
Transitioning from SMP to MPP, the why and the how
This blog post was authored by: Sahaj Saini, PM on the Microsoft Analytics Platform System (APS) team.
In this blog post, we’ll provide a quick overview of Symmetric Multi-Processing (SMP) vs. Massively Parallel Processing (MPP) systems, how to identify triggers for migrating from SMP to MPP, key considerations when moving to Microsoft Analytics Platform System (APS), and a discussion about how to take advantage of the power of an MPP solution such as APS.
Let us begin with a scenario. Emma is the Database Administrator at Adventure Works Cycles, a bicycle manufacturing company. At Adventure Works, Emma and her team are using traditional SQL Server SMP as their data warehousing solution. The company has been growing rapidly and with growing competition in the bicycle industry, the business analysts at Adventure Works Cycles would like quicker insight into their data. Emma is now facing the following challenges with the SMP deployment –
- High Data Volume and Data Growth: With increasing sales and a growing customer base, the data volume has grown rapidly to cross 10 TB.
- Longer Data Loading/ETL times: With the need to produce daily reports to management, Emma finds the current ETL speed inadequate to intake and process the increasing quantity of data flowing from other OLTP and non-relational systems.
- Slow Query Execution: Query execution times are slowing down due to the increase of data and it is becoming increasingly difficult to generate insights for daily reporting in a timely manner.
- Long Cube Processing Time: With the current cube processing time, it is difficult to meet the real-time reporting needs of the company.
In order to overcome these challenges, Emma and her team evaluate the purchase of a larger, expensive and more powerful set of server and storage hardware to their datacenter. This approach would solve their problem but only for the short-term as the data growth is expected to explode in the next 12 months. With data growth that Adventure Works is expecting to see, even the bigger and more powerful SMP solutions would hit a wall very quickly. Emma would like to see a solution that scales as their data needs grow.
What’s the difference between SMP and MPP?
Before we jump into solving Emma’s problems, let’s quickly define what SMP and MPP are. Symmetric Multi-Processing (SMP) is a tightly coupled multiprocessor system where processors share resources – single instances of the Operating System (OS), memory, I/O devices and connected using a common bus. SMP is the primary parallel architecture employed in servers and is depicted in the following image.
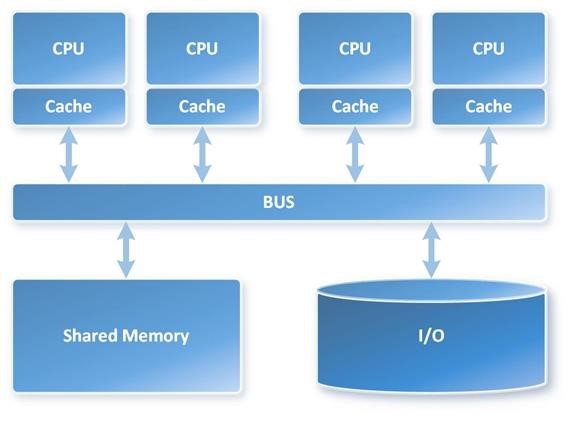
Massively Parallel Processing (MPP) is the coordinated processing of a single task by multiple processors, each processor using its own OS and memory and communicating with each other using some form of messaging interface. MPP can be setup with a shared nothing or shared disk architecture.
In a shared nothing architecture, there is no single point of contention across the system and nodes do not share memory or disk storage. Data is horizontally partitioned across nodes, such that each node has a subset of rows from each table in the database. Each node then processes only the rows on its own disks. Systems based on this architecture can achieve massive scale as there is no single bottleneck to slow down the system. This is what Emma is looking for.
MPP with shared-nothing architecture is depicted in the following image.
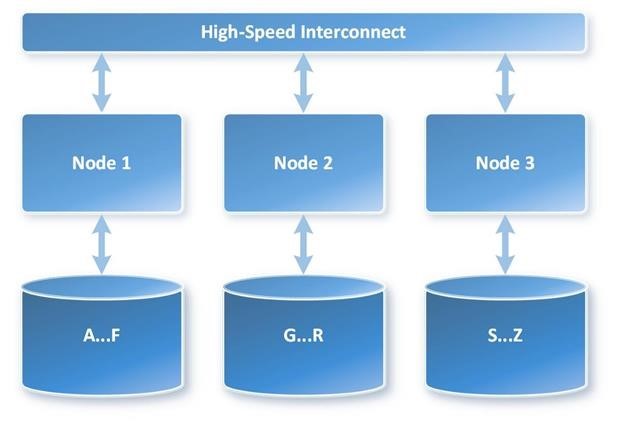
Microsoft Parallel Data Warehouse (PDW) running on a Microsoft Analytics Platform System appliance is implemented as an MPP shared-nothing architecture. It consists of one control node and storage attached compute nodes inter-connected by Ethernet and Infiniband. The control node hosts the PDW engine – the brains of the MPP system – that creates parallel query plans, co-ordinates query execution on compute nodes, and data aggregation across the entire appliance. All nodes, including control and compute, host a Data Movement Service (DMS) to transfer data between nodes.
