Using SQL Server 2016 for a DSC Pull Server
Abstract
This article describes how to use a SQL Server 2016 as the backend database for a Desired State Pull Server. The default database engine is EDB and lacks a couple of feature required. It is quite hard to create reports based on the EDB and using the web service to retrieve data can get extremely slow. This is why we needed another solution for DSC reporting.
This article guides you through the setup process.
Credits
This article is inspired by Using SQL Server DB for DSC and adds more automation and a better security model.
Also worth a look the post Use SQL Server as DSC Pull Server Backend?. It explains why you cannot use SQL Server directly and have to go over the MDB.
Requirements
You need to have a good understanding about DSC in general and how to setup a DSC pull server.
To be able to successfully execute all the steps described here, you need a domain joined DSC pull server and a SQL Server 2016 joined to the same forest. One or more machines that will become DSC nodes are also quite helpful.
If you want to setup the requirements automatically, look at AutomatedLab and the script DSC Pull Scenario 1 (Pull Configuration).ps1. Only the SQL Server 2016 is missing in this deployment script but can be added with just to lines:
[code lang="powershell"]
Add-LabIsoImageDefinition -Name SQLServer2016 -Path $labSources\ISOs\en_sql_server_2016_standard_with_service_pack_1_x64_dvd_9540929.iso
Add-LabMachineDefinition -Name DSQL1 -Roles SQLServer2016
If you want to redeploy the scenario that this article describes, you can use the script DSC Pull Scenario 1 with SQL Server.ps1. It takes care of the requirements plus all what is described in this post fully automated. So, if you just need a lab with a DSC pull server that stores all data on SQL, this can save you a huge amount of time.
Setting things ready on the SQL Server and connecting the pull server
On the SQL Server, you need to create the database for DSC and login for the computer account.
Note: The article mentioned in the credits section is great and saved me a lot of time. But one thing I did not like is providing credentials if not absolutely required. The initial approach used credentials stored along with the OleDB connecting in the registry. The setup described here works differently and gives the computer account of the DSC pull server write access to the database.
Creating the DB on the SQL Server
Note: All tasks in this section are executed on the SQL Server
The SQL script to create the database is published on CreateDscDatabase.ps1. It asks for a domain name and a computer name, creates a SQL Server login for that user and gives this login write access to the DSC database.
The table setup is almost like described in Using SQL Server DB for DSC. There is only one additional column called AdditionalData in the table StatusReport.
Along with the tables there is a trigger to transform the data into readable JSON and a couple of functions and views to get a report of your DSC nodes. Details about this will be covered in the next article.
Please just run the script on the SQL Server like this by providing the domain name and the computer account name of the pull server.
[code lang="powershell"]
C:\CreateDscDatabase.ps1 -DomainName contoso -ComputerName dpull1
The output should look like this:
[code]
Creating the DSC database on the local default SQL instance...finished.
Database is stored on C:\DSCDB
Connecting the DSC Pull Server with the SQL database
Note: All tasks in this section are executed on the Pull Server
The pull server must be configured to use MDB instead of the default EDB database
If not already done, please change the database model for the pull server from edb to mdb. If you deploy the pull server with AutomatedLab and the script mentioned earlier, the database model is already set to MDB. If you want to configure the pull server by yourself or want to change the database model after the deployment, you may want to use this DSC config file: SetupDscPullServerMdb.ps1.
If everything is configured correctly, you should see these entries in the C:\inetpub\PSDSCPullServer\web.config file:
[code lang="xml"]
<add key="dbprovider" value="System.Data.OleDb">
<add key="dbconnectionstr" value="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\Program Files\WindowsPowerShell\DscService\Devices.mdb;">
ODBC Data Source
The MDB that we will use in the next step requires an OleDB connection named "DSC"? which needs to point to the SQL Server that you have created the DSC database previously. You can create the data source either using the ODBC Data Source Administrator or PowerShell. The command for that is:
[code lang="powershell"]
Add-OdbcDsn -Name DSC -DriverName 'SQL Server' -Platform '32-bit' -DsnType System -SetPropertyValue @('Description=DSC Pull Server', "Server=<Name of your SQL Server>", 'Trusted_Connection=yes', 'Database=DSC') -PassThru
Replacing the MDB with a version that is using "linked tables"
After changing the database model to MDB, the pull server writes all information into that file. However, the purpose of this article is to have the data in a SQL database. To achieve that, the MDB (C:\Program Files\WindowsPowerShell\DscService\Devices.mdb) should be replaced by this version Devices.mdb. This MDB uses linked tables to redirect the data to the SQL Server. If you are not sure what happens inside the file, just open it with Access and you will see the tables but no data yet on the right side, as there is nothing in the DSC database on the SQL Server.
