Was passiert, wenn DCs zu beschäftigt sind um die Last messen zu können
Wir sehen den Trend, dass bei vielen Kunden das Active Directory im Mittelpunkt des Identity Management steht. Es werden darüber Zertifikate und Group Policies verteilt, verschiedenste Netzwerk-Dienste verwenden Active Directory um Benutzer zu authentifizieren und Daten aus dem AD um sie zu autorisieren.
Dann gibt es noch eine ganze Reihe Dienste welche ihre Konfiguration im Active Directory speichern, inklusive der Einstellungen der Benutzer und anderer für den Dienst verwendete Objekte.
Andere Dienste synchronisieren regelmäßig eigene Datenbanken mit AD, bei Produkten wie dem Microsoft Forefront Identity Manager ist es praktisch der einzige Daseinszweck. Ich will jetzt keine Diskussion darüber anstoßen ob das nun Meta-Verzeichnisdienste oder virtuelle Verzeichnisse sind, und in welche Klasse der Office 365 DirSync fällt…
So oder so, die Anzahl von Komponenten, und die Menge und Komplexität der Anfragen an Active Directory hat eine nach oben offene Tendenz.
Was machen meine Domain Controller den ganzen Tag?
Nun haben die Domain Admins nicht immer ausreichend Wissen, welche Applikationen in welchen Abteilungen welche Anfragen an Active Directory stellen. In einigen Firmen scheinen die AD-Admins als letzte zu erfahren, was von anderen Abteilungen an signifikanten Änderungen geplant ist.
Es gibt auch das andere Ende der Skala. Es kann schon eine „unschuldige“ Änderung an einem Logon Script für eine Überlastung der DCs in den Morgenstunden sorgen. Das ist ein Klassiker im Bereich Domain Controller Performance.
Wir haben an dieser Stelle schon darüber geschrieben, und auch heute beginnen viele SRs mit der Beschreibung, dass die DC-Antwortzeiten hoch sind und LSASS viel CPU-Zeit verbraucht. In der Zwischenzeit ist der „Server Performance Advisor“ (SPA) aus der Zeit Windows Server 2003 ins Betriebssystem gewandert und firmiert dort als „Data Collector Sets“. Zu dem Toolset gibt es einen guten englischen Blog. Noch neuer ist die Version 3.1 von SPA, die eignet sich für Euch vor allem für das Baselining.
Die Reports dieser Datensammlungen sind in unserer Support-Arbeit ein sehr wertvolles Tool um besser zu verstehen, welche Anfragen den Domain Controller beschäftigen.
Deutlich weniger Fälle beschäftigen sich mit der Thematik DCs sind langsam, Auslastung ist aber nicht hoch. Ein paar typische Themen habe ich schon in einem Blog diskutiert.
Die „Data Collector Sets“ stoßen an Grenzen
Wir beobachten jetzt öfter bei Kunden, dass diese Data Collector Set Reports unvollständig sind, weil Dateien fehlen oder die Erzeugung des HTML-basierten Reports abbricht.
So sieht das Verzeichnis eines Berichts aus, der erfolgreich war:
16.09.2014 10:57 557.973.504 Active Directory.etl
16.09.2014 10:57 6.531 AD Registry.xml
16.09.2014 10:57 165.609.472 NtKernel.etl
16.09.2014 10:57 5.636.096 Performance Counter.blg
16.09.2014 11:07 19.841.268 report.html
16.09.2014 11:05 62.345.970 report.xml
16.09.2014 10:57 62.745 report.xsl
16.09.2014 11:05 0 rules.log
8 File(s) 811.475.586 bytes
Bei diesem Bericht hast das nicht mehr geklappt:
16.09.2014 10:25 2.027.094.016 Active Directory.etl
16.09.2014 10:25 6.530 AD Registry.xml
16.09.2014 10:25 202.244.096 NtKernel.etl
16.09.2014 10:25 5.963.776 Performance Counter.blg
16.09.2014 10:39 289.737.190 report.xml
16.09.2014 10:25 62.745 report.xsl
16.09.2014 10:38 0 rules.log
7 File(s) 2.525.108.353 bytes
Das ist jetzt kein Suchbild…neben der größeren Dateien fällt auf, dass der Bericht „report.html“ fehlt.
Wir haben mittlerweile die wichtigen Parameter für die Report-Erzeugung identifiziert:
Am Ende der Datensammlung wird der Report durch einen Prozess „tracerpt.exe“ generiert.
„tracerpt.exe“ läuft mit niedriger Priorität, „verliert“ im Rennen um CPU-Zeit also gegen einen beschäftigten LSASS-Prozess.
„tracerpt.exe“ arbeitet mit einem Thread, hat also nicht viel Vorteil von vielen CPU-Cores.
„tracerpt.exe“ braucht mehr Speicher je länger er läuft.