For more details on PDW architecture, you can read the Architecture of the Microsoft Analytics Platform System post.
Transitioning to MPP
To realize the value offered by MPP, Emma and her team purchase a Microsoft APS appliance and begin transitioning to MPP. Let’s take a look at how they adapt their solution to take full advantage of APS’s shared nothing MPP architecture.
Table Design
As previously mentioned, APS is based on a shared nothing MPP architecture which means that nodes are self-sufficient and do not share memory or disks. The architecture, therefore, requires you to distribute your large tables across nodes to get the benefits of the massively parallel processing. APS allows the definition of a table as either distributed or replicated. The decision to choose one versus the other depends on the volume of data and the need for access to all of the data on a single node.
Distributed Tables
A distributed table is one where row data within the table is distributed across the nodes within the appliance to allow for massive scale. Each row ends up in a one distribution in one compute node as depicted by the image below.
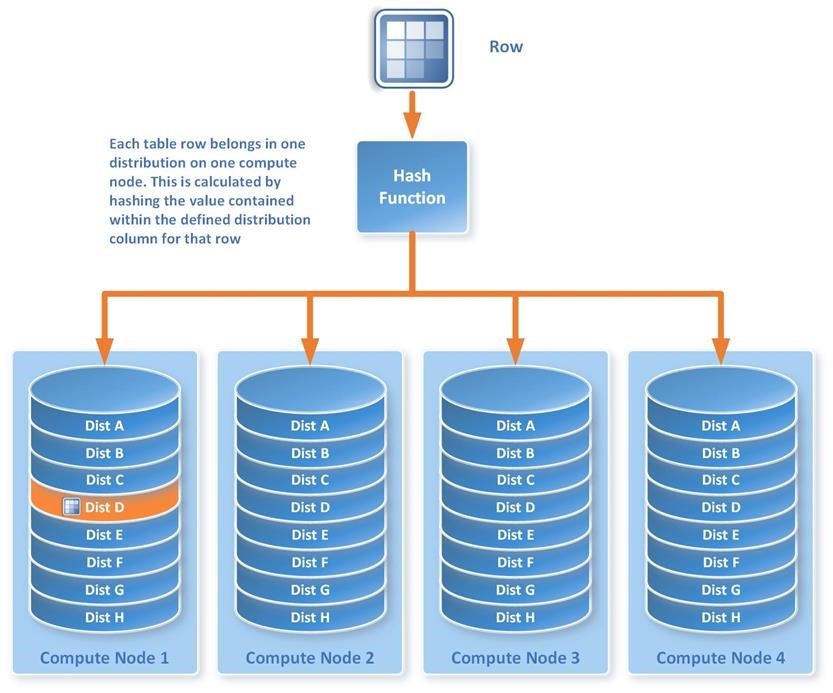
To take advantage of the distributed nature of APS, Emma modifies the large tables, typically Fact and large dimension tables, to be distributed in APS as follows:
CREATE TABLE [dbo].[FactInternetSales] ( [ProductKey] [int] NOT NULL, [OrderDateKey] [int] NOT NULL, . . [ShipDate] [datetime] NULL ) WITH ( DISTRIBUTION = HASH(ProductKey), CLUSTERED COLUMNSTORE INDEX );
As you can see, this is a typical DDL statement for table creation with a minor addition for distributed tables. Tables are distributed by a deterministic hash function applied to the Distribution Column chosen for that table. Emma chooses Product Key as the distribution column in the FactInternetSales table because of the high cardinality and absence of skew, therefore distributing the table evenly across nodes.
Replicated Tables
If all tables were distributed, however, it would require a great deal of data movement between nodes before performing join operations for all operations. Therefore, for smaller dimension tables such as language, countries etc. it makes sense to replicate the entire table on each compute node. That is to say, the benefits of enabling local join operations with these tables outweigh the cost of extra storage consumed. A replicated table is one that is replicated across all compute nodes as depicted below.