Note: If you feel uncomfortable using the mdb that someone else uploaded, you can very easily create the file by yourself. The steps are described in Using SQL Server DB for DSC.
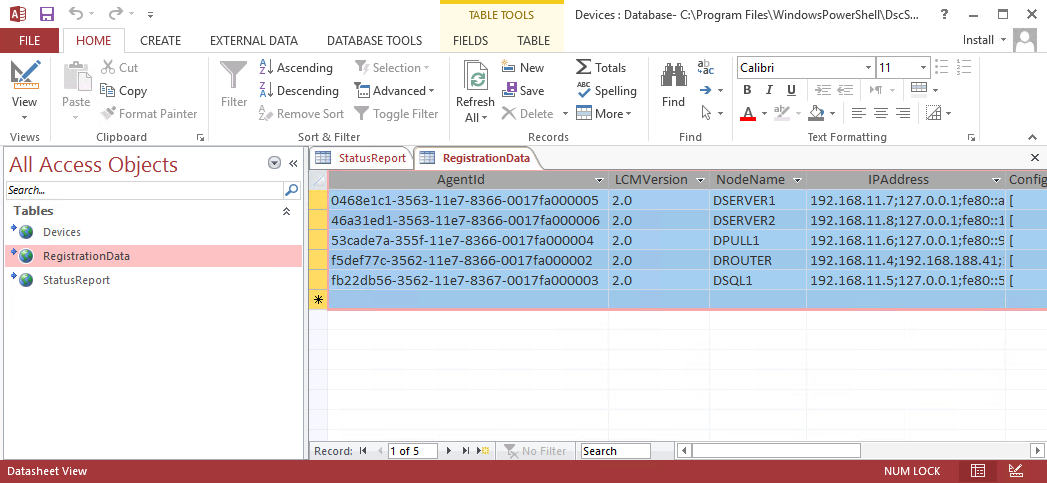
Testing the setup
This section covers a very easy test configuration and configures some machines to pull the configuration from the pull server. In order to do that data has to be written in the SQL database.
Defining the configuration
The configuration is just making sure that the given file has the content "OK"?. The node name is "localhost"? so it applies to each machine that pulls it.
[code lang="powershell"]
Configuration 'TestConfig'
{
Import-DscResource –ModuleName 'PSDesiredStateConfiguration'
Node localhost
{
File 'TestFile'
{
Ensure = 'Present'
Type = 'File'
DestinationPath = 'C:\DscTestFile'
Contents = 'OK'
}
}
}
Converting the configuration into a MOF
The local configuration manager cannot use DSC configuration written in PowerShell directly. You have to build a MOF first.
[code lang="powershell"]
TestConfig -OutputPath C:\DscTestConfig | Out-Null
The MOF file always get the name of the given node, in this case "localhost.mof"?. This is not the best name for the configuration so the file is renamed to "TestConfig.mof".
[code lang="powershell"]
Rename-Item -Path C:\DscTestConfig\localhost.mof -NewName Rename-Item -Path C:\DscTestConfig\localhost.mof -NewName TestConfig.mof
Publishing the MOF
Now you are finished creating the MOF. But the pull server does not know about it hence clients cannot pull the MOF. Publishes configurations (MOFs) need to be in the folder C:\Program Files\WindowsPowerShell\DscService\Configuration along with a checksum. The easiest way to achieve this is by calling the following cmdlet.
[code lang="powershell"]
Publish-DSCModuleAndMof -Source C:\DscTestConfig
Telling the DSC nodes to pull the TestConfig
So far, no computer in the lab knows about the pull server. To introduce the pull server to the nodes, you must configure the local configuration manager, of course also using DSC. The following configuration does all this.
Note: The attribute DSCLocalConfigurationManager indicates that a special kind of configuration called meta configuration should be created. Meta configurations are configuring the LCM and have the extension .meta.mof. More info on this can be found in Configuring the Local Configuration Manager.