Der Report-Generator-Prozess „tracerpt.exe“ hat sechs Stunden um den Report zu erstellen. Danach wird er abgebrochen.
Die Einstellungen für die Datenverwaltung des vordefinierten Sets löscht die größten Sets ab einer Größe von 1 Gigabyte. Die größte Einzeldatei welche auch den meisten Aufwand erzeugt ist „Active Directory.etl“.
Ein Kunde mit sehr großzügig ausgestatteten Domain Controller (24 Serverklasse CPUs, 256 GB Speicher) hat für verschiedene Report-Größen Messungen gemacht:
Bis zum Ablauf der sechs Stunden hat „tracerpt.exe“ bis zu 12GB an Arbeitsspeicher allokiert.
In der Zeit war durchgängig ein CPU-Core zu 100% belegt. In realen Überlastszenarien müsstet Ihr die Priorität von „tracerpt.exe“ im Task Manager erhöhen, damit genug CPU-Zeit verfügbar wird.
Den größten Datensatz, welcher erfolgreich durchgelaufen ist, hatte eine „Active Directory.etl“ von 3 GB.
Ihr solltet jedoch erwarten, dass auf schlechter ausgestatteten Rechnern die Grenzen deutlich niedriger liegen, weil zum Beispiel nicht so viel Speicher frei ist oder die CPUs langsamer und anderweitig beschäftigt sind.
Was tun, sprach Zeus?
Es gibt die Möglichkeit über einen eigenen Data Collector Set einige Parameter anzupassen. Der erste Schritt ist, einen oder mehrere Klone des System AD Data Collector Set anzulegen, je nach Einsatzzweck.
Im Container „User Defined“ könnt Ihr ein neues Set anlegen:
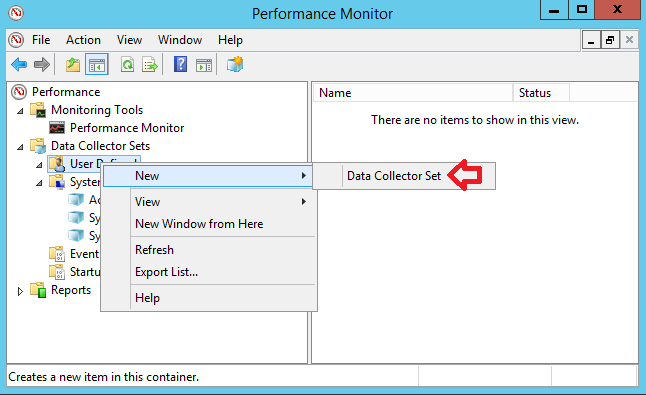
Es läuft nun ein Assistent ab, der in mehreren Dialogen die Parameter für das neue Set abfragt.
Als erstes geben wir dem Kind einen Namen und geben auch an, dass wir ihn aus einem Template erzeugen wollen:
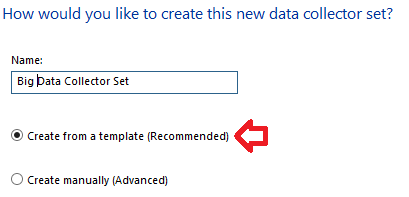
Auf der nächsten Seite wählen wir das Template aus. Das kann ein von diesem oder einem anderen Rechner exportiertes Set als XML-Datei sein (Auswahl nach „Browse“), oder wie in unserem Fall ein System Set „Active Directory Diagnostics“:
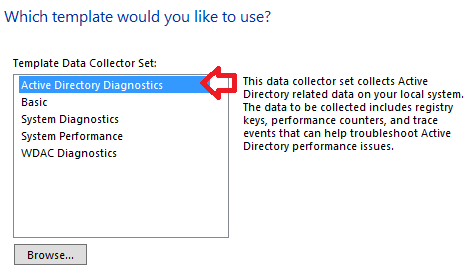
Der letzte optionale Schritt ist die Festlegung des Speicherorts für den Set. Hier möchtet Ihr vielleicht ein Volume mit mehr Platz oder weniger IO-Last verwenden:
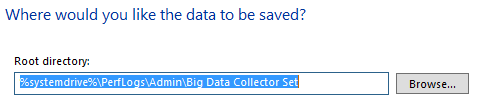
Da ist noch eine Seite im Assistenten, da braucht aber nichts geändert werden. Ihr könnt nun „Finish“ anklicken.
