- Home
- Windows Server
- Storage at Microsoft
- Deploying DFS Replication on a Windows Failover Cluster – Part III
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
First published on TECHNET on Jun 29, 2009
The previous posts in this series explained how to create a Windows Failover cluster and how to configure DFS Replication for high availability on that cluster respectively. Now, it is time to add the failover cluster as a member of a replication group.
Pre-deployment notes
-
Only failover clusters running Windows Server 2008 R2 can be configured as members of a DFS replication group. This feature is not available on failover clusters running on earlier versions of Windows Server.
-
There are no restrictions regarding which members of a replication group can be clustered. Similarly, replication groups can consist of multiple clustered member servers.
-
The other non-clustered replication member servers in the replication group can be running Windows Server 2003 R2, Windows Server 2008 or Windows Server 2008 R2. It is not a requirement to have all members of that replication group on Windows Server 2008 R2 in order to deploy a clustered replication member in that replication group.
-
After adding a failover cluster to a replication group, the replication group can be administered only using the DFS Management MMC snap-in that ships on Windows Server 2008 R2. The DFS Management MMC snap-in on member servers which are running Windows Server 2003 R2 or Windows Server 2008 will not be able to configure/manage a replication group that has a failover cluster as a replication member.
-
Read-only replicated folders can also be configured on a failover cluster. More details about how to configure a read-only replicated folder are available in a previous blog post.
The steps to create a new replication group are listed below. Before proceeding, please make sure that the DFS Replication service is installed and started on all the nodes of the failover cluster. Additionally, you will also need to have the Remote Server Administration Tools feature installed on the cluster nodes for configuring and administering replication. The DFS Management MMC snap-in that ships on Windows Server 2008 R2 is also available for download via the ‘ Remote Server Administration Tools package for Windows 7 ’. This package enables IT administrators to manage roles and features that are installed on computers that are running Windows Server 2008 R2, Windows Server 2008, or Windows Server 2003, from a remote computer that is running Windows 7 RC.
Step-by-step instructions for installing the DFS Replication service and the DFS Management console are available in a previous blog post. The below Server Manager screenshot illustrates a server on which DFS Replication has been installed.

Adding a Failover cluster to a replication group
Now, let’s take a look at how to configure a folder for replication between a couple of member servers, one of which will be clustered. Note that any/all members of a replication group can be clustered using the exact same instructions available in this series of blog posts – there are no restrictions on the number of clustered member servers in a replication group. We will configure a folder containing reports to be replicated to Contoso’s clustered hub server from the server in the branch office, so it can be backed up centrally at the hub server using backup software such as Microsoft’s System Center Data Protection Manager. For a quick recap, the replication topology we are going to configure looks similar to the below illustration.

Step 1: Launch the DFS Management Console (on the cluster node ‘PrimaryNode’).
The DFS Management console ( dfsmgmt.msc ) is an MMC snap-in that can be used to configure and manage DFS Namespaces as well as DFS Replication. The MMC snap-in is launched on the primary/active node of the failover cluster (called ‘PrimaryNode’ in this example).
Note:
Please note that the new Windows Server 2008 R2 features (read-only replicated folders and clustered DFS Replication) can be configured only using the DFS Management snap-in that ships on Windows Server 2008 R2.
The DFS Management console on Windows Server 2003 R2 or Windows Server 2008 servers cannot be used to configure read-only replicated folders or to configure DFS Replication on a failover cluster.
Select ‘Replication’ in the left hand side pane in order to configure and manage DFS Replication. The ‘Actions’ pane on the right can be used to configure replication groups and folders that need to be replicated using DFS Replication.

Step 2: Click on the ‘New Replication Group…’ action.
In the ‘Actions’ pane on the right, click on ‘New Replication Group…’ . This launches the ‘ New Replication Group Wizard ’, which is illustrated in the below screenshot. The wizard walks through a set of operations that need to be performed while configuring the new replication group.

