The importance of the Event ID 15003
Sometimes events, which seems to be unimportant can be really important: The OpsMgr Event ID 15003 is such an event.
What does Event ID 15003 tell us?
The informational Event 15003 is OpsMgrs way to tell us, that the amount of Management Servers in a resource pool has changed and that the load of running common workflows (e.g. Groupcalc) has been redistributed among the available pool members.
It is an informational event, so why bother?
Unfortunately today I made the mistake and underestimated it…
We discovered an issue with monitoring of network devices. For all monitors targeted at network devices in the Management Group OpsMgr created State Changes every 3-10 minutes. The Monitors were flipping from uninitialized to initialized:
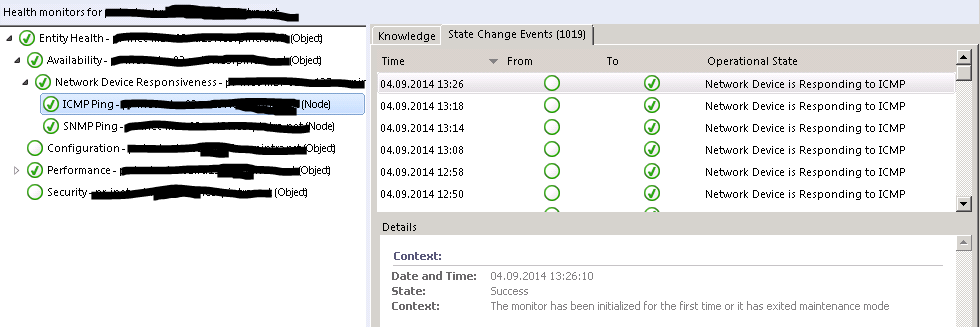
We analyzed the environment but could not find the cause for the problem. A colleague (thanks Mihai) then pointed me to the multiple 15003 events occurring in the environment:
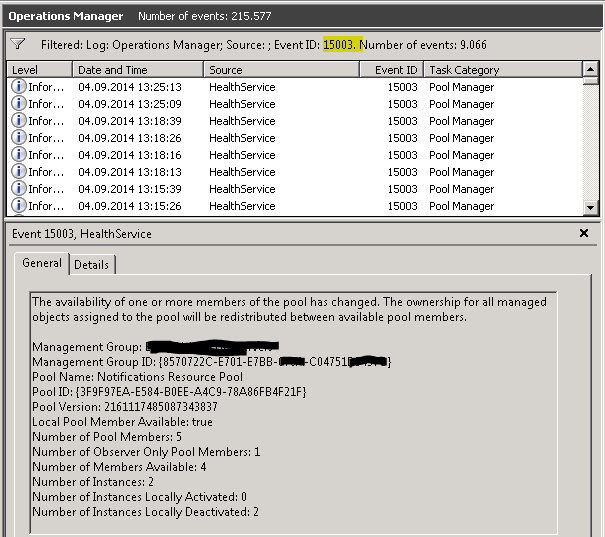
Hmm, strange, we had State Changes everytime the resource pool used for monitoring the network devices redistributed its workflow. Coincidence? Certainly not.
But what causes the constant 15003 events? There are several reasons, some of which are very serious and should be checked by our CSS team. But the most common cause I have seen so far is pretty simple:
Common cause for frequent 15003 events
There is a registry key called HKLM\System\CurrentControlSet\Services\HealthService\Parameters\PoolManager. Its values helps to tune the internal calculation of who will be member of a pool and how the load will be balanced between the members. More details for this key can be found in two very interesting blog posts from Bob Cornellisen and Tech mesh.
This key is usually automatically created on fresh installations of OpsMgr 2012 RTM, but we removed it in SP1 and R2.
The problem is:
if you have multiple Management Server in your environment (which you definitively should have) and they have different settings regarding this key (maybe one with the key set and the others without it), a not so funny game will start:
The default setting for the value PoolLeaseRequestPeriodSeconds has been changed between RTM and SP1/R2.
All Management Server in a pool will use this setting to negotiate who is responsible for handling workflows in the pool (who is “in” and who is “out” so to say). If the setting is the same on all servers, the load will be distributed evenly (everybody is “in”). If some of these servers have different settings, the load will be distributed between the Management Server with the lowest value. The server(s) with the reg key set (which is “out” in this case) will always think, that he was the only working server in the pool (“last man standing”). So he will continually take over the load for all running workflow instances.
The other members in the pool on the other side do a different kind of math: From their point of view he is “out” and the "redistribution game" will start over again.
The solution
The solution for this problem is quite easy:
- Either create the missing reg key on all Management Servers with the same values or
- delete the key on all and restart the HealthService on ALL Management Server. Soon after the frequent 15003 events will be gone.
In our case of the flipping network device monitors:
We had two Management Server in the network monitoring resource pool, and one of them had the key set. So the workflows were permanently loaded and unloaded on the server dedicated to SNMP monitoring..
Conclusion
- Be very carefull when modifying/using the key HKLM\System\CurrentControlSet\Services\HealthService\Parameters\PoolManager to specify how the load will be distributed inside a resource pool.
- Always have an eye on the 15003 events, even if it is only informational. If it occurs frequently it can point you to a serious issue with your resource pools.