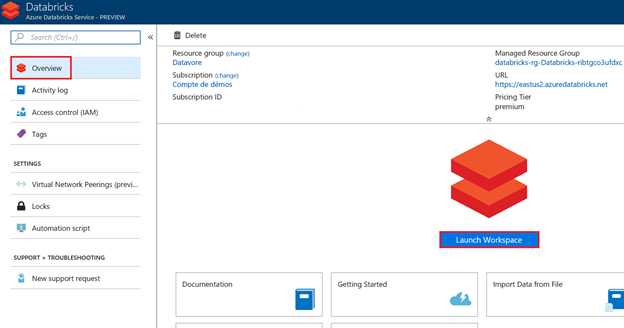
Votre infrastructure Azure est prête. Vous pouvez commencer l'analyse de vos données avec Databricks
Partie 2 : utilisation de Databricks
Atelier : Data Engineering avec Databricks
Création du cluster
Une fois dans l'espace de travail Databricks, sur la gauche, cliquez sur « Clusters », puis sur « Create Cluster »
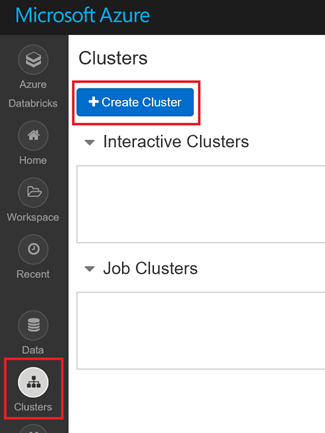
Voici les paramètres du cluster à utiliser :
- Databricks Runtime Version : 4
- Python version : 3
- Worker Type : Standard_DS13_v2
- Spark Config : spark.hadoop.fs.azure.account.key.<yourStorageAccount>.blob.core.windows.net <yourKey>
Ci-dessous l'exemple de configuration pour l'atelier 2. 
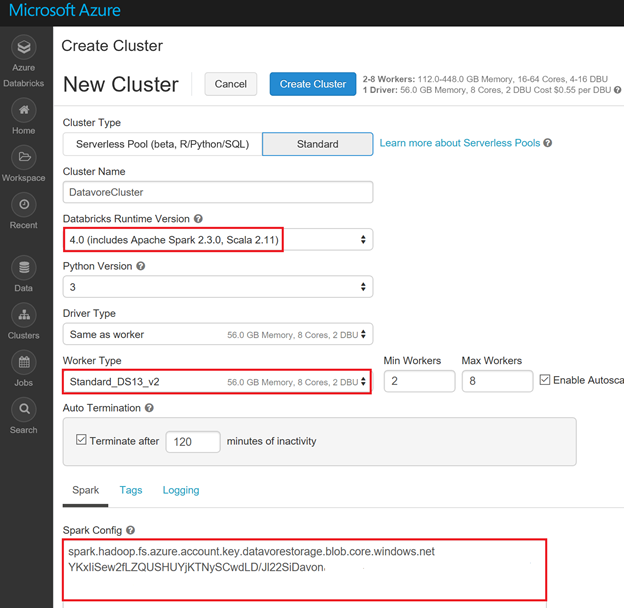
Cliquez sur « Create cluster »
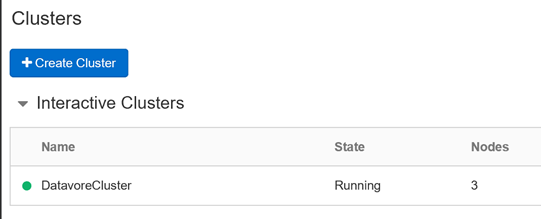
Après quelques minutes, votre cluster est prêt
Notebooks
Sur la gauche de l'écran, cliquez sur « Workspace », puis « Users ».
A droite de votre alias, cliquez sur la flèche puis sur « Import »
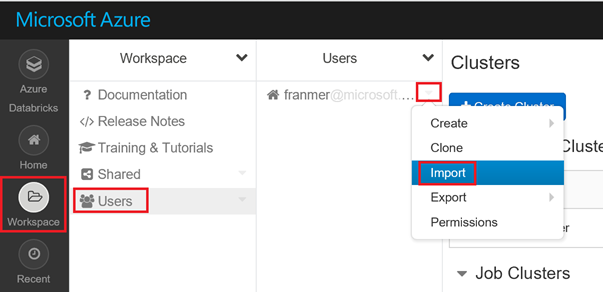
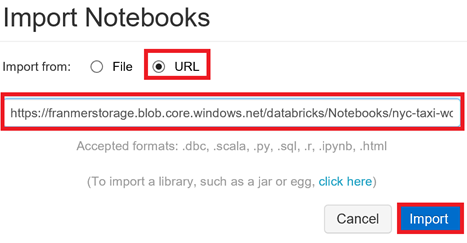
Dans la fenêtre « Import Notebooks », cliquez sur « URL » puis copiez l'adresse ci-dessous
https://franmerstorage.blob.core.windows.net/databricks/Notebooks/nyc-taxi-workshop.dbc
Cliquez sur le bouton « Import »
Les notebooks doivent apparaître dans votre espace de travail.