Step 3: Select the type of replication group.
First of all, select the type of replication group to be created. The ‘Multipurpose replication group’ can be used to configure custom replication topologies. This type of replication group can be used to create replication topologies such as ‘hub and spoke’ and ‘full mesh’. It is also possible to create a custom replication topology by first adding a set of servers to the replication group and then configuring custom connections between them to achieve the desired custom replication topology.

The second type of replication group ( ‘Replication group for data collection’ ) is a special type of replication topology and is used to add two servers to a replication group in such a way that a hub (destination) server can be configured to collect data from another branch server. The steps are slightly different for these two types of replication group, but the wizard provides helpful information along the way.
Let’s select ‘Replication group for data collection’ for this configuration since we would like to replicate data from the branch office server to the clustered hub server for centralized backup using backup software running on the hub server. In order to configure multiple such branch office file servers for centralized backup in this manner, create multiple replication groups such as this one. Thereafter, configure backup software such as Microsoft’s System Center Data Protection Manager to centrally backup the data consolidated (using DFS Replication) on the hub server from multiple branch office file servers.
Step 4: Select the name and domain for the replication group.
In the ‘Name and Domain’ wizard page that follows, enter a name for the replication group as well as the domain in which to create the replication group. We’re creating a replication group called ‘ContosoBackup’ in this example.
In practice, you may want to name each replication group such that you can easily identify the branch office from which data is consolidated by virtue of the replicated folders configured in that group. For example, the ‘ContosoSales’ replication group is configured to consolidate data from the sales branch office, while ‘ContosoDesign’ is used to consolidate data from the design office etc.

Step 5: Specify the branch office file server (replication member)
In the ‘Branch Server’ wizard page that follows, enter the hostname of the branch office file server. In this case, we’re adding Contoso’s branch office file server. Data from this server will be replicated over the WAN to the central clustered file server we have just set up, for centralized backup using backup software.
Conceptually, to deploy such a solution for centralized branch office backup of multiple branch offices, you would need to create one such replication group for each branch office, with the clustered hub server as a replication partner (Branch Server) for all these replication groups.
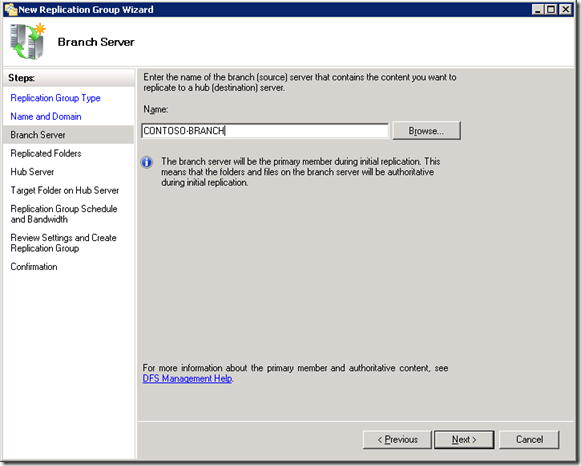
Step 6: Select the folders to replicate from the branch office server.
In the ‘Replicated Folders’ wizard page that follows, click the ‘Add…’ button and enter the names of the replicated folders which are to be replicated from this branch office file server to the hub server. Multiple replicated folders can be added on this wizard page. In this example, we have selected to replicate the folder ‘D:\Reports’ from the branch office file server.

