I'm Certifiable
I had set a goal with my manager earlier in the year to achieve at least one more certification before the end of the year. I'm happy to say I accomplished my goal with (in his words) hours to spare. I headed down to Springfield on New Year's Eve to try my hand at the Hyper-V certification exam (test #70-652). And, as you already guessed (since I mentioned that I met my goal), I passed. I won't say it was easy, though. It made me realize that there are still some things about Hyper-V and Virtual Machine Manager (VMM) that I don't fully understand. What's that mean to you? It means you can expect to see more posts here regarding virtualization! (Not a bad thing at all, right?)
I'm actually going to start by attempting to explain some features in Microsoft's Hyper-V product. Because I received an e-mail about this on Monday (pretty interesting timing, eh?), I'm going to start with clustering in Hyper-V.
What is clustering?
Clustering simply means tying some servers together so that they are able to share the load of an application (this type of clustering is called Network Load Balancing (NLB)) or pick up in the event another server in the cluster fails (this type of clustering is called Failover Clustering). While both of these are lumped into the category of "clusters," they are very different and serve very different purposes.
Network Load Balancing
Network Load Balancing (NLB) is used to provide high availability for stateless network applications. You can tie two or more servers together in order to provide more processing power than a single server is able to provide. The NLB cluster acts as a single server (from the perspective of the user), automatically managing the user load to ensure that incoming requests are directed to an individual server within the cluster which can process the request. This can be very helpful in scenarios involving an application with heavy user load or an application which consumes a lot of resources per user. It is important to note that this only works with stateless applications. According to Wikipedia, stateless applications are defined as applications which have "relatively small data sets that rarely change (one example would be web pages), and do not have long-running-in-memory states." It also provides failover capabilities. In the event that one of the servers in the cluster fails, the load will be distributed among the remaining machines. Once the failed server is repaired, it can be brought back online and resume servicing its share of the user load.
Failover Clustering
Unlike NLB, failover clustering does not distribute the load among the members of the cluster. Failover clustering is designed to allow one or more servers to be on standby in the event that a server fails. Much like an understudy in theater, the other servers in the cluster wait to go on in the event that something happens to "the star." (Unlike the theater, however, you don't have to worry about the understudy servers trying to do harm to "the star" in order to get their moment in the spotlight.)
Clustering and Virtualization
Virtualization opens up whole new possibilities in the realm of clustering. It also introduces complexities and subtleties which require extra steps during the planning process. Because you can cluster the host machines (the servers actually running Hyper-V and hosting virtual servers) or cluster the individual virtual servers (or even a combination of both!), planning can be tricky. In order to understand these subtleties, we need to delve a little deeper into how clusters work.
Once multiple servers have been turned into a cluster, the individual servers in the cluster are monitored by one another using a "heartbeat." A heartbeat is simply a ping to the individual servers to make sure they are still responsive. This is how the other servers know if/when a machine within the cluster has gone offline. This heartbeat doesn't tell the cluster that all applications on the server are still functioning -- just that the server is still online and responsive. Since a virtual machine is, for all intents and purposes, an application, clustering the physical host servers may mean that a virtual machine can fail and the cluster won't be aware of the failure. If the host servers are running other applications/services which are the reason for clustering, this might not be a problem. If the virtual machine was the reason for clustering, this might be disaster. Confused yet? Let's take a look at a picture.
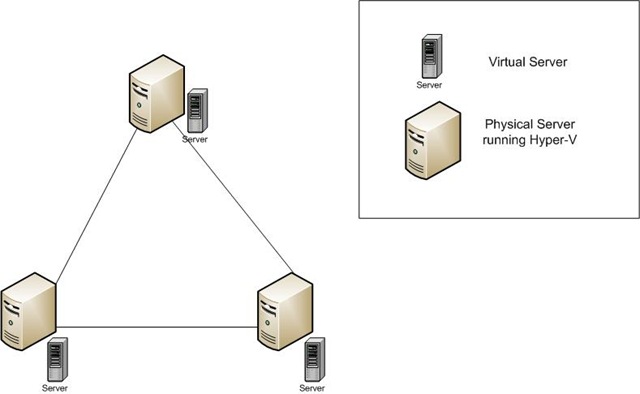
In this diagram, the lines represent a cluster. We have three physical machines, all running a single virtual machine, clustered together. The heartbeat will travel those lines, meaning that if one of the physical servers fails, the other physical servers will know about it and step up to take its place (in a failover cluster) or stop directing traffic to the server (in a NLB scenario). But, what if one of the virtual machines fail? There's no heartbeat there (because the virtual machines are not clustered together), so the cluster is unaware of what the status of the virtual machine is. Again, if the virtual machine is not the reason for clustering, then you'll be fine. But, if it is, this is clearly not going to work.
If we change this up a bit, let's see what happens:
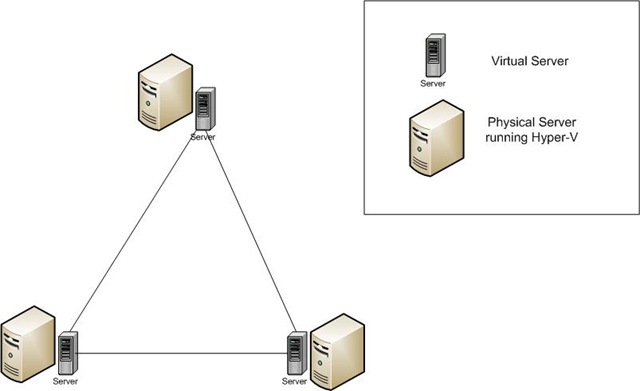
Now, you can see I have clustered the virtual machines, rather than the physical machines. If one of the virtual machines becomes unresponsive, the other virtual machines will step in and take over for the failed server (in a failover cluster). The interesting thing here (and one of the subtleties I mentioned earlier) is in regard to the physical server. In our last example, the heartbeat only monitored the physical machine. Thus, a failed VM would go undetected. In this instance, the heartbeat is only monitoring the virtual machines. But, what happens if one of the physical machines fails? The virtual machine hosted on that server would become unresponsive, triggering one of the other servers to step up and take its place. Thus, clustering virtual machines in a Failover Cluster does, in actuality, failover in the event of a catastrophe on either the virtual or physical machine!
Does this mean that clustering the virtual machines is always the way to go (since it essentially monitors both physical and virtual machines)? No. It very much depends on the situation and what you are really trying to accomplish with your cluster.
Clearly, there is a lot more to discuss regarding how clustering works with virtualization, but this is a good introduction to the concepts. I'll continue to delve into clustering with Hyper-V in future posts!
In the meantime, want to find out how easy it is to actually set up a failover cluster in Server 2008? Check out the TechNet lab.
Enjoy!
Technorati Tags: Hyper-V,Server 2008,clustering,NLB,Failover