Considerations for Exchange 2007 CCR Stretch Clusters
Since Exchange 2007 deployed, I’ve been asked many times what should be considered when designing a stretch Cluster Continuous Replication (CCR) server configuration. A stretch CCR is typically where you have 1 node in 1 physical datacenter and the other CCR node in a separate physical datacenter, typically connected over a private WAN link. This blog provides some of those considerations.
Consider a stretch CCR environment that spans 2 different data centers.
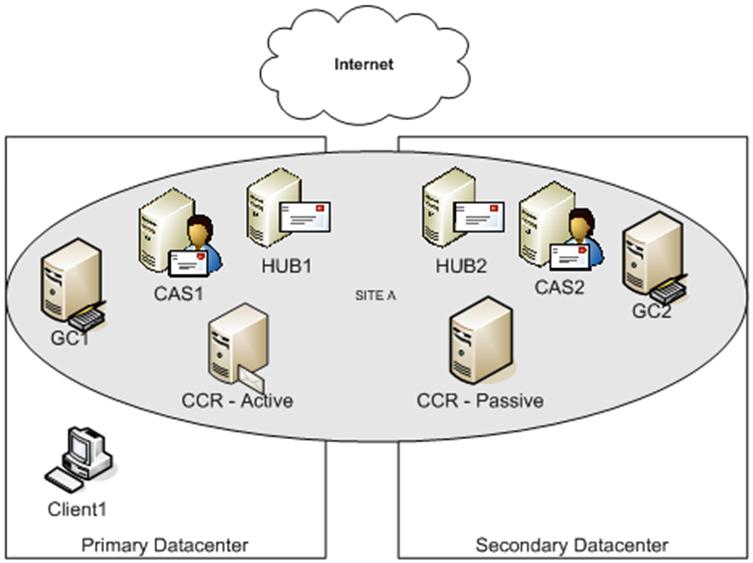
Consider the following potential issues when using stretched CCR nodes across 2 datacenters -&- same AD Site:
Network
- If using Windows 2003 operating system, each node must be on the same subnet. If using Windows 2008, cluster nodes can span across multiple subnets.
- With Windows 2003 Cluster server, cluster communication needs to be .5 seconds for round trip communication. With Windows 2008, this is a little more flexible but does not improve performance.
- For many configurations, testing has shown that that network latency between CCR nodes should be below 50ms.
Exchange Features
- CCR allows for a maximum of 2 physical nodes running Exchange 2007 per cluster. Whereas Standby Continuous Replication (SCR) can have multiple targets
- Only the Exchange Server 2007 Mailbox Role can be on a CCR server. Since the mailbox role needs to have a HUB and CAS server available in the local AD site, this means that you need to place additional hardware in both datacenters to support the HUB and CAS role. This is in case 1 datacenter fails – the other can continue with all roles.
- If planning on using Public Folders, know the limitations of PF on CCR (Planning for Cluster Continuous Replication)
Active Directory
- Per Planning for Cluster Continuous Replication, all CCR nodes MUST be in the same AD Site.
- Typically, Active Directory communication is controlled based on the AD Site design. Since both datacenters are using the same AD site, there is a risk that servers and clients in 1 datacenter may be communicating to domain controllers in the secondary datacenter.
Mail Flow
- By default, the Mailbox Server’s Microsoft Exchange Mail Submission Service load balances notification events between the Hub Transport servers that are located in the same AD site as the Mailbox Server. In a stretch cluster configuration, the Mailbox Server could be talking to a HUB server in the remote datacenter. This could generate additional network traffic and make it more difficult to control scheduled outages (i.e. HUB server reboot could impact production mailbox servers). To reduce this risk, additional configuration of the Mailbox Server may be required using the Set-MailboxServer –SubmissionServerOverrideList parameter.
Client Access
- In most scenarios, a Client Access Server (CAS) server will be required to provide access to Outlook Anywhere, Availability Service, Autodiscovery, POP3/IMAP4, OWA, and Activesync. For redundancy and load balance purposes, you might need multiple CAS servers in each datacenter.
- Exchange 2007’s Autodiscovery service will automatically detect which Client Access server is closest to the user's mailbox based on AD site design. If it selects the CAS server in the secondary datacenter, this would create additional network traffic and might generate client performance issues.
Maintenance & Monitoring
- If monitoring both CCR nodes from 1 datacenter, this might generate additional network traffic to be sent over the WAN link.
- Performing routine maintenance of a node (i.e. install service pack) might require you to failover to the secondary datacenter. This forces you to perform additional tasks for scheduled outages which might cause longer delays in restoring service back to the original datacenter.
Backups
- In most environments, the primary backup solution is located in the primary datacenter works on more than just Exchange. Exchange 2007 CCR allows you to take backups of the passive node using an Exchange-aware Volume Shadow Copy Service (VSS)-based solution.
- If taking a backup of the passive node from the primary datacenter, this will require a lot of additional network traffic over the WAN link during the backup cycle.
- If you are backing up the passive node from the secondary datacenter but need to restore the data to a Recovery Storage Group (RSG) running in the primary datacenter, additional traffic would be generated. This traffic might require you to perform this restore outside of normal business hours, where in most RSG scenarios, the process can be done during normal business hours with no impact to production.
- If backing up the active node from the primary datacenter, the backup cycle has much more impact to those online production users and services whereas a backup of the passive node has no impact.
Those considerations listed above are the common ones that I run into. You may find other considerations for this type of design as it applies to your environment. At this point, you might be asking, “OK, so what should I consider as a replacement option?” For most scenarios, the requirements are typically:
- To provide high availability & redundancy in primary datacenter
- Provide Site resiliency between 2 physical datacenters with minimal downtime and configuration required
- Have a simplistic design
- Reduced cost and overhead wherever possible
- Perform very few site failovers (only when required or once/twice a year)
With that in mind, here is a common solution:
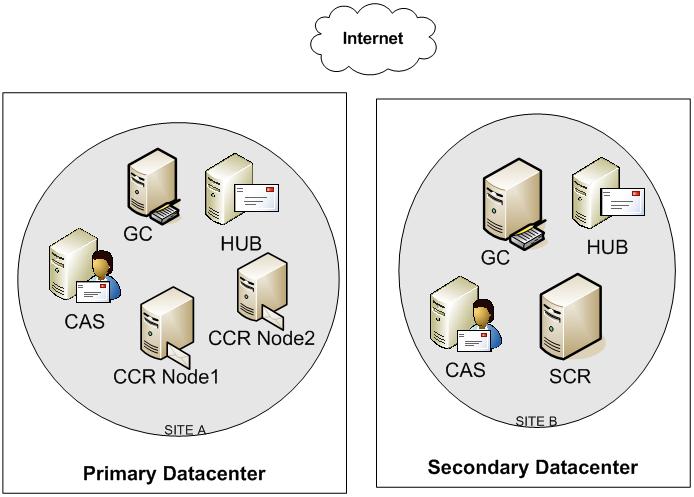
This solution puts the CCR nodes in the primary datacenter and uses SCR to replicate the data to the secondary datacenter.
SCR can provide the remote datacenter failover capability that most are looking for. That might be a better solution than trying to geo-cluster a CCR server.
Doug