Step 7: Specify the hub server (other replication member)
In the ‘Hub Server’ wizard page that follows, the name of the hub server for this replication group needs to be specified. In this example, we want to consolidate data from the branch office file server to the clustered hub server at the datacenter. Therefore, we will enter the failover cluster’s client access point here.
IMPORTANT: This is the most important step to be taken while configuring DFS Replication on a Windows Failover cluster. Here, instead of hostname of the individual server, enter the Client Access Point for the failover cluster you wish to add as a replication member.
In the previous blog post, we took a look at how configure a highly available file server on the cluster we created. This highly available file server was configured to be accessed through a Client Access Point called ‘ContosoFileSrv’ . This Client Access Point name needs to be entered here.
|
|
If you are creating a multi-purpose replication group, the only difference between adding a regular member server and a clustered member server is that you would need to specify the Client Access Point for a clustered member server. For a regular member server, specify the hostname of the server. Generically speaking:
|


Step 8: Specify the path to the replicated folder on the hub server.
In the ‘Target Folder on Hub Server’ wizard page, specify the path on the clustered hub server where you would like to store the data replicated from the branch office file server.
This can be done by clicking on the ‘Browse…’ button and selecting a path from the ‘Browse For Folder’ dialog box. Note that this dialog box only displays shared volumes. This is because on a failover cluster, the replicated folder should be hosted only on shared storage. This enables replication responsibilities to be failed over between the nodes in the cluster.

Note how the below ‘Browse For Folder’ dialog box only displays shared volumes (cluster volumes). In this example, we have selected to consolidate the data replicated in from the branch office file server to a directory called ‘Contoso-Branch’ on the clustered hub server. Note that this directory is located on the shared/clustered volume ‘G:’. This ensures that replication responsibilities can be failover between the cluster nodes.

Step 9: Configure the replication schedule and bandwidth utilization.
Using the ‘Replication Group Schedule and Bandwidth’ wizard page, a custom replication schedule and custom bandwidth throttling settings can be configured. The default option configures the DFS Replication service to replicate continuously without any bandwidth restrictions.

It is possible to configure replication to take place during specific time windows (such as, after office hours to ensure reduced consumption of available WAN bandwidth). This can be done by selecting the option ‘Replicate during the specified days and times’ and then selecting the replication schedule in the wizard page that is launched. For example, the below screenshot illustrates how replication has been configured using all available bandwidth between 6pm and 6am (after office hours).

That’s it! The replication group can now be created. The confirmation dialog box displays the status of this configuration task.

Remember that replication does not begin until the configuration settings for this new replication group have replicated to the domain controller that is polled for configuration information by the DFS Replication service on the replication group members. Therefore, there will be a delay corresponding to the time it takes for the new configuration settings to replicate between domain controllers in the domain and the time taken for all replication member servers to receive these configuration changes from Active Directory.

Once the replication group has been configured, it will show up in the DFS Management MMC snap-in. For example, the below screenshot shows that a replication group called ‘ContosoBackup’ has been created with two replication member servers – the branch office file server ( ‘CONTOSO-BRANCH’ ) and the 2-node clustered file server at the datacenter ( ‘CONTOSOFILESRV’ ). These two servers replicate a folder called ‘Reports’ between themselves. The configuration is such that the data generated on the branch office file server (CONTOSO-BRANCH) is replicated over WAN links to the central datacenter file server cluster (CONTOSOFILESRV) for centralized backup.

In order to consolidate data from multiple branch office file servers to this file server cluster, create more such replication groups.
|
|
Active Directory replication ensures that changes in configuration are replicated amongst all domain controllers so that any domain controller polled by the DFS Replication service has up to date configuration information. Therefore, the rate at which the DFS Replication service notices changes in configuration information is dependent on AD replication latencies as well as the frequency with which it polls Active Directory for configuration information. Hence, it will take a while before the DFS Replication service on the replication member servers notices this change and sets up replication. |

… Now, over to Failover Cluster Manager
Now that we have created a replication group and added the failover cluster as a member server, let us take a look at the Failover Cluster Manager MMC snap-in to see if something has changed there. After the DFS Replication service on the cluster node polls Active Directory and notices that a new replication group has been created with it as a replication member, it will automatically create a cluster resource for every replicated folder in that group. This will be done by the DFS Replication service running on the node that currently owns the client access point/cluster group against which replication has been configured.
Note that the DFS Replication service maintains one cluster resource per replicated folder.