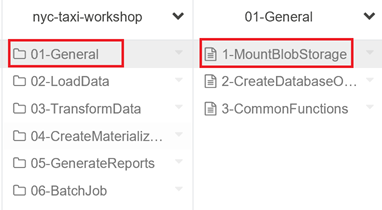
Utiliser un notebook avec un cluster
Avant de pouvoir commencer à utiliser le notebook, il faut attacher ce dernier à un cluster.
Cliquez sur « Detached » puis sélectionnez un cluster.

Configuration des Notebooks
Pensez à renseigner votre compte de stockage
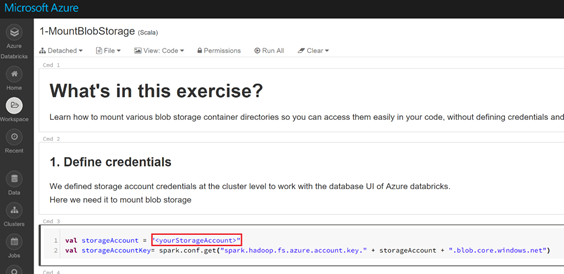
Dans le notebook « 2-CreateDatabaseObjects », renseignez les champs concernant votre base de données Azure.
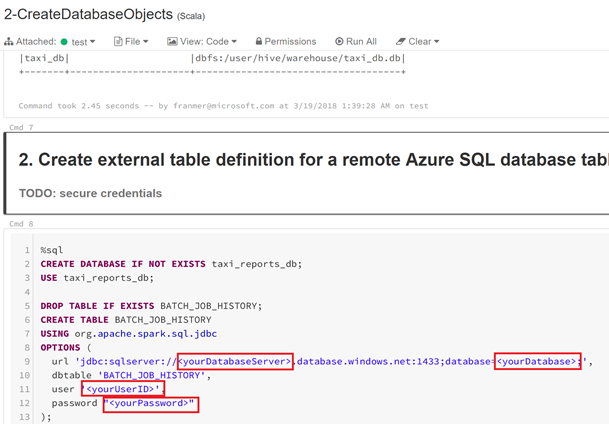
Dans cet exemple nous aurons donc



Cliquez sur le notebook « 1-LoadReferenceData » pour continuer le laboratoire avec Databricks
Durant les ateliers, pour revenir sur votre espace de travail pour changer de notebooks, cliquez sur « Workspace » à gauche de l'écran.
A partir de maintenant, continuez le laboratoire à partir des notebooks. Ci-dessous des conseils pour les différents notebooks de l'atelier.
Certains travaux vont prendre plusieurs minutes. Vous pourrez vérifier l'avancement en cliquant sut les flèches à gauche des travaux.
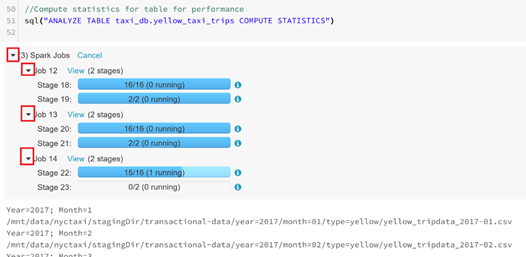
Dans la partie « 05-GenerateReports », dans le notebook « Report-1 », vous y trouverez des exemples de rapports.
Au niveau d'un des rapports, cliquez sur l'icône graphique.