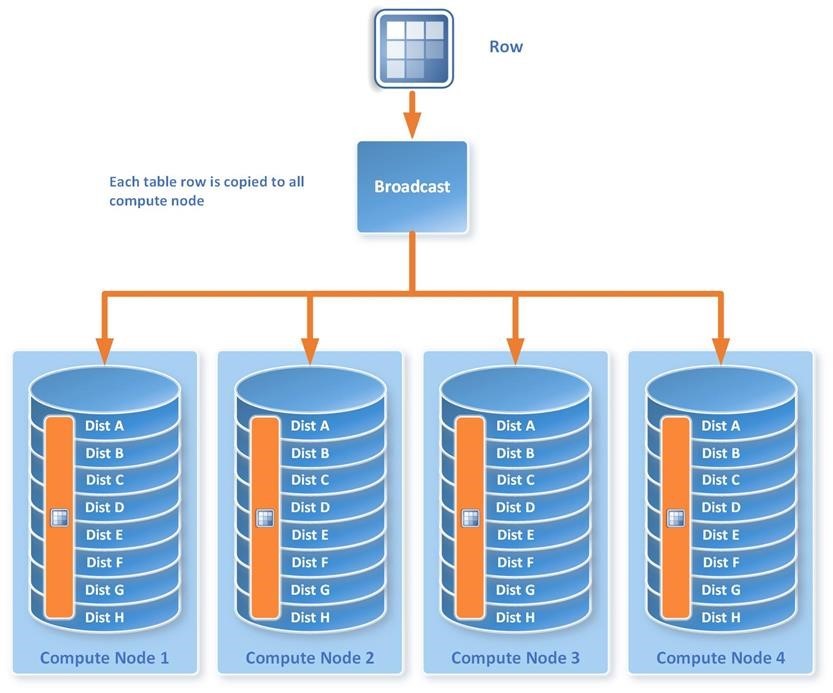
Emma designs the small tables, typically dimension tables, to be replicated as follows:
CREATE TABLE [dbo].[DimDate]( [DateKey] [int] NOT NULL, . . [SpanishDayNameOfWeek] [nvarchar](10) NOT NULL, ) WITH ( CLUSTERED COLUMNSTORE INDEX );
By appropriately designing distributed and replicated tables, Emma aligns her solution with common MPP design best practices and enables efficient processing of high volumes of data. For example, a query against 100 billion rows in a SQL Server SMP environment would require the processing of all of the data in a single execution space. With MPP, the work is spread across many nodes to break the problem into more manageable and easier ways to execute tasks. In a four node appliance (see the picture above), each node is only asked to process roughly 25 billion rows – a much quicker task. As a result, Emma observes significant improvements to the query execution time and her business can now make better decisions, faster. Additionally, Emma can grow the data warehouse to anywhere from a few terabytes to over 6 petabytes of data in by adding “scale units” to APS.
Data Loading
With SQL Server SMP, Emma and her team were using ETL processes via a set of SSIS packages to load data into the data warehouse – (1) Extracting data from the OLTP and other systems; (2) Transforming the data into dimensional format; and (3) Loading the data to target dimension or fact tables in the Data Warehouse. With increasing volumes of data, the SSIS sever in the middle becomes a bottleneck while performing transformations, resulting in slow data loading.
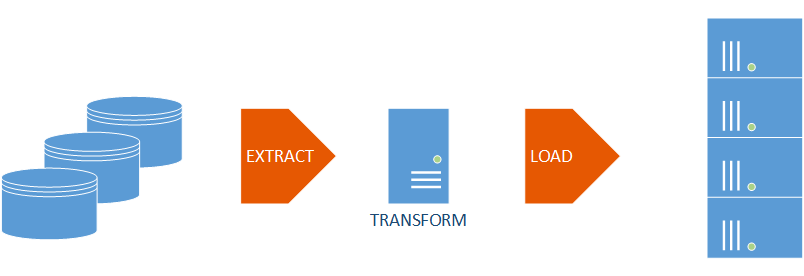
With APS, Emma and her team can use ELT instead, to Extract the data from the OLTP and other systems and Load it to a staging location on APS. Then, the data can be Transformed into dimensional format not with SSIS but with the APS Engine utilizing the distributed nature of the appliance and the power of parallel processing. In a 4-node appliance, four servers would be doing the transformations on subsets of data versus the single node SSIS server.
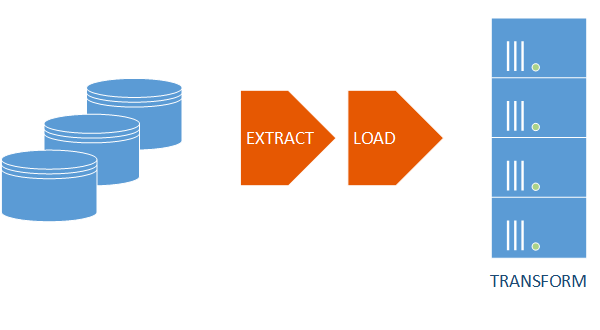
This parallel processing results in a significant boost in data loading performance. Emma can then use the Create Table As Select (CTAS) statement to create the table from the staging table as follows.
CREATE TABLE [dbo].[DimCustomer] WITH ( CLUSTERED COLUMN INDEX, DISTRIBUTION = HASH (CustomerKey) ) AS SELECT * FROM [staging].[DimCustomer];
By switching to an ELT process, Emma utilizes the parallel processing power of APS to see performance gains in data loading.
In conclusion, Emma and her team have found answers to their SMP woes with MPP. They can now feel confident handling the data volume and growth at Adventure Works with the ability to scale the data warehouse as needed. With ELT and the power of parallel processing in APS, they can load data into APS faster and within the expected time-window. And by aligning with APS’s MPP design, they can achieve breakthrough query performance, allowing for real-time reporting and insight into their data.
Visit the Analytics Platform System page to access more resources including: datasheet, video, solution brief, and more..
To learn more about migration from SQL Server to the Analytics Platform System