[code lang="powershell"]
[DSCLocalConfigurationManager()]
Configuration DscClientConfig
{
param(
[Parameter(Mandatory)]
[string]$PullServer,
[Parameter(Mandatory)]
[string]$RegistrationKey,
[Parameter(Mandatory)]
[string[]]$ComputerName,
[Parameter(Mandatory)]
[string]$ConfigurationName
)
Node $ComputerName
{
Settings
{
RefreshMode = 'Pull'
RefreshFrequencyMins = 30
ConfigurationModeFrequencyMins = 15
ConfigurationMode = 'ApplyAndAutoCorrect'
RebootNodeIfNeeded = $true
}
ConfigurationRepositoryWeb PullServer
{
ServerURL = "https://$($PullServer):8080/PSDSCPullServer.svc"
RegistrationKey = $RegistrationKey
ConfigurationNames = $ConfigurationName
}
ReportServerWeb ReportServer
{
ServerURL = "https://$($PullServer):8080/PSDSCPullServer.svc"
RegistrationKey = $RegistrationKey
}
}
}
Now this meta configuration needs to be built and finally pushed to the DSC nodes. The following code does this for all the computers that are in the computers container in Active Directory. The registration key is a GUID you have to generate and provide when setting up the pull server. This GUID is written to a text file that is required for the next step.
[code lang="powershell"]
$computerContainerDn = "CN=Computers,$((Get-ADRootDSE).defaultNamingContext)"
$computerName = (Get-ADComputer -SearchBase $computerContainerDn -Filter *).DnsHostName
$registrationKey = Get-Content -Path 'C:\Program Files\WindowsPowerShell\DscService\RegistrationKeys.txt'
DscClientConfig -OutputPath c:\DscClientConfig -PullServer $env:COMPUTERNAME -RegistrationKey $registrationKey -ComputerName $computerName -ConfigurationName TestConfig
Set-DscLocalConfigurationManager -Path C:\DscClientConfig -ComputerName $computerName
Start-DscConfiguration -UseExisting -ComputerName $computerName -Wait -Verbose
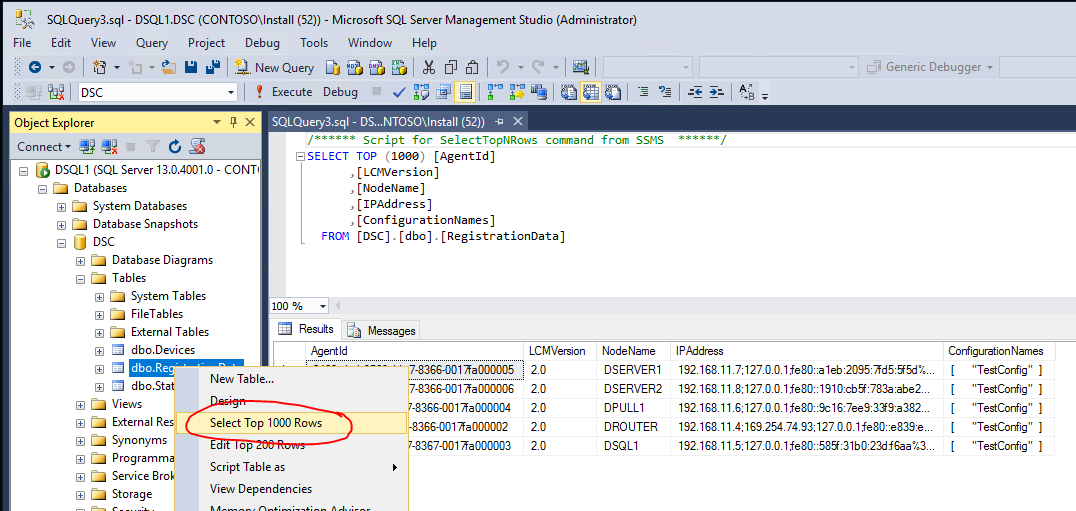
Verifying the data on the SQL Server
Now it is time to open the SQL Server Management Studio on the SQL Server and navigate to the DSC database, then to the table "RegistrationData". Do a right-click and then click on "Select Top 1000 Rows"?. You should see data like this indicating that everything works as expected.
Conclusion
It looks more complicated as it is to move the DSC data to a SQL Server. Still, this is a workaround and I hope that in the future we can provide a connection string for SQL Server in the web.config directly (dbconnectionstr).
Having the data now on SQL gives you a universe of tools to do reporting and data hygiene tasks. In this article, I have used SQL Server 2016 as it natively supports JSON which is important as the pull server stores JSON in SQL columns.
The next article will cover advanced reporting with the data you have in SQL Server now.