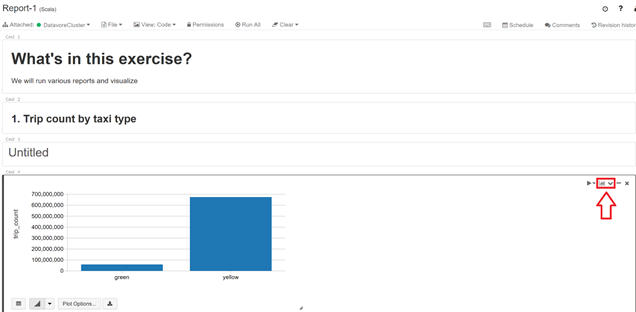
Dans le menu contextuel, cliquez sur « Show Code »
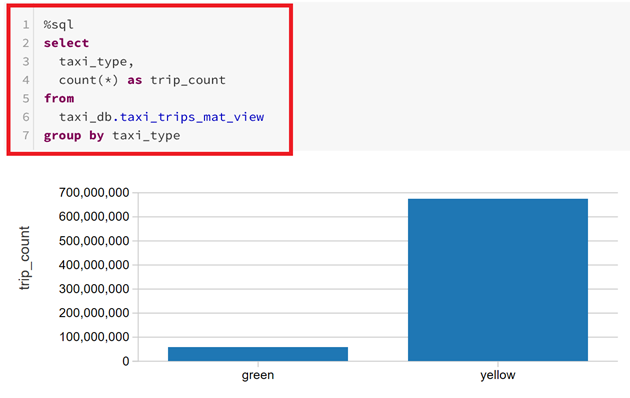
Le script retournant les résultats permettant la création des graphiques s'affichent
Sous le graphique, de nombreuses options sont disponibles pour changer la visualisation de vos données
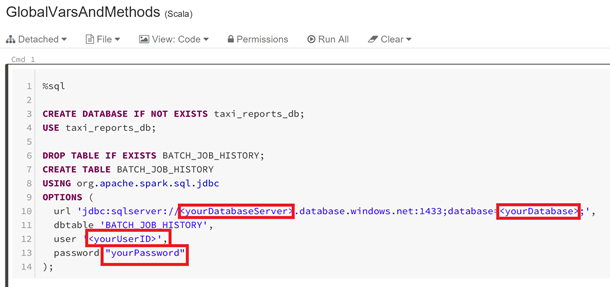
Dans la partie « 06-BatchJob », dans le notebook « GlobalVarsMethods », n'oubliez pas de renseigner les valeurs de votre base Azure SQL
Commande 1
Commande 2

Rapport interactif avec Power BI Desktop
Après avoir fait le dernier notebook du laboratoire, il peut être intéressant de se connecter aux données avec Power BI Desktop.
Depuis Power BI Desktop, cliquez sur « Get Data », « More »
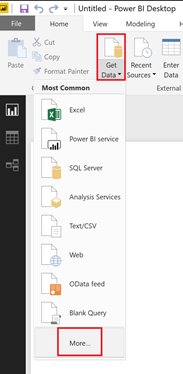
Sélectionnez le connecteur « Spark »
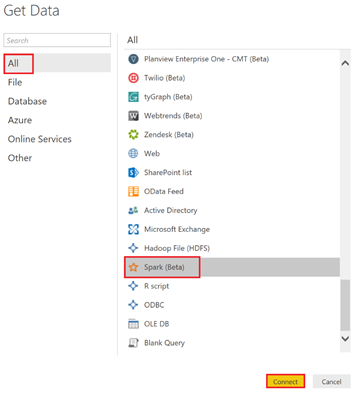
La fenêtre suivante apparaît. Il faut donc fournir les informations de connexions
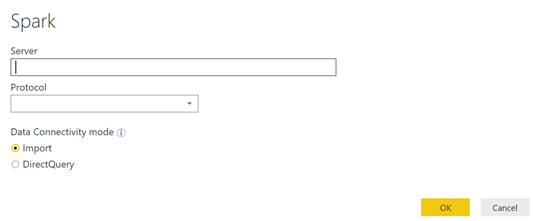
Pour le moment, l'adresse du cluster Databricks n'est pas triviale à trouver. Mais voici comment faire.
Depuis votre espace de travail Databricks, cliquez sur « Clusters », puis sur le nom de votre cluster (« DatavoreCluster » dans notre exemple)
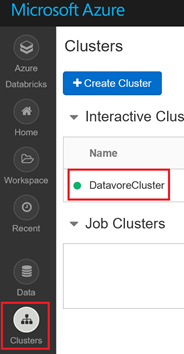
Une fois dans la page de votre cluster, cliquez sur « JDBC/ODBC ».
Dans le champ « JDBC URL », composez l'adresse du server avec les 2 éléments entourés en rouge, et en ajoutant https au début.