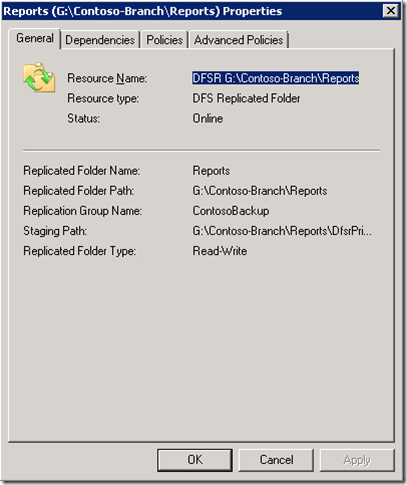
The above screenshot shows that a new cluster resource of type ‘DFS Replicated Folders’ has been created. Notice how the resource name is a combination of the replicated folder name and the path to the replicated folder. This resource is online and the cluster node ‘PrimaryNode’ is currently responsible for replicating data with the CONTOSO-BRANCH server (replication partner).
This cluster resource can now be taken offline or moved to the other node of the failover cluster (‘SecondaryNode’) in case of planned failovers for maintenance of the primary node. Also, if the primary node of the failover cluster were to suffer outages, the Failover Clustering service will automatically move this resource over to the secondary node of the failover cluster. Correspondingly, the secondary node of the failover cluster will now take over replication responsibilities. The DFS Replication service on other replication partners will notice a minor glitch while the failover process is taking place, but will then continue to replicate with the failover cluster as usual (with the secondary node having taken over responsibilities for replication).
Some notes on administering replication on the failover cluster
The DFS Replication service automatically creates and deletes its cluster resources. There is no need for administrators to manually create or configure cluster resources for the DFS Replication service. Regular administrative tasks for the DFS Replication service can be performed using the DFS Management console (including creating new replicated folders, deleting/disabling replicated folders, changing staging areas and quotas, modifying connections, configuring bandwidth throttling and replication schedules etc.). The DFS Replication service will automatically configure and update its cluster resources when it notices these configuration changes after polling Active Directory.
For instance, if a replicated folder is disabled using the DFS Management Console, the corresponding cluster resource will be deleted and will disappear from the Failover Cluster Manager MMC snap-in, as soon as the DFS Replication service polls Active Directory. Subsequently, if the replicated folder is re-enabled using the DFS Management snap-in, a corresponding cluster resource appears in the Failover Cluster Manager MMC snap-in. This happens as soon as the DFS Replication service polls Active Directory and notices the change to ‘Enabled’.
Each replicated folder configured with the cluster as a member server will have one such cluster resource. The resource status can be toggled between ‘Online’ and ‘Offline’ states using the Failover Cluster Manager snap-in, similar to any other cluster resource.

Right clicking the resource brings up its properties, which provides a quick way to view the configuration information for the replicated folder, such as the folder name, path, staging path and whether the folder has been configured to be read-only.
Using the Failover Cluster Manager MMC snap-in, the ownership of a particular cluster group can be moved between the nodes of the cluster group if required. All replicated folders belonging to a particular replication group will be part of a single cluster group and therefore only a single node in the cluster can assume ownership and replication responsibilities for those replicated folders at any given point in time.
The regular administration primitives exposed by the Failover Cluster Manager MMC snap-in can be used to move a cluster group containing replicated folders between the cluster nodes that can be potential owners of that cluster group.

Using these steps it is possible to configure a replication member server on a Windows Failover Cluster for highly available replication services.
All posts in this series:
-
Deploying DFS Replication on a Windows Failover Cluster – Part I: Explains how to create a new Windows Server 2008 R2 failover cluster.
-
Deploying DFS Replication on a Windows Failover Cluster – Part II: Explains how to configure DFS Replication service for high availability on the failover cluster.
-
Deploying DFS Replication on a Windows Failover Cluster – Part III: Explains how to add the failover cluster as a member server in a DFS replication group.
-------
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.