Für ein „Big Data Collector Set“ sind wichtige Einstellungen auch hinter dem Menüpunkt „Data Manager“, da fangen wir an:
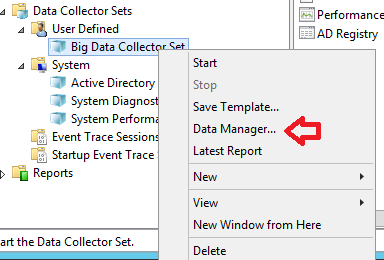
Die wichtigen Einstellungen sind die „Resource Policy“ und die „Maximum Root Path Size“. Ich empfehle, die auf die angezeigten Werte anzupassen:
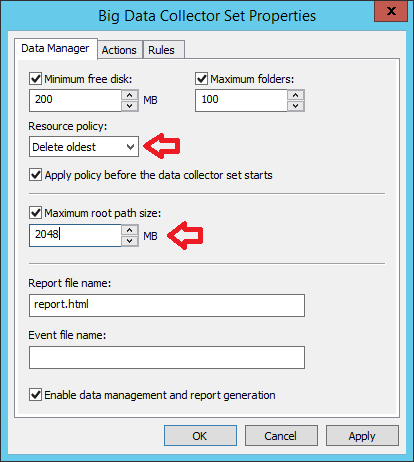
Was die Größe der Datensätze angeht, solltet Ihr etwas experimentieren, was für Euren Einsatzzweck am besten funktioniert. Da können durchaus 10GB dabei heraus kommen.
Die zweite wichtige Stellschraube ist die Laufzeit des Sets, welche per Standard bei fünf Minuten und einem Report liegt. Das kann in den Eigenschaften des Sets im Reiter „Stop Condition“ angepasst werden, in vielen Fällen kann ein kürzeres Sammelintervall genauso gut funktionieren:
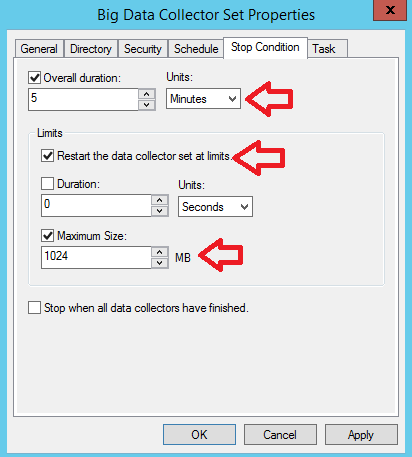
Ihr solltet aber nicht unter zwei Minuten gehen, da Ihr in den Reports sonst LDAP Queries nicht mehr in der Analyse seht, die in das Limit von 2 Minuten laufen. Ich würde das untere Limit bei 3 Minuten setzen.
Besonders der Neustart der Datensammlung bei vielen Daten ist eine interessante Sache. Je nach Situation kann es jedoch etwas verwirrend werden, wenn zu einem Lauf etliche Verzeichnisse existieren, und Ihr für eine volle Auswertung mehrere Reports durchsehen müsst. Aber ich meine, das ist besser als gar keine Daten.
Wenn Ihr hier lange loggen lasst und den Log bei 1GB neu startet, dann ist es sinnvoll, im „Data Manager“ viel größere Werte für die Datengröße anzulegen. Nicht dass der erste Teil des Laufs schon wieder gelöscht ist…
Wie sehe ich während eines Kollektor-Laufs wie viel Daten schon gesammelt sind?
Während der Laufzeit der Datensammlung gibt sich der Explorer recht zugeknöpft was die Größe der Dateien angeht:
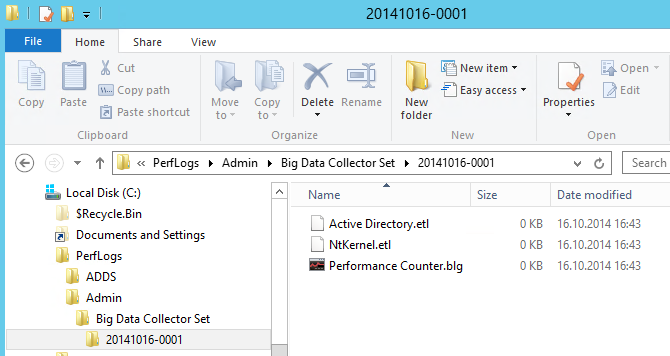
Der Explorer aktualisiert das erst, wenn Ihr was mit der Datei macht. Und was am schnellsten geht ist die Datei zu löschen:
Dann ist die Anzeige aktuell.
Wenn Ihr wegen der hohen Last abschätzen könnt, dass das Datenset sehr groß wird, könnt Ihr auch die Sammlung vorzeitig anhalten:
Soll das nun alles sein?
Wir arbeiten mit unseren Entwicklern daran, die Auswertung der Datensätze performanter zu machen. Das erlaubt, größere zusammenhängende Datensätze zu erzeugen.
Ich vermute jedoch, es wird einigen von Euch bei richtig großen Reports dann durchaus auch sehr langsam vorkommen, Berichte größer als 20 MB im Browser zu handhaben. Nicht nur weil die Größe der Tabellen dem Browser zu schaffen macht, sondern sie auch Eure Aufnahmefähigkeit sprengt…
In diesem Sinne, keine viereckigen Augen wünscht
Herbert