Pour notre exemple cela va donner :
https://eastus2.azuredatabricks.net:443/sql/protocolv1/o/1174394268694420/0317-035245-abed504 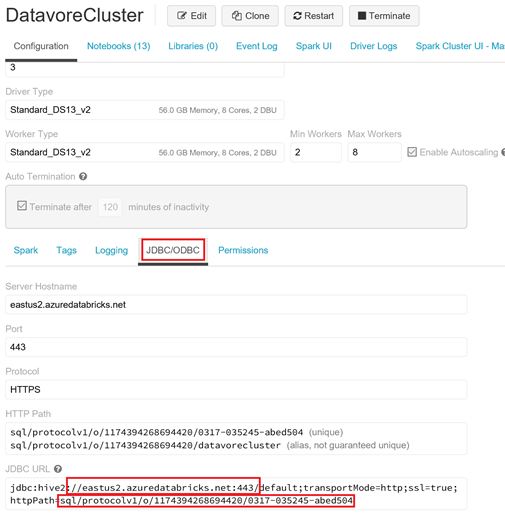
Donc, voici ce que ça donne dans Power BI Desktop. Cliquez sur « Ok »
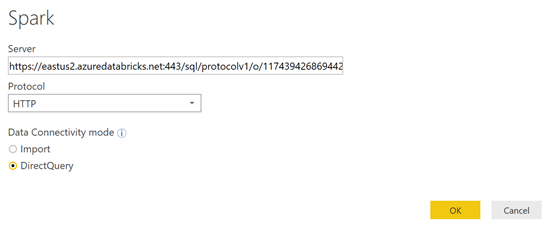
Maintenant, il faut les autorisations .
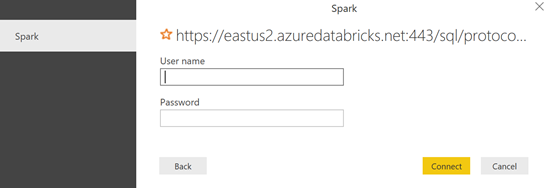
Pour cela, il est nécessaire de générer un jeton d'accès du côté de Databricks.
Dans l'espace de travail de Databricks, cliquez en haut à droite sur l'icône utilisateur, puis sur « User Settings »
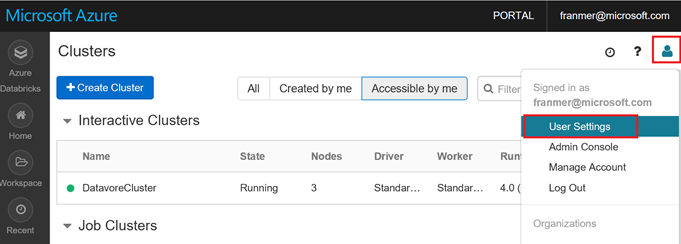
Cliquez sur le bouton « Generate New Token »
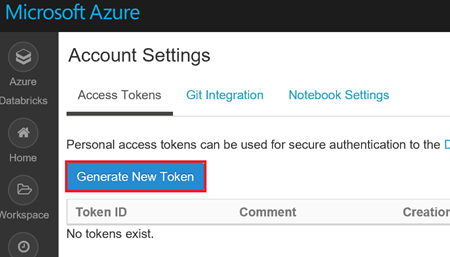
Donner un nom explicite à votre jeton et cliquez sur le bouton « Generate »
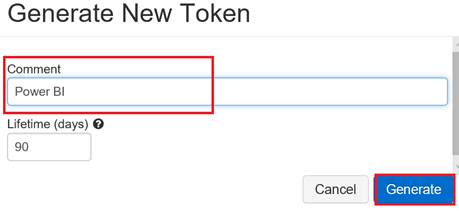
Depuis la fenêtre qui apparaît, copiez et conservez bien ce jeton, car il ne sera plus possible de le récupérer par la suite.
Cliquez sur le bouton « Done ».
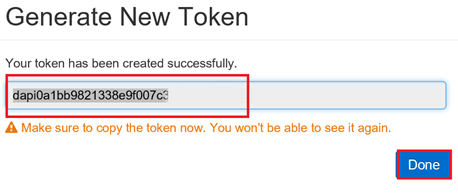
Le jeton est généré !
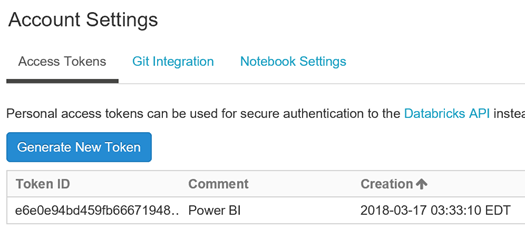
Du côté de Power BI Desktop, copiez le jeton dans le champ « Password », puis utiliser token dans le champ « User Name » (Effectivement, ça ne s'invente pas ).
Cliquez sur le bouton « Connect ».
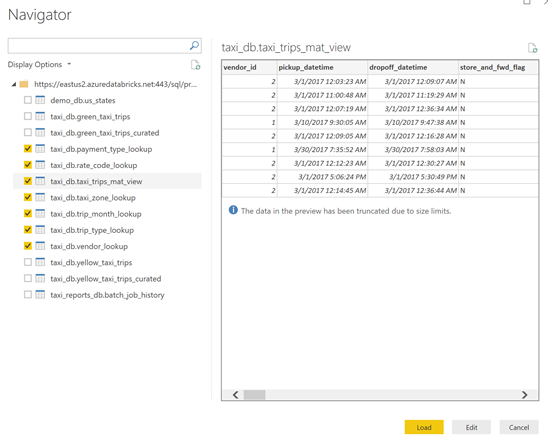
Vous voilà prêt pour explorer vos données. Sélectionnez les tables ci-dessous, puis cliquez sur le bouton « Load »
Une fois les données connectées au rapport, cliquez sur l'icône de liaison qui se trouve sur la gauche.
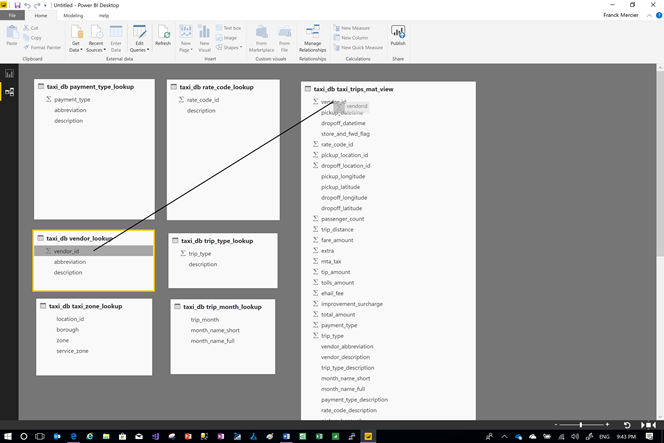
Par un simple glisser-déposer, réaliser les liaisons entre les tables
La fenêtre de liaison apparaît, cliquez sur le bouton « Ok »
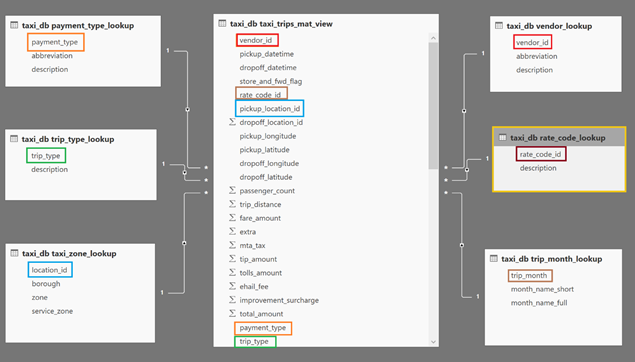
Après avoir effectué toutes les liaisons, voici un exemple de ce que vous pouvez obtenir :
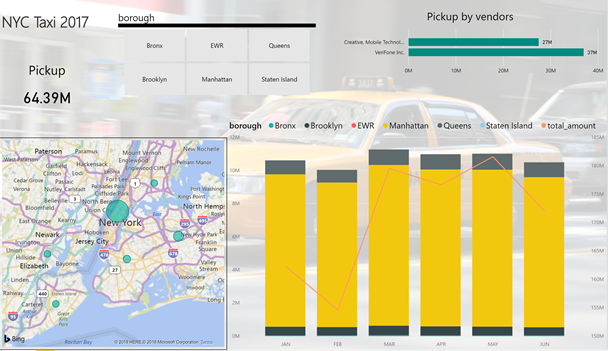
Voici un exemple de rapport
Index
Dans le cas où vous souhaitez charger toutes les données dans votre compte de stockage, il est possible de le faire avec la commande suivante
azcopy
--source https://franmerstore.blob.core.windows.net/nyctaxi-staging/ --destination https://<YourStorageAccount>.blob.core.windows.net/nyctaxi-staging/ --source-key $SRC_STORAGE_ACCESS_KEY --dest-key $AZURE_STORAGE_ACCESS_KEY --sync-copy --recursive
Dans notre exemple cette ligne de commande sera donc :
azcopy
--source https://franmerstore.blob.core.windows.net/nyctaxi-staging/ --destination https://datavorestorage.blob.core.windows.net/nyctaxi-staging/ --source-key $SRC_STORAGE_ACCESS_KEY --dest-key $AZURE_STORAGE_ACCESS_KEY --sync-copy